了解Flink on Zeppelin的架构有助于你分析开发过程中碰到的问题以及如何更好的使用Flink on Zeppelin。
Zeppelin 架构
首先我们来了解下 Zeppelin的架构, Zeppelin 主要分3层。
- Web前端
- Zeppelin Server
- Interpreter
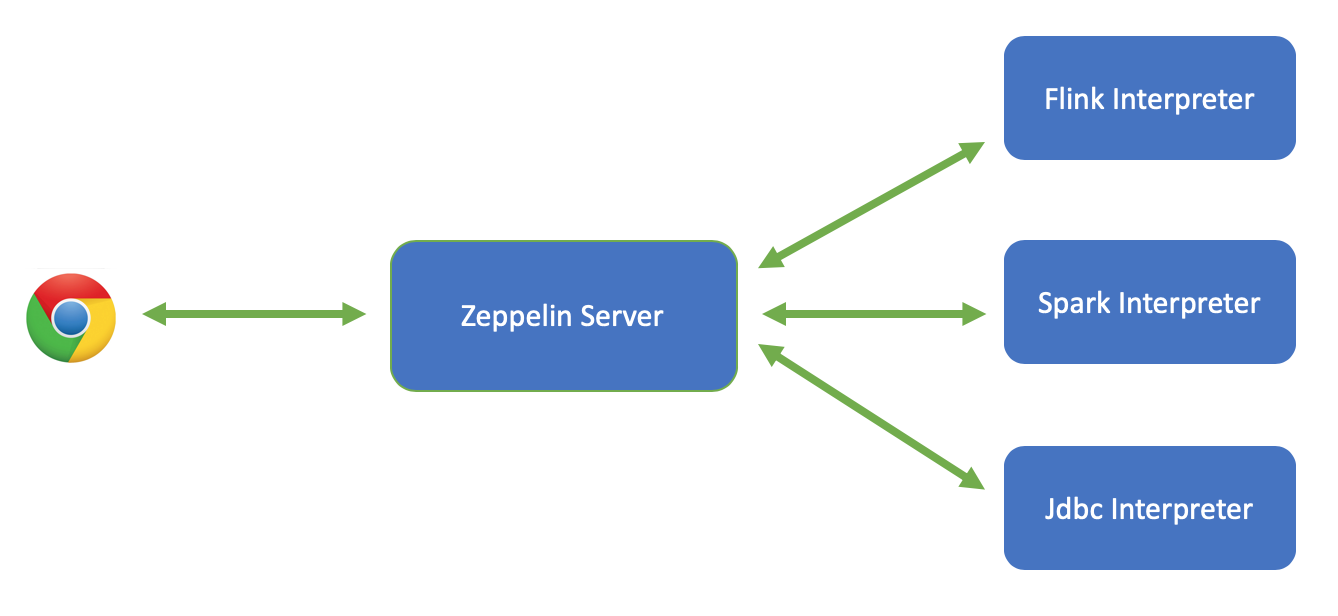
- Zeppelin前端负责前端页面的交互,通过Rest API 和WebSocket的方式与Zeppelin Server进行交互。
- Zeppelin Server是一个Web server,负责管理所有的note,interpreter 等等,Zeppelin Server不做具体的代码执行,会交给Interpreter来执行代码
- Interpreter 是一个独立的进程,负责具体前端用户提交的代码的执行(比如Spark Scala代码或者SQL代码等等)。Zeppelin Server与 Interpreter 之间是通过thrift 来进行通信,而且是双向通信。Zeppelin支持目前大部分流行的大数据引擎,上图只展示了其中3种比较常用的引擎:Flink,Spark,Jdbc
Zeppelin Server是独立的进程,进程日志在logs目录下的 zeppelin-{user}-{host}.log, 每个Interpreter也是一个独立的进程,进程日志是 logs目录下的 zeppelin-interpreter-{interpreter}-*.log,(如果是yarn interpreter 模式,那么interpreter log是对应的yarn application的AM log) 所以如果碰到任何问题可以先去这两个log文件里去查找线索。
Flink on Zeppelin 架构
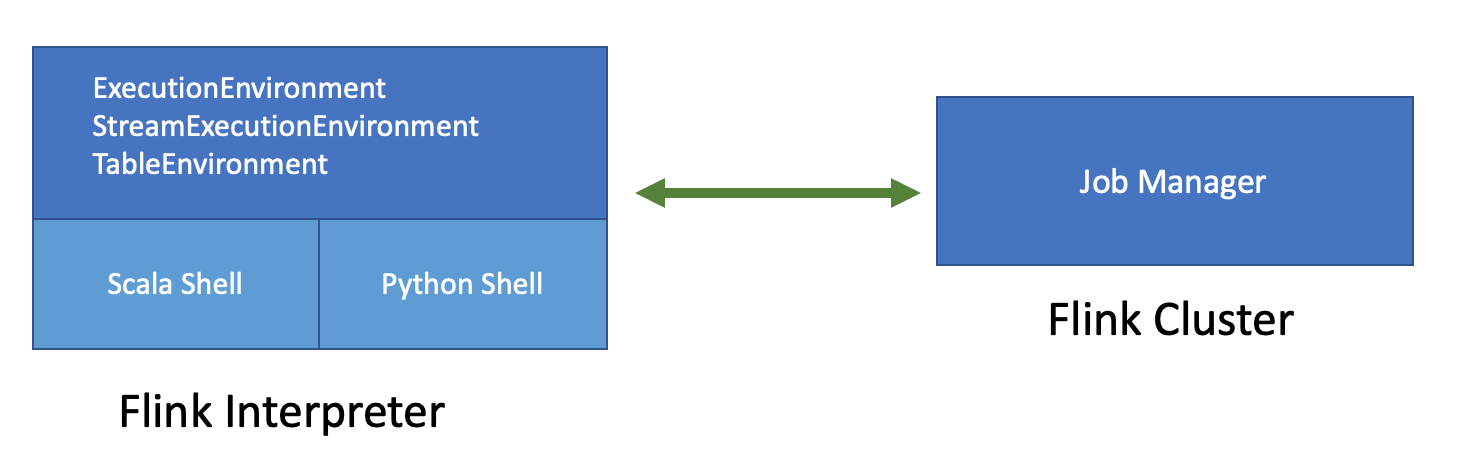
上图是Flink on Zeppelin的架构,左边的Flink Interpreter可以理解成Flink的客户端,负责Flink Job的编译,提交和管理(比如Cancel Job,记录Checkpoint等等)。右边的Flink Cluster就是真正运行Flink Job的地方,可以是一个MiniCluster(local 模式),Standalone Cluster (remote模式),Yarn Session Cluster (yarn 模式)。
Flink Interpreter内部会有2个重要的组件:Scala Shell,Python Shell
- Scala Shell 是整个Flink Interpreter的入口,ExecutionEnvironment,StreamExecutionEnvironment 以及所有类型的TableEnvironment都是在Scala Shell里创建,Scala shell负责Scala代码的编译和执行。
- Python Shell 是PyFlink的入口,负责Python代码的编译和执行。
视频教程

钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
