**# 如果你是使用 Flink 1.11 以上版本,建议用 **[**yarn-application **](https://www.yuque.com/jeffzhangjianfeng/gldg8w/wfbu5c)**模式,如果是Flink 1.10 那么可以使用这里的Interpreter Yarn 模式 #**<br /> 首先需要声明的是这里的Interpreter Yarn 模式和 Flink的Yarn模式不是一个概念。Flink的Yarn模式是指把Flink集群运行在Yarn环境里,而这里的 Interpreter Yarn 模式是指把 Flink Interpreter 进程运行在 Yarn 环境里。<br /> 那为什么我们要引入Interpreter Yarn 模式呢?因为默认情况下 Flink Interpreter 进程和 Zeppelin 是运行在同一台机器上。如果我们是采用 Isolated Per Note 模式,每个Note就会起一个 Flink Interpreter 进程,会对Zeppelin那台机器造成很大的资源压力。Interpreter Yarn 模式就是把 Flink Interpreter进程跑在Yarn环境里,从而减轻 Zeppelin 那台机器的压力。
架构
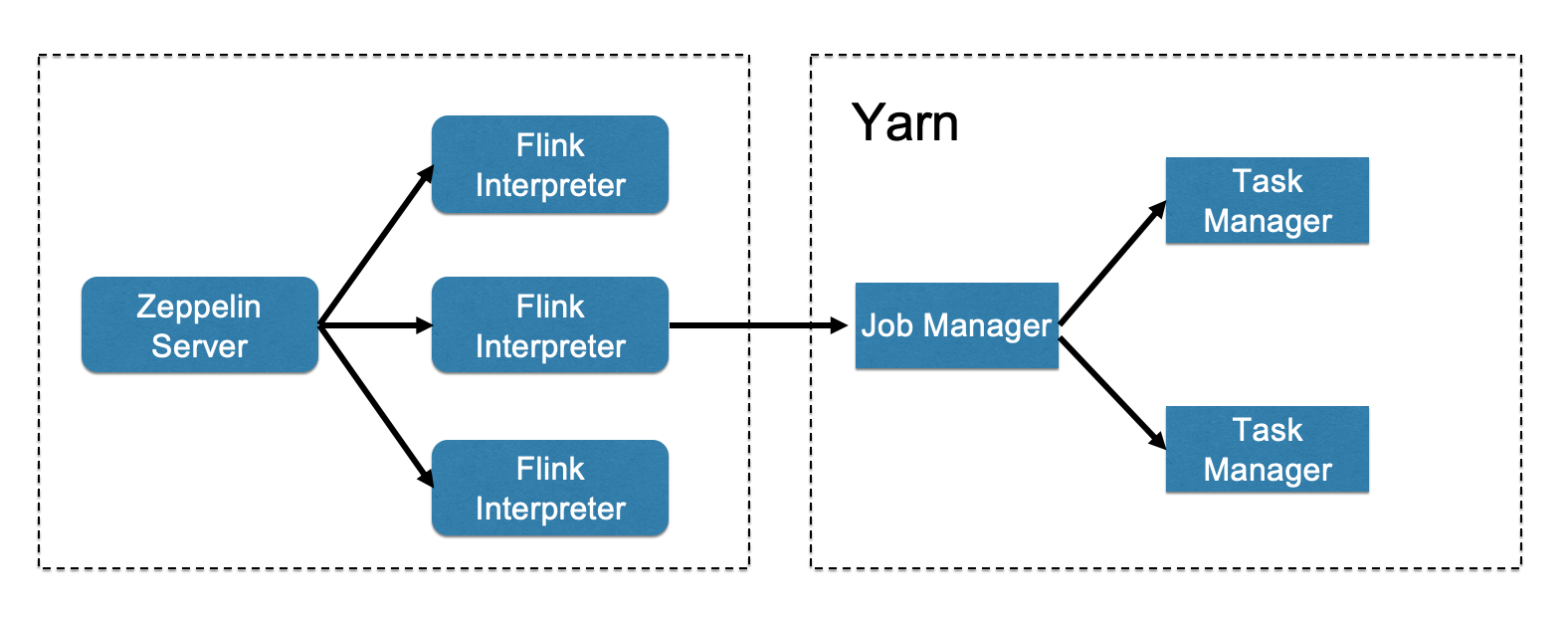
- 这是默认的进程布局图
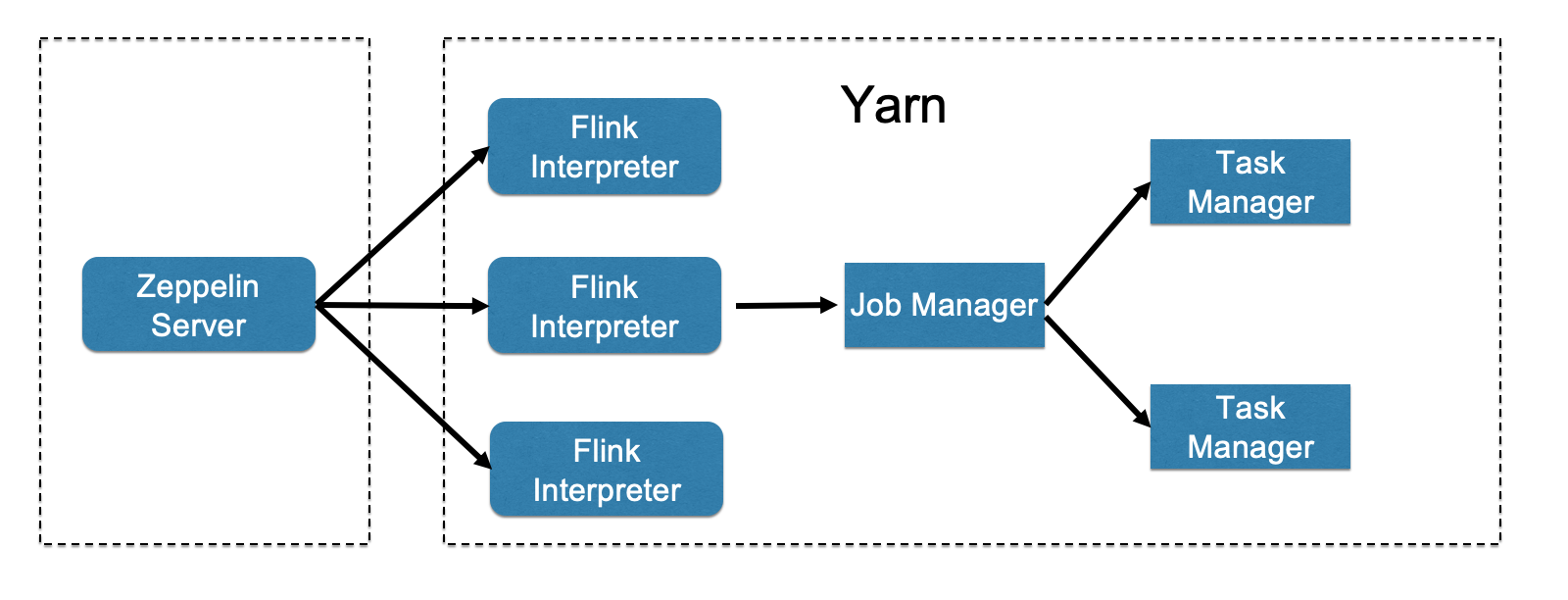
- 这是Yarn Interpreter 模式的进程布局
配置
要启动Yarn Interpreter模式,需要做以下几点配置:
- 安装hadoop client (hadoop 2和3都支持)
- 把 $HADOOP_HOME/bin放到环境变量 PATH 里. 因为Zeppelin会调用命令hadoop classpath 获取所有hadoop相关的jar,然后放到CLASSPATH 里
- 在 zeppelin-env.sh 中配置 USE_HADOOP 为true,以及配置 HADOOP_CONF_DIR
除了这几个配置,你还需要可以配置下面这些参数来控制 interpreter process
| Name | Default Value | Description |
|---|---|---|
| zeppelin.interpreter.yarn.resource.memory | 1024 | memory for interpreter process, unit: mb |
| zeppelin.interpreter.yarn.resource.cores | 1 | cpu cores for interpreter proces |
| zeppelin.interpreter.yarn.queue | default | yarn queue name |
视频教程

钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
