1、GBDT(gradient boosting decision tree )
1.1 算法核心
GBDT所要解决的问题就是在现有模型的基础上,如何在进步的缩小损失函数的值。以回归为例,即让 最小,那么GBDT的核心就是通过新的estimater来拟合上式中的误差,所以对于新的解释器的训练样本就变为了
最小,那么GBDT的核心就是通过新的estimater来拟合上式中的误差,所以对于新的解释器的训练样本就变为了 ,也就是常看的残差,
,也就是常看的残差,
1.2 sklearn例子
from sklearn.ensemble import GradientBoostingClassifiergb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)gb_clf.fit(X_train, y_train)gb_clf.score(X_test, y_test)
1.3 基于残差的GBDT的缺陷
2、XGBoost(Extreme Gboost)
XGBoost其实是对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。
2.1 数学基础
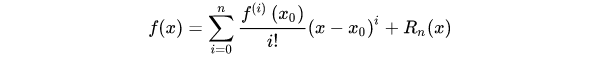
2.2 目标函数

式中, 是将全部
是将全部 棵树的复杂度进行求和,添加到目标函数中作为正则项,用于防止过拟合。
棵树的复杂度进行求和,添加到目标函数中作为正则项,用于防止过拟合。
讲目标函数用泰勒公式展开,
由于 是一个常数,对函数优化不会产生影响,因此目标函数变为:
是一个常数,对函数优化不会产生影响,因此目标函数变为:
然后把对样本点的遍历化简成对叶子节点的遍历
这个链接里面的推导过程很清晰!!!
**https://zhuanlan.zhihu.com/p/105612830
2.3 如何生成树?
我们知道在决策树中,树的生成是靠信息熵或者gini系数来决定的,那么xgboost中该如何生成树能?(寻找最优且分点)
贪婪算法
假设我们在某一节点完成特征分裂,则分裂前的目标函数可以写为:
分裂后的目标函数为:
则对于目标函数来说,分裂后的收益为:
可以想到,这个需要我们枚举所有可能的分隔来找到最优分隔点,当我们的数据量较大的时候,这种肯定不是合适的选择。
近似算法
2.4 xgboost的优势
- 正则化参数,这里优化了基于残差的GBDT
- 并行处理,XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度
- 不是对所有数据,而是采用随机的又有放回的采样
- 支持自定义损失函数(这也是采用泰勒公式展开的好处)
- 有对缺失值的处理策略
- 在寻找最佳分裂节点时,通过采用近似算法来规避遍历所有数据,提高效率
2.5 sklearn例子
5、Adaboost(Adaptive Boosting)
5.1 算法核心
- 通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
- 通过加法模型将弱分类器进行线性组合,比如 AdaBoost 通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
5.2 sklearn例子
由于Adaboost是由多个弱分类器组合出来的一个强分类器,这里需要给AdaBoostClassifier指定特定的estimaterfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn.tree import DecisionTreeClassifierada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=4), n_estimators=500)ada_clf.fit(X_train, y_train)ada_clf.score(X_test, y_test)
6、GBM(Gradient Boosting Machine)

若有收获,就点个赞吧
0 人点赞
