在Zeppelin中有2种不同模式的SQL可以使用
- %flink.ssql (Streaming SQL,用StreamTableEnvironment 来执行 SQL)
- %flink.bsql (Batch SQL, 用BatchTableEnvironment 来执行SQL)
支持的SQL 语句类型
- DDL(Data Definition Language)
- DML(Data Manipulation Language)
- DQL(Data Query Language)
- Flink 定制语句(比如set,help等等)
Zeppelin SQL 重要 Feature
Zeppelin的SQL开发环境和 Flink自带的Sql-Client类似,但是提供了更多实用的feature。
同时支持Batch SQL 和 Streaming SQL
用过Sql-client的话,你就会知道你要么使用Batch Sql 要么使用 Streaming Sql, 而在Zeppelin中你可以同时使用两种不同场景的Sql。%flink.ssql 用来执行 Streaming Sql, %flink.bsql 用来执行 Batch Sql。
多语句支持
你可以在Zeppelin 的每一个Paragraph中写多条SQL语句,每条SQL语句以分号间隔。按顺序从上到下执行。
Comment支持
你可以在SQL中穿插comment,有2种comment
- 以 — 开头的单行comment
- / / 包围的多行comment

Job并行度支持
你可以设置每个Paragraph的local properties:parallelism 来控制Flink SQL Job的并行度。
Multiple insert支持
有些情况下你会有多条Insert语句读同一个Source,但是会写到不同的Sink,默认情况下每条SQL语句都会独立运行一个Flink Job, 如果你想合并多条Insert语句到同一个Flink Job的话,你就需要设置 runAsOne 为true,如下图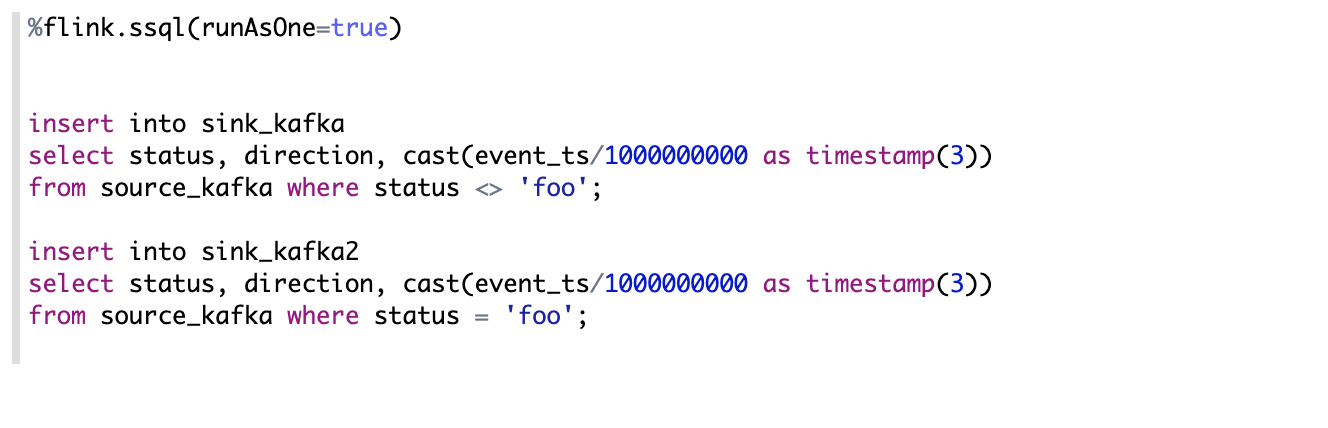
JobName的设置
对于Insert语句的Flink Job,你可以通过设置 jobName 的方式来指定 job name(如下图)。 注意只有insert 才支持设置jobName,select语句不支持。另外这种设置 jobName 的方式只能用于单条insert 语句,对于上面的Multiple insert 并不支持。
Streaming SQL 结果可视化
Zeppelin 对于 Select 语句的结果以流式的方式可视化。Zeppelin支持的可视化类型有3种。
- Single 模式
- Update 模式
- Append 模式
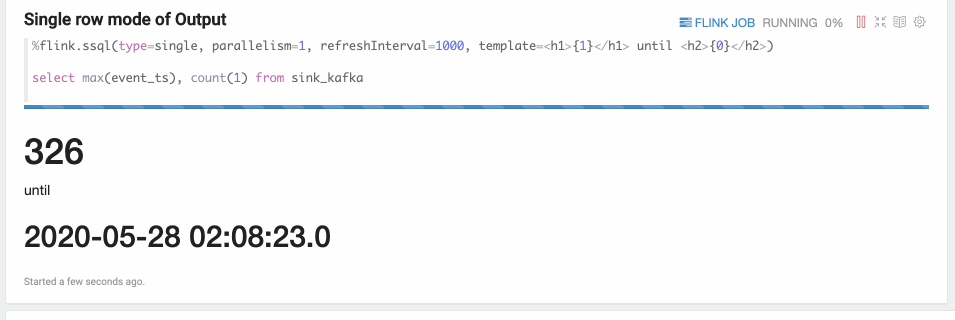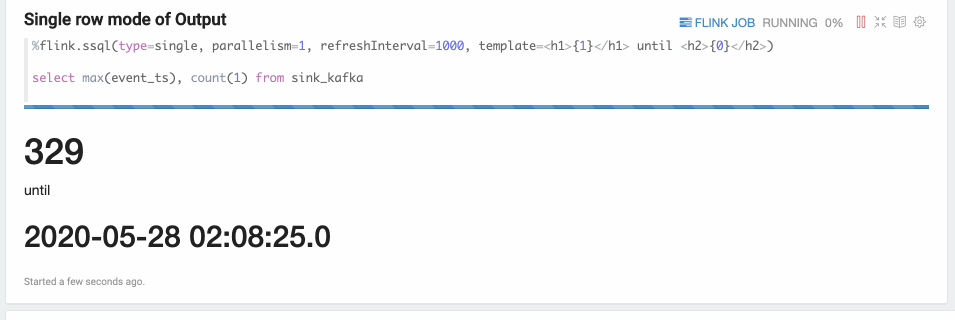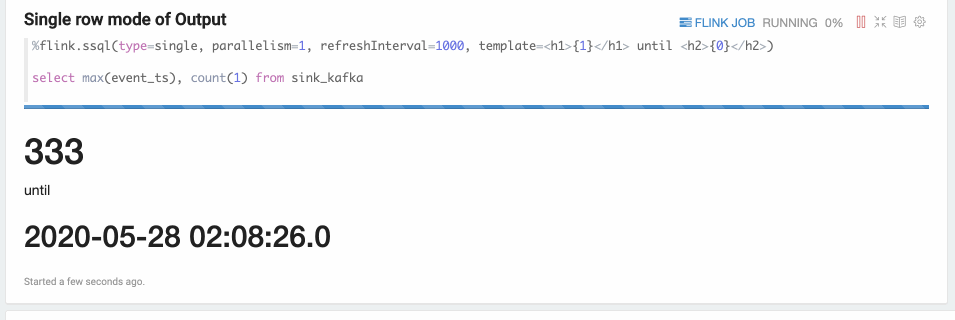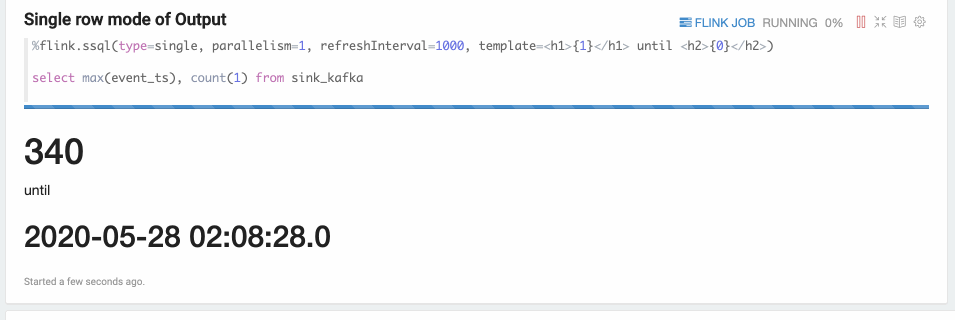
Single模式
Single模式适合当输出结果是一行的情况,不适用用图形化的方式展现,用文本的方式更适合。比如下面的Select语句。这条Sql语句永远只有一行数据,但这行数据会持续不断的更新。这种模式的数据输出格式是html形式,用户可以用template来指定输出模板,{i} 是第 i 列的placeholder。
%flink.ssql(type=single, parallelism=1, refreshInterval=3000, template=<h1>{1}</h1> until <h2>{0}</h2>)select max(event_ts), count(1) from sink_kafka
Update模式
Update模式适合多行输出的情况,比如下面的select group by语句。这种模式会定期更新这多行数据,输出是Zeppelin的table格式,所以可以用Zeppelin自带的可视化控件。
%flink.ssql(type=update, refreshInterval=2000, parallelism=1)select status, count(1) as pv from sink_kafka group by status

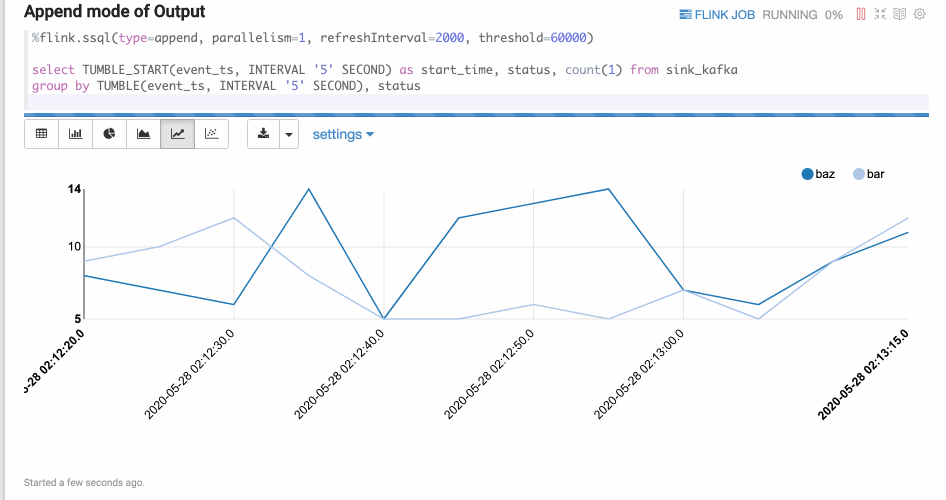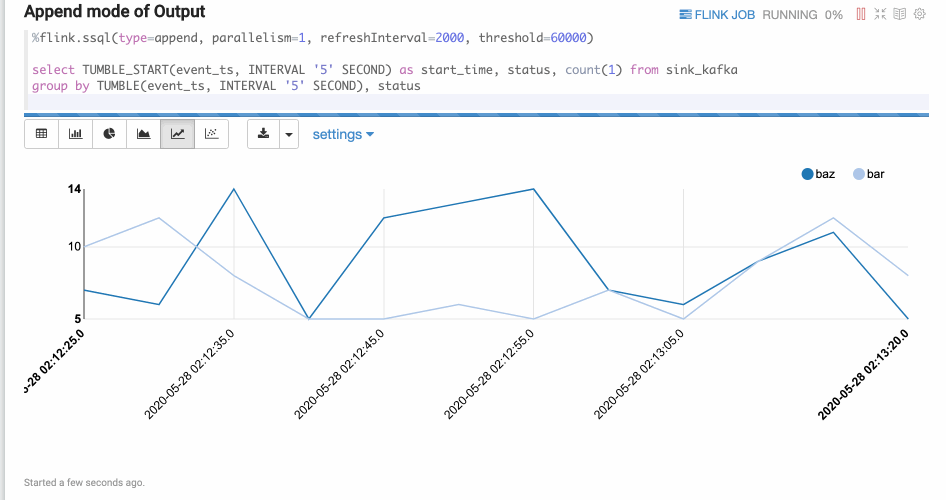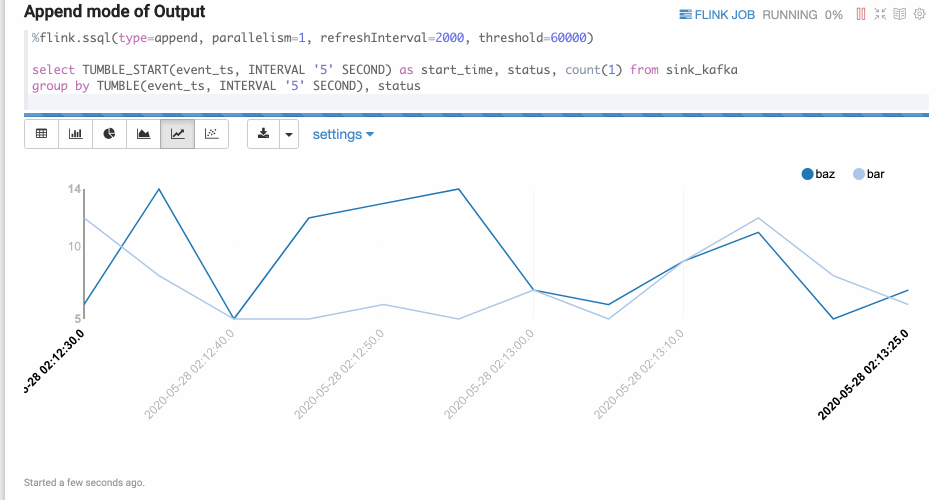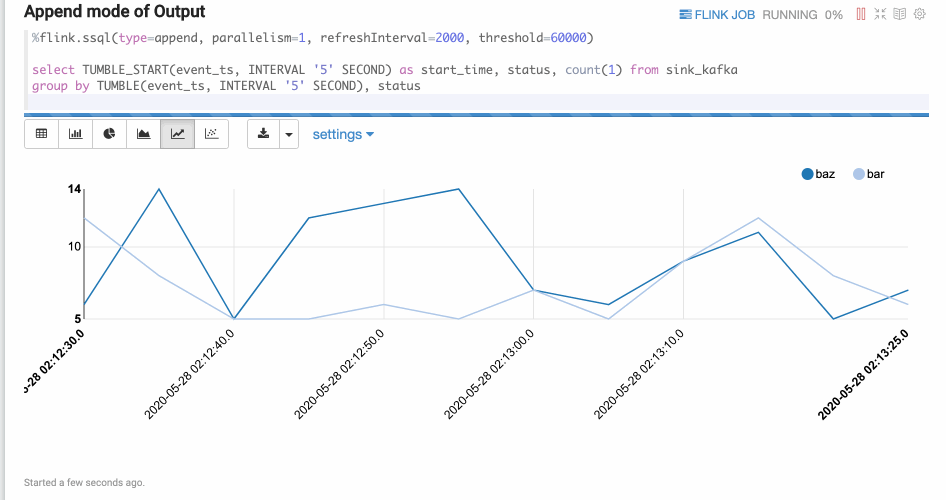
Append模式
Append模式适合时间序列数据,随着时间不断有新数据输出,但不会覆盖原有数据,只会不断append的情况。比如下面的基于窗口的group by语句。Append模式要求第一列数据类型是timestamp,这里的start_time就是timestamp类型。
%flink.ssql(type=append, parallelism=1, refreshInterval=2000, threshold=60000)select TUMBLE_START(event_ts, INTERVAL '5' SECOND) as start_time, status, count(1) from sink_kafkagroup by TUMBLE(event_ts, INTERVAL '5' SECOND), status
SQL 段落执行顺序
和 Scala 和Python 段落不一样,SQL段落是可以并行同时跑多个的。默认情况下,%flink.bsql 和 %flink.ssql 各自最多跑10个段落,你可以通过设置 zeppelin.flink.concurrentBatchSql.max 和 zeppelin.flink.concurrentStreamSql.max 来调整最大并发数。
视频教程
SQL 入门

Streaming 数据可视化 Single模式
Streaming 数据可视化 Update模式
Streaming 数据可视化 Append模式
Streaming ETL
Flink 最佳实践1
Flink 最佳实践2
钉钉群+公众号


若有收获,就点个赞吧
0 人点赞
