Scala 是 Flink on Zeppelin默认支持语言(%flink), 也是整个Flink Interpreter内部实现的入口(Flink Interpreter 内部会创建Flink Scala Shell, 在这个Flink Scala 里会创建 Flink的各种 Environment 变量(包括ExecutionEnvironment,StreamExecutionEnvironment 等等)。你在Zeppelin上写的scala代码就会提交到这个Flink Scala Shell里去执行。Zeppelin已经为你创建了下面7个变量 (不要自己再创建这些Environment)
- senv (StreamExecutionEnvironment),
- benv (ExecutionEnvironment)
- stenv (StreamTableEnvironment for blink planner)
- btenv (BatchTableEnvironment for blink planner)
- stenv_2 (StreamTableEnvironment for flink planner)
- btenv_2 (BatchTableEnvironment for flink planner)
- z (ZeppelinContext)
WordCount (Scala 版)
这里有2个WordCount的例子,一个是Batch模式,一个是Streaming 模式,你不用创建benv,senv,这些变量已经为你创建好了。
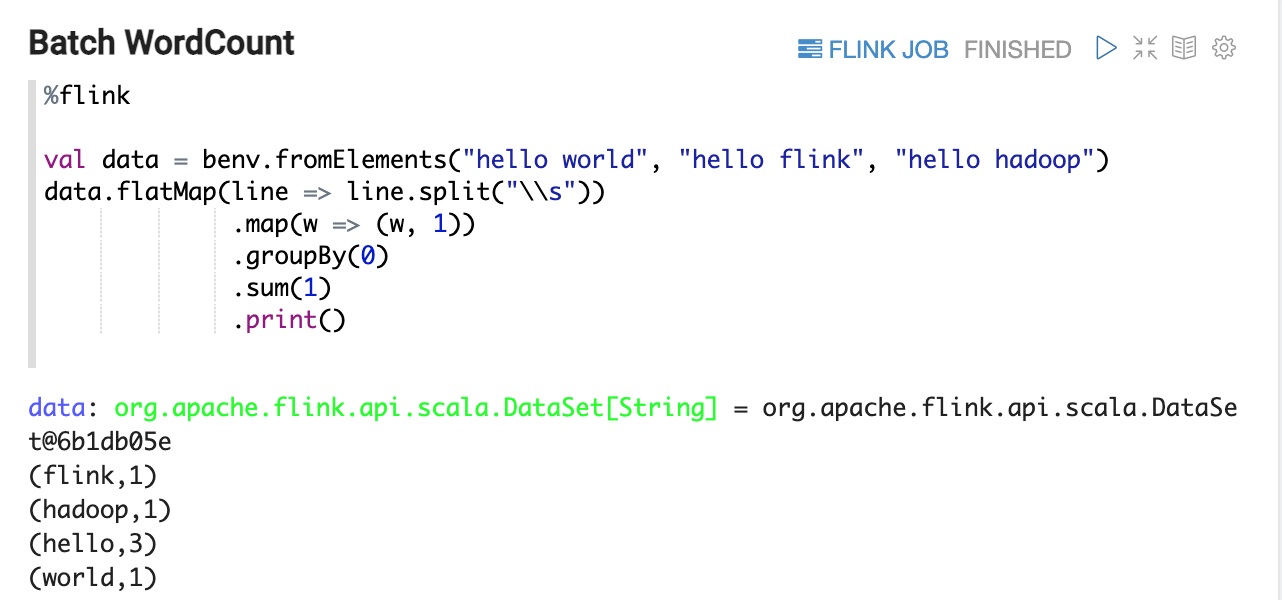
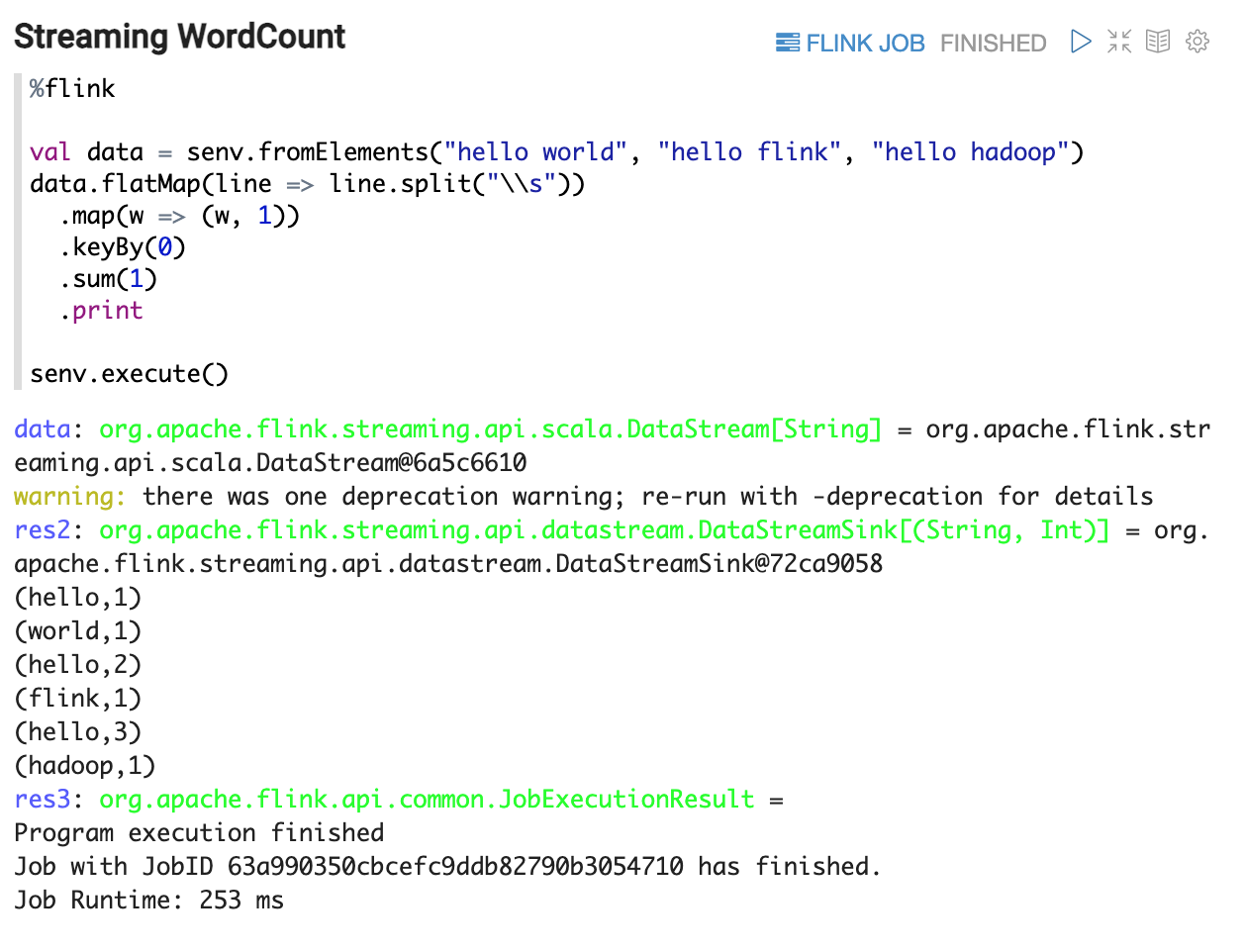
Scala 段落执行顺序
同一时间只能有一个Scala段落执行,Zeppelin是安装FIFO的顺序来执行Scala段落。所以如果你的一个Scala段落里正在跑一个Streaming作业的话,另外一个Scala段落只能等待(处于PENDING状态)。
Code Completion
Zeppelin里的Flink Scala Shell是支持code completion的,按tab键就可以显示当前环境下的候选方法名,如下图: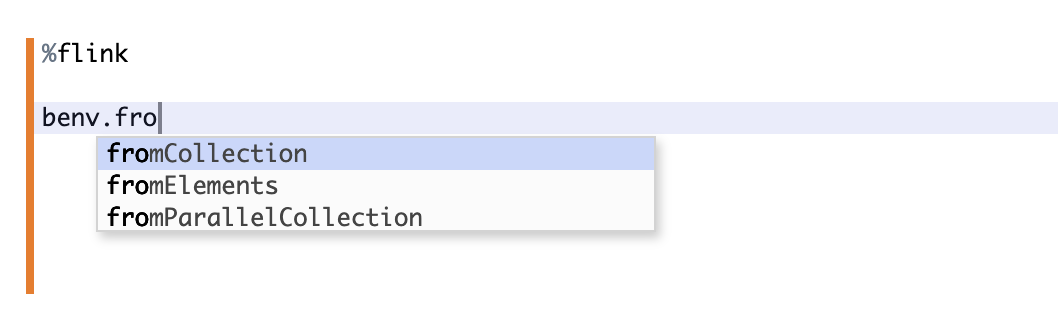
ZeppelinContext
ZeppelinContext(变量名为z) 是在Flink Scala环境下创建的一个提供一些高级用法的Class。比较实用的方法是z.show。下面有3个例子分别展示了如何用z.show来展示DataSet,Batch Flink Table 以及 Stream Flink Table。
z.show(DataSet)

z.show(Batch Table)
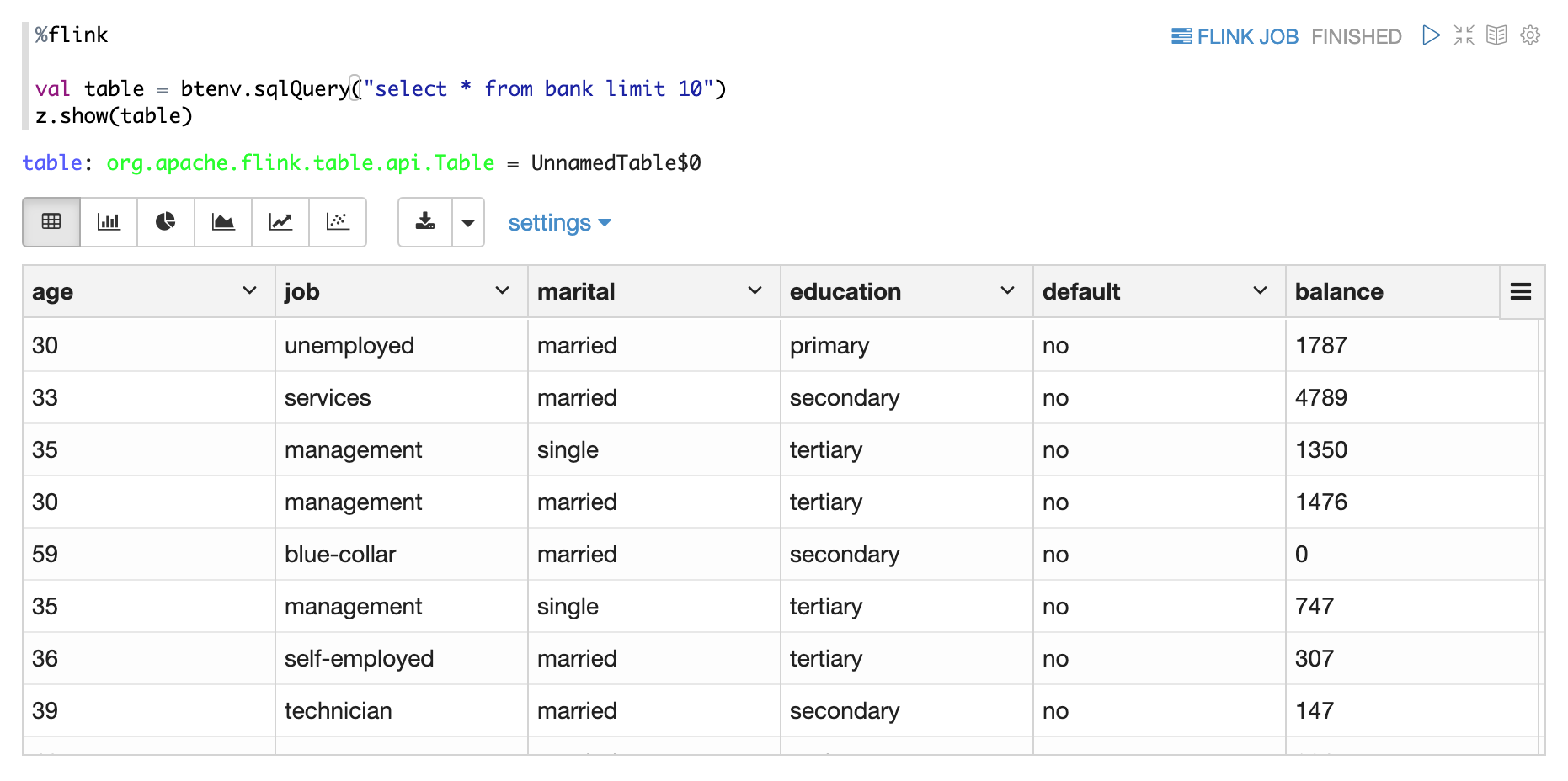
z.show(Stream Table)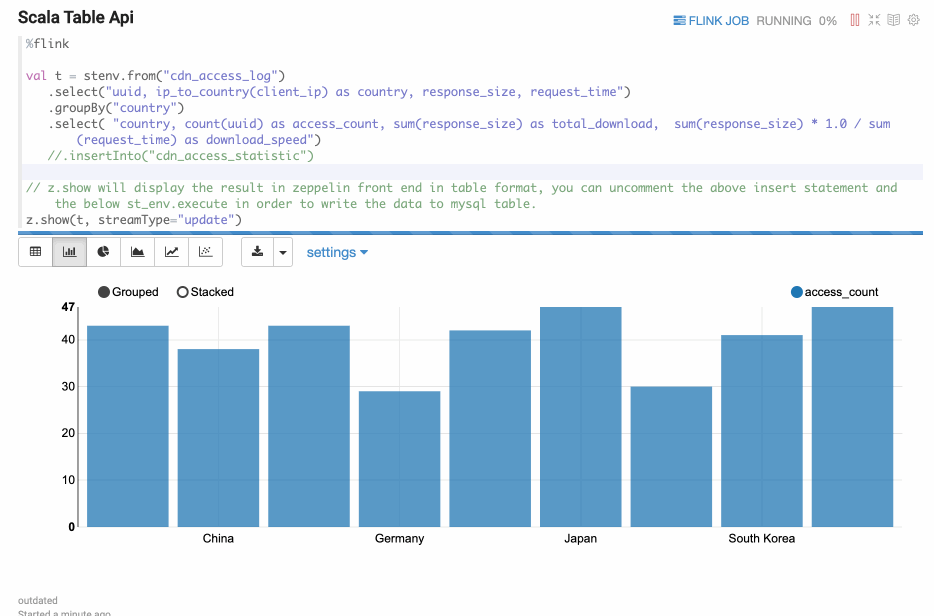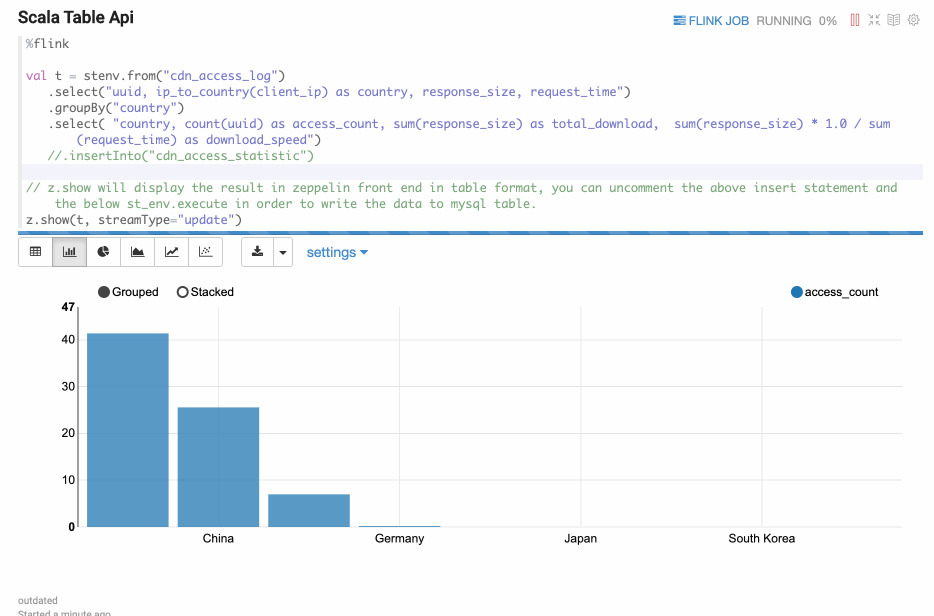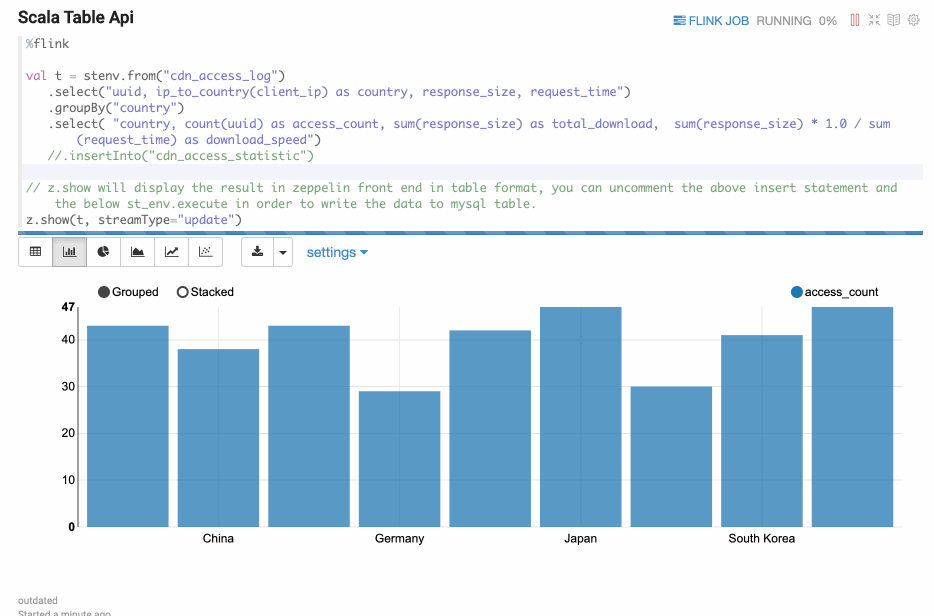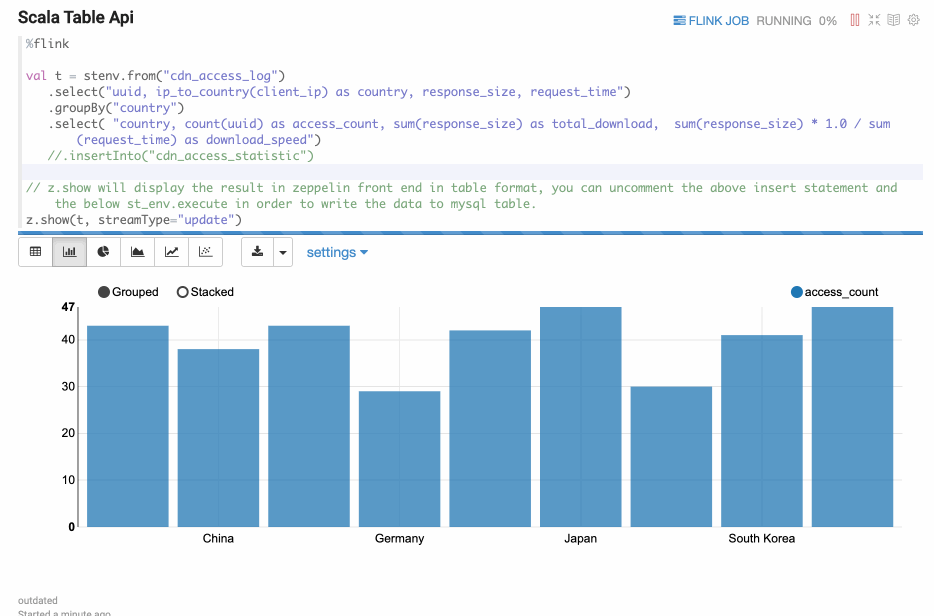
局限性
不能在Flink Job中使用case class
由于Flink本身的限制,目前无法在Flink Scala shell中定义case class,然后在Flink Job中使用这个case class。
比如下面的例子会碰到这样的错误。
不过如果你真的想使用case class,那么你可以在IDE以定义这个case class,build出对应的jar,然后用flink.execution.jars 来指定这个jar的这种方式来引入这个case calss。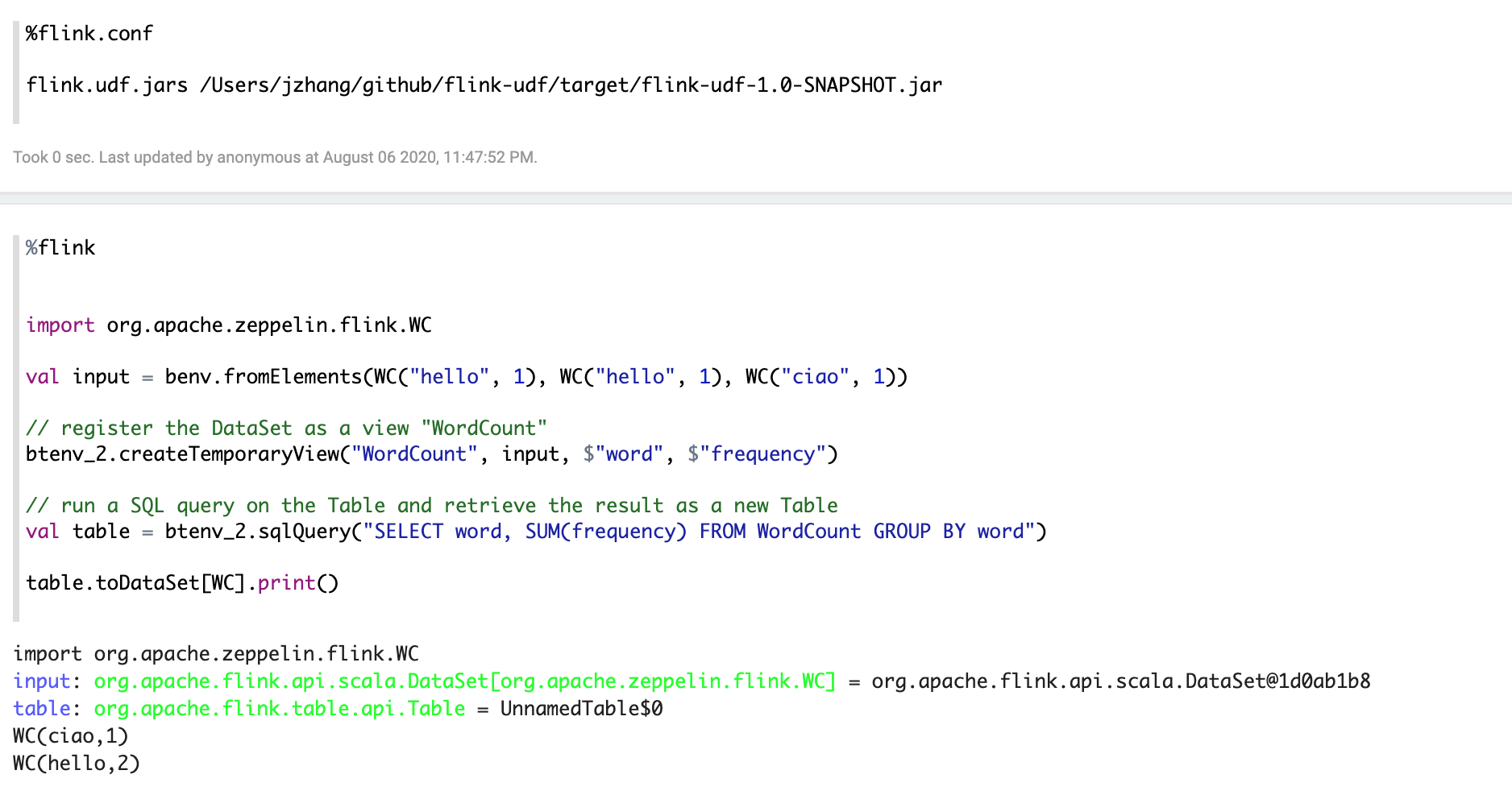
视频教程

钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
