1、损失函数
损失函数式表示神经网络性能的“恶劣程度”的指标。
1.1 均方误差
均方误差一般用在线性回归中

import numpy as npdef mean_squared_error(y, t):return 0.5 * np.sum((y-t)**2)
1.2 交叉熵误差
一般用于逻辑回归中(单分类)

import numpy as npdef cross_entropy_error(y, t):# 表示10的负7次方delta = 1e-7return -np.sum(t * np.log(y + delta))
2、one-hot编码
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
2.1 为什么采用one-hot编码
将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。一般用在分类特征为离散的情况下
2.2 举例
中国 美国 韩国
[0,0,1] [0,1,0] [1,0,0]
3、误差分析
4、正则化参数
- L1正则 → 可以看做是在正常的损失函数后面添加参数的绝对值和
J=J_0+α_w∑∣w∣
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择(因为菱角表较多)
其中a越大,菱形的面积越小,更容易进行特征选择。
- L2正则 → 可以看做是在正常的损失函数后面添加参数的平方和
J=J_0+α_w∑_w_2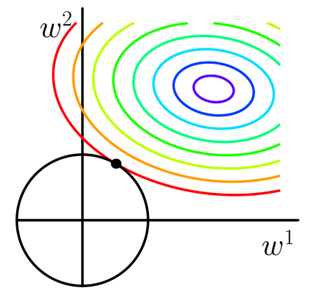
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
L2正则化通常可以取得参数很小的值,因为参数过小,到这模型的抗干扰能力强,一定程度上防止了过拟合.

若有收获,就点个赞吧
0 人点赞
