配置Interpreter 有以下2种方式(通常情况下我们需要结合这两种配置方式):
- 在Interpreter 页面进行全局配置
- 在Note页面进行Note级别的配置
Interpreter 页面配置
Interpreter 页面的配置是全局的,会影响所有的用户的所有Note。所以在Interpreter页面适合配置那些对于全局用户来说都是一样的配置,比如 FLINK_HOME,HADOOP_CONF_DIR, HIVE_CONF_DIR, zeppelin.pyflink.python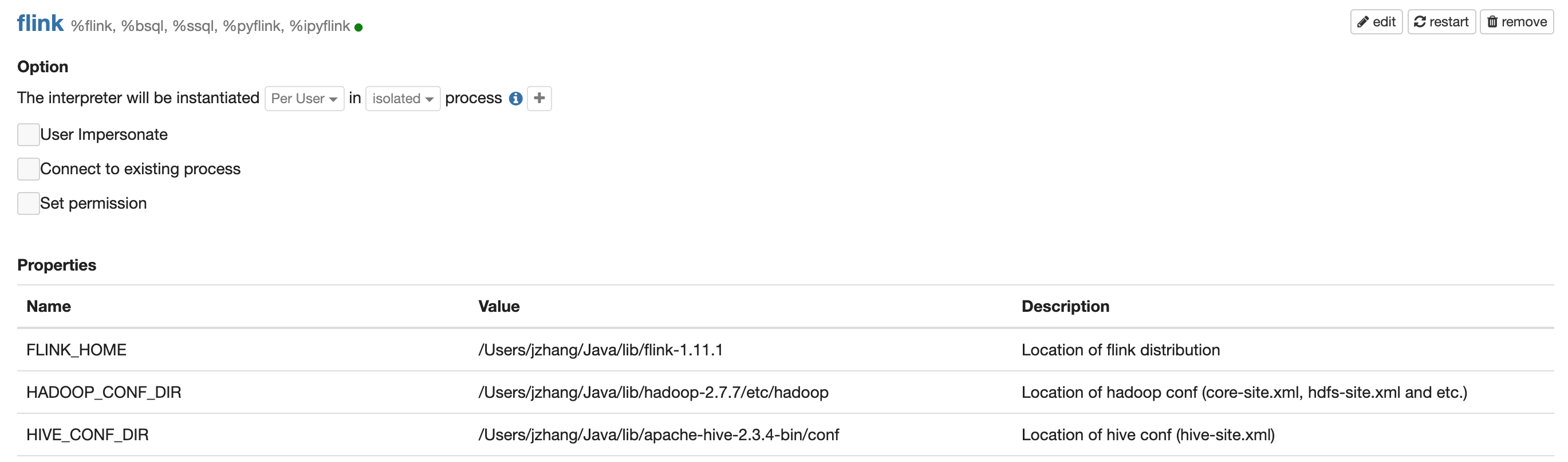
Note级别配置
Note 级别的配置只有在当Interpreter binding模式选择 Isolated Per Note的时候才起作用。Note 级别的配置一般放在每个Note的第一个Paragraph,是通过一个特殊的 Inline Configuration Interpreter (%flink.conf) 来实现的。
一般每个Note都有自己对应的Job和场景,我们需要对每个Note做特殊的配置,比如 flink.execution.packages, flink.udf.jars, flink.yarn.appName 等等。Note级别的配置优先级比 Interpreter的全局配置要高,所以比如你可以在Note配置 FLINK_HOME 来覆盖Interpreter页面里配置的 FLINK_HOME。下图是一个简单的例子
配置选项
这边列举一些场景的配置选项,除了这些Zeppelin支持所有的Flink配置选项,可以参考这边 https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/config.html
| Name | Default Value | Description |
|---|---|---|
| FLINK_HOME | Flink 安装目录 | |
| HADOOP_CONF_DIR | Hadoop 配置文件目录 (Yarn 模式下需要配置) | |
| HIVE_CONF_DIR | Hive 配置文件目录 (集成Hive需要配置) | |
| flink.execution.mode | local | loca | remote | yarn | yarn-application |
| flink.execution.remote.host | remote模式下JobManager的地址 | |
| flink.execution.remote.port | remote模式下JobManager的Rest 端口 | |
| flink.jm.memory | 1024 | JobManager的分配内存 (只在yarn, yarn-application 模式下起作用) |
| flink.tm.memory | 1024 | TaskManager的分配内存 (只在yarn, yarn-application模式下起作用) |
| flink.tm.slot | 1 | TaskManager的slot数 (只在yarn, yarn-application模式下起作用) |
| local.number-taskmanager | 4 | TaskManager的slot数 (只在Local模式下起作用) |
| flink.yarn.appName | Zeppelin Flink Session | Yarn app name (只在yarn, yarn-application模式下起作用) |
| flink.yarn.queue | Yarn queue (只在yarn, yarn-application模式下起作用) | |
| zeppelin.flink.uiWebUrl | flink web ui的链接模板,一般用在你想用yarn的proxy url 或者 启用knox的时候你想用yarn app的knox url,比如https://knox-server:8443/gateway/cluster-topo/yarn/proxy/ application_1626074007058_0105 / ,这时候,你可以设置这个参数为 https://knox-server:8443/gateway/cluster-topo/yarn/proxy/{{applicationId}}/ |
|
| flink.udf.jars | flink udf的jar包,多个jar包以逗号间隔,可以是本地路径也是可以是hdfs路径 | |
| flink.udf.jars.packages | flink udf 的package搜索路径,默认情况下 flink.udf.jars 里所有的 | |
| flink.execution.jars | 第三方依赖的jar包,多个jar包之间用逗号间隔 | |
| flink.execution.packages | 第三方依赖的packages,多package之间用逗号间隔 | |
| zeppelin.flink.scala.color | true | scala shell的输出是否是彩色输出 |
| zeppelin.flink.enableHive | false | 是否启动HiveCatalog |
| zeppelin.flink.hive.version | hive版本(只在1.10版本需要指定,1.11之后不需要指定) | |
| zeppelin.flink.module.enableHive | false | 是否启用HiveModule,启用HiveModule之后就会优先选择Hive UDF |
| zeppelin.flink.printREPLOutput | true | 是否打印出Scala Shell 的输出 |
| zeppelin.flink.maxResult | 1000 | SQL结果最大输出行数 |
| zeppelin.pyflink.python | python | python可执行文件路径,默认是PATH里的python |
| flink.interpreter.close.shutdown_cluster | true | 是否在重启interpreter的时候杀掉flink cluster |
| zeppelin.interpreter.close.cancel_job | true | 是否再重启interpreter的时候cancel正在running的job |
| zeppelin.flink.concurrentBatchSql.max | 10 | Batch SQL 的最大并发数 |
| zeppelin.flink.concurrentStreamSql.max | 10 | Streaming SQL 的最大并发数 |
视频教程

钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
