Agent级联
上一篇文章仅仅是对单个agent做了应用,现在我们学习一下agent的级联。第一agent负责收集当中的数据,通过网络发送到第二个agent当中去。第二个agent负责接收第一个agent发送的数据,并将数据保存到dhfs上。我们还是以第二个案例access_log举例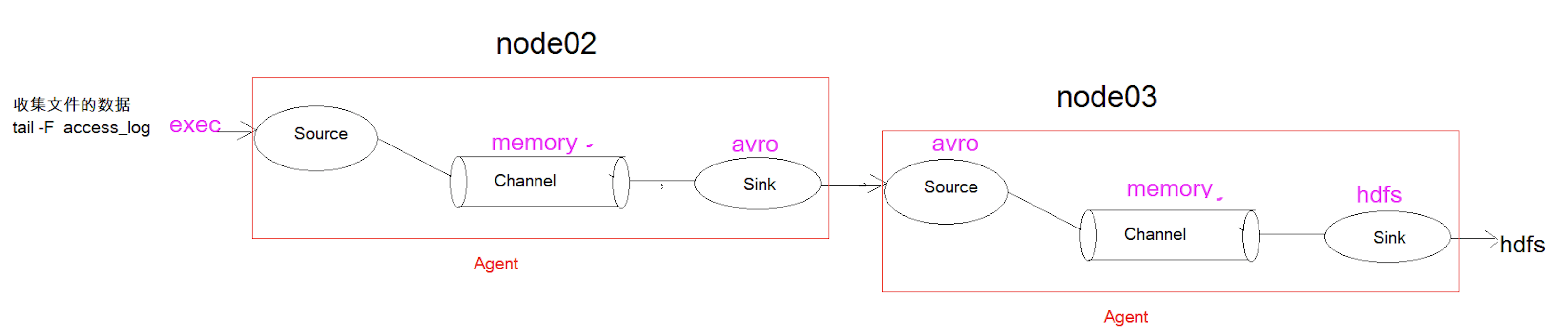
1. 在node02安装flume
将node03机器上面解压后的flume文件拷贝到node02机器
#在机器node03执行scp -r cd /export/servers/apache-flume-1.8.0-bin/ node02:$PWD
2. 在node02配置flume
cd /export/servers/ apache-flume-1.8.0-bin/confvim tail-avro-avro-logger.conf
a1.sources = r1a1.sinks = k1a1.channels = c1a1.sources.r1.type = execa1.sources.r1.command = tail -F /export/servers/taillogs/access_log #第三步创建此文件a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100##sink端的avro是一个数据发送者a1.sinks.k1.type = avroa1.sinks.k1.channel = c1a1.sinks.k1.hostname = 192.168.174.120a1.sinks.k1.port = 4141a1.sinks.k1.batch-size = 10a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
3. 开发脚本向文件中写入数据
cd /export/servers# 将需要监控的文件上传到node02scp -r sehlls/taillogs/ node02:$PWD
4. Node03 flume配置文件
a1.sources = r1a1.sinks = k1a1.channels = c1# source中的avro组件是一个接收者服务a1.sources.r1.type = avroa1.sinks.k1.hostname = 192.168.174.120a1.sinks.k1.port = 4141a1.sinks.k1.batch-size = 10a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100a1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://node01:8020/av /%y-%m-%d/%H%M/a1.sinks.k1.hdfs.filePrefix = events-a1.sinks.k1.hdfs.round = truea1.sinks.k1.hdfs.roundValue = 10a1.sinks.k1.hdfs.roundUnit = minutea1.sinks.k1.hdfs.rollInterval = 3a1.sinks.k1.hdfs.rollSize = 20a1.sinks.k1.hdfs.rollCount = 5a1.sinks.k1.hdfs.batchSize = 1a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本a1.sinks.k1.hdfs.fileType = DataStreama1.sources.r1.channels = c1a1.sinks.k1.channel = c1
5. 顺序启动
bin/flume-ng agent -c conf -f conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,conso
bin/flume-ng agent -c conf -f conf/tail-avro-avro-logger.conf -n a1 -Dflume.root.logge
cd /export/servers/shellssh tail-file.sh
6. 运行结果
会发现我们的hdfs下面多出很多文件,可以将滚动阈值调大一些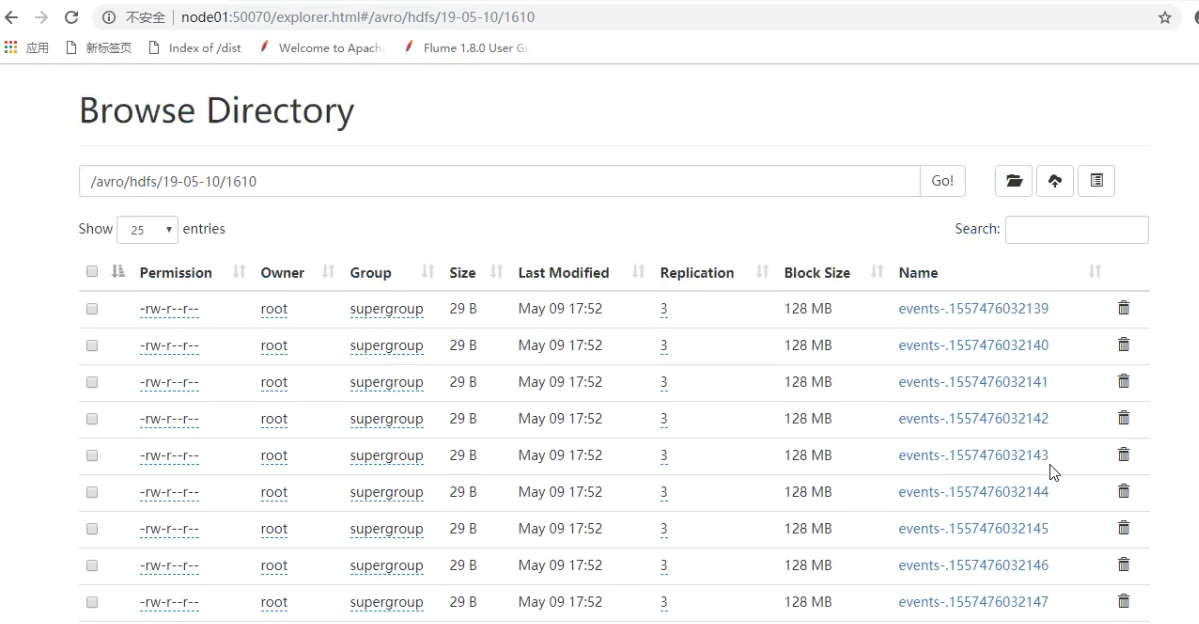
高可用方案
完成单点flume搭建完成后,下面我们搭建一个高可用的flume集群,架构如下:
待更新(等用到了再去学下)

若有收获,就点个赞吧
0 人点赞
