在Zeppelin中你有4种方式使用或者定义UDF:
- 在Zeppelin中直接写Scala UDF代码
- 在Zeppelin中直接写PyFlink UDF代码
- 本地写UDF代码,用SQL 创建 UDF
- 本地写UDF代码,使用 flink.udf.jars 来指定含有udf的jar
Scala UDF
%flinkclass ScalaUpper extends ScalarFunction {def eval(str: String) = str.toUpperCase}btenv.registerFunction("scala_upper", new ScalaUpper())
在Zeppelin定义Scala UDF 非常方便,如上图你只要定义UDF的class,然后在btenv中注册这个UDF就可以了(你也可以在stenv中注册这个UDF,因为btenv和stenv其实是共享同一个Catalog)。注册完这个UDF后,你既就可以 %flink.bsql 中使用,也可以在 %flink.ssql 中使用,甚至可以在 %flink.pyflink, %flink.ipyflink 中使用,因为同理 %flink, %flink.bsql,%flink.ssql,%flink.pyflink, %flink.ipyflink 是共享同一个Catalog。
PyFlink UDF
%flink.pyflinkclass PythonUpper(ScalarFunction):def eval(self, s):return s.upper()bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))
在Zeppelin定义Python UDF 也非常方便(和定义Scala UDF类似),如上图你只要定义UDF的class,然后在bt_env 中注册这个UDF就可以了(你也可以在 st_env 中注册这个UDF,因为 bt_env 和 st_env 其实是共享同一个Catalog)。注册完这个UDF后,你既就可以 %flink.bsql 中使用,也可以在 %flink.ssql 中使用,甚至可以在 %flink 中使用,因为同理 %flink, %flink.bsql,%flink.ssql,%flink.pyflink, %flink.ipyflink 是共享同一个Catalog。
SQL 创建 UDF
一些简单的UDF可以在Zeppelin里直接写,但是如果是一些复杂的UDF,那么就比较适合在IDE里写,然后在Zeppelin中创建注册,如下图:
%flink.ssqlCREATE FUNCTION myupper AS 'org.apache.zeppelin.flink.udf.JavaUpper';
但这种方式有个前提条件是这个udf对应的jar必须要在 CLASSPATH 里,所以你要先配置 flink.execution.jars 来把这个udf的jar放到 CLASSPATH 里,如下图:
flink.execution.jars /Users/jzhang/github/flink-udf/target/flink-udf-1.0-SNAPSHOT.jar
flink.udf.jars
以上3种方式都有一定的局限性。
- 在Zeppelin里写Scala UDF或者Python UDF适合写比较简单的UDF,逻辑一复杂就不适合在Notebook环境里写(因为Notebook没有传统IDE那么好的代码管理能力)。
- 如果你的Zeppelin是多租户使用的,那么每个用户在跑Flink Job前都要运行含有注册 Scala UDF 和 Python UDF 相对应的Paragraph,或者是跑 Create FUNCTION 那些SQL语句,比较复杂,也难以管理。
所以如果你有很多UDF,或者UDF逻辑比较复杂,你又不想每次都去注册这些UDF,那么这种情况下你就可以使用 flink.udf.jars
- 首先在IDE里创建你自己的flink udf项目,编写你的UDF,这里有一个范例
https://github.com/zjffdu/flink-udf
- 接下来用 flink.udf.jars 来指定你的flink udf项目的jar包
Zeppelin会扫描这个jar包,然后检测出所有的UDF,并且自动注册这些UDF,UDF的名字就是class名字。比如下面是我使用了上面的jar后 show functions 的结果flink.udf.jars /Users/jzhang/github/flink-udf/target/flink-udf-1.0-SNAPSHOT.jar
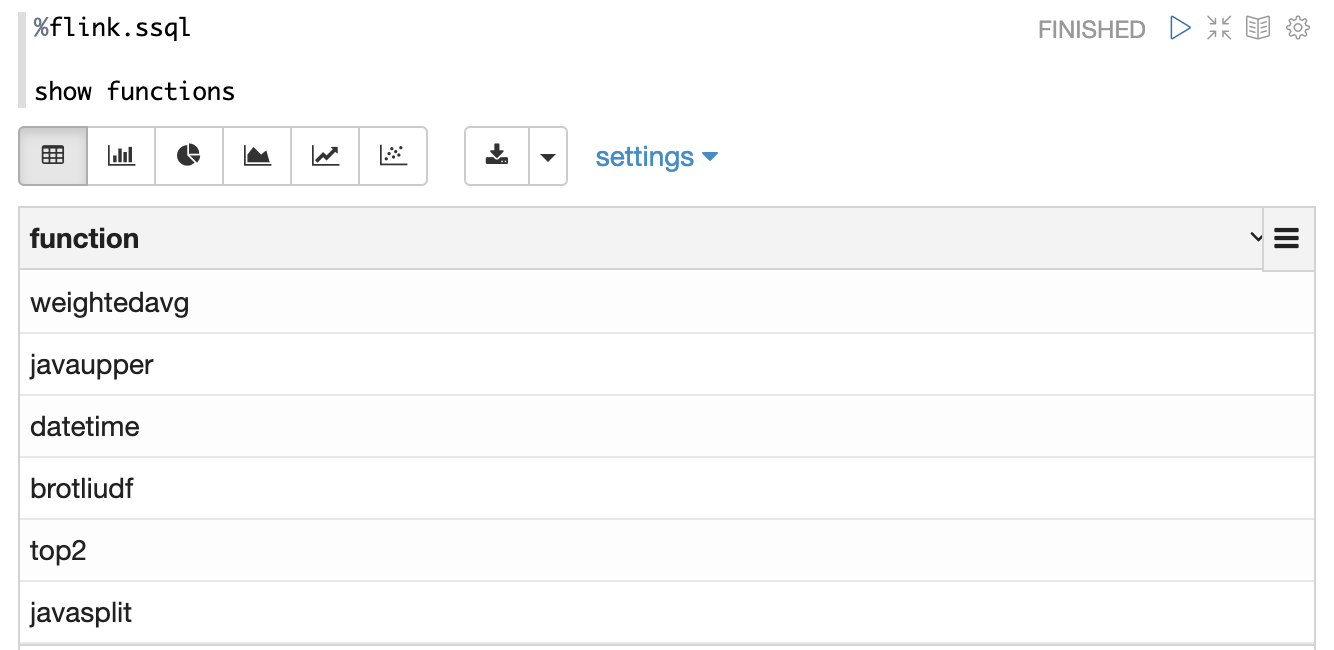
默认情况下 Zeppelin会扫描这个jar包里的所有的class,如果jar包过大可能会导致性能问题。因为通常情况下这个jar包里会含有你创建的UDF所依赖的第三方jar包,而这些jar包是不需要扫描的。所以这种情况下你可以设置 flink.udf.jars.packages 来指定扫描的package,这样可以减少扫描的class数目,比如flink.udf.jars.packages org.apache.zeppelin.flink.udf
视频教程
Scala UDF

Python UDF
UDF via flink.udf.jars
钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
