hdfs(hadoop distributed file system)是一个apache software founddation项目,是apache hadoop项目的一个子项目,hadoop非常适合存储大型数据(TB和PB),其就是用hdfs作为存储系统,hdfs使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统,hdfs对数据文件的访问通过流的方式进行处理,这意味着通过命令和MapReduce程序的方式可以直接使用hdfs。
它一般会把大文件分片,拆分多个小文件,专业术语也可以称之为块block,默认128M一切分,在hadoop/etc/hdfs-site.xml配置文件中。为了实现高可用,它会把分片的副本存放在其它从机上,副本个数也可通过下图参数调整dfs.replication。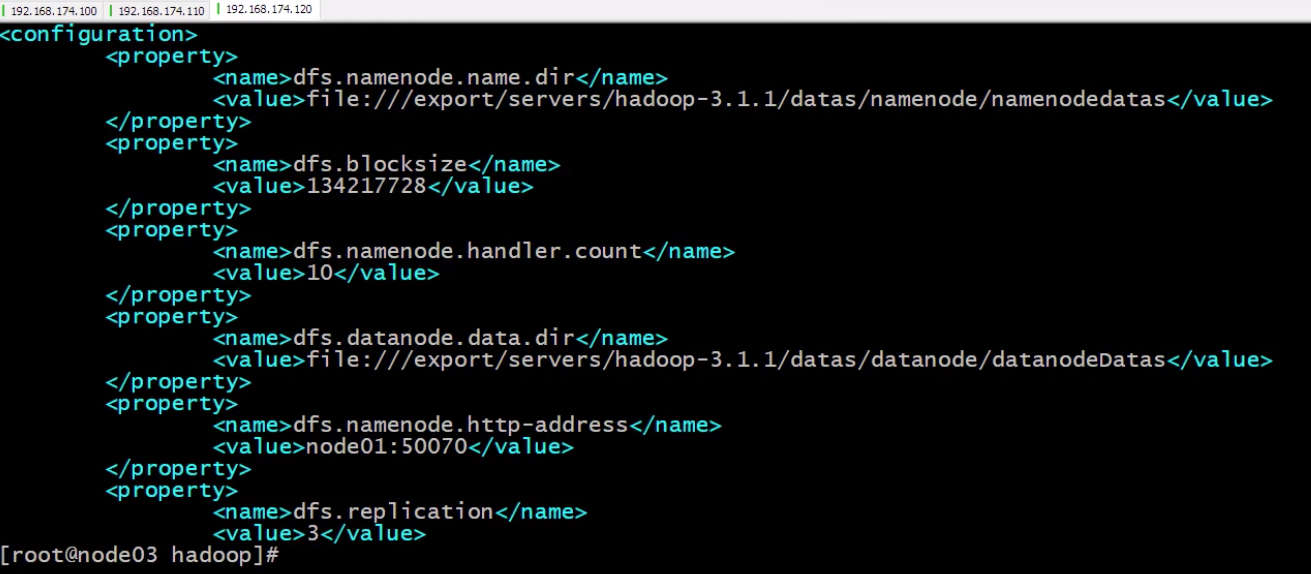
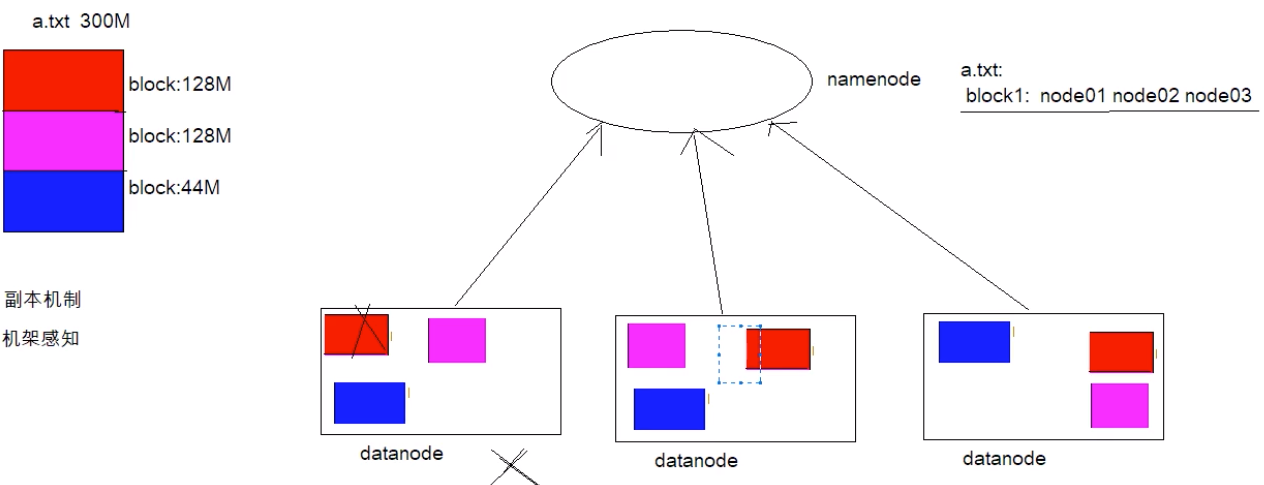
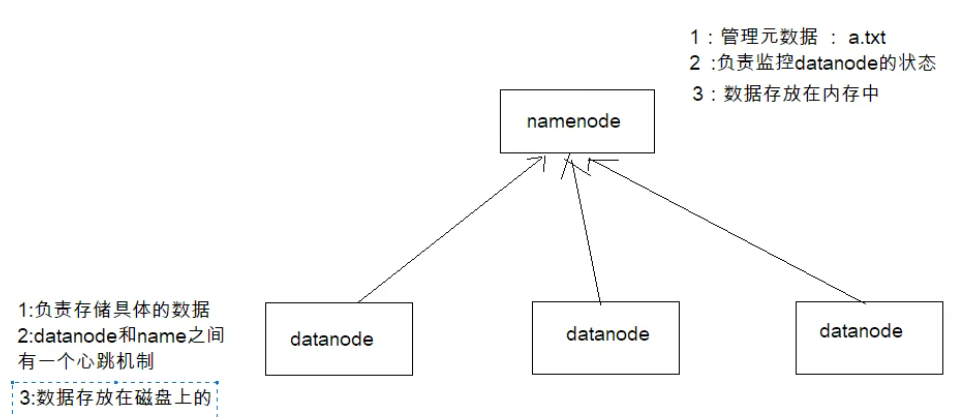
然后把各个块放在不同的机器上(hdfs节点),同时为了统一提供对外访问,让外部可以像是访问本地一样访问分布式文件系统,它有一个统一的hdfs master,它保存了整个文件系统的元信息(文件名字、文件大小、文件权限、文件存储位置,文件内容则不能称之为元数据,一般放在从机上),元信息非常重要,一般存放在内存中。所有的文件元数据都从master修改。当然hadoop主节点又被称之为NameNode,从节点称之为DateNode 。
 块缓存
块缓存
通常DataNode在磁盘中读取块,但对于频繁访问的文件,其对应的块可能被显示的缓存在DataNode的内存中,以堆外缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过缓存块的DataNode上运行任务,可以利用块缓存的又是提高读操作的性能。例如:连接(join)操作使用的一个小的查询表就是块缓存的一个很好的候选。用户或应用通过缓存池中增加一个Cache Directive来告诉NameNode需要缓存哪些文件以及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理型分组。
文件权限
hdfs的文件权限机制和linux系统文件权限机制类似,如果Linux系统用户zhangsan使用hadoop命令创建了一个文件,那么这个文件在hdfs当中的owner就是zhangsan
r:read w:write x:excute
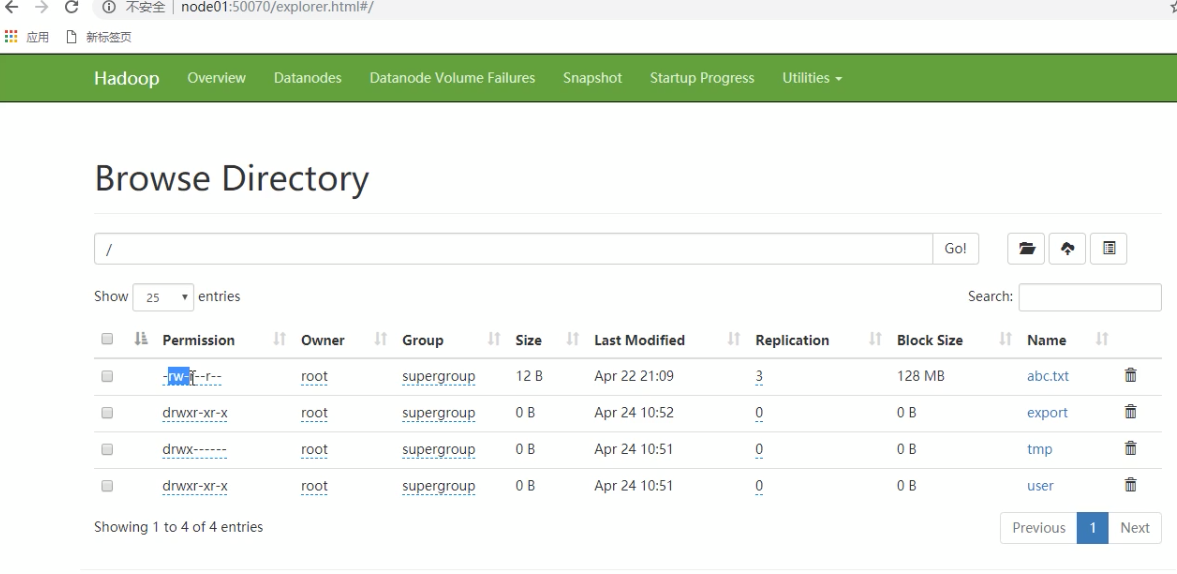
hdfs的元信息和secondaryNameNode
在hadoop的集群中,只有一个NameNode的时候,所有的元信息都会保存在FsImage和Eidts文件中,这两个文件就记录了所有的元数据信息,元数据信息的保存目录配置在hdfs-site.xml当中。secondaryNameNode是辅助nameNode保存元数据信息的,减轻nameNode的负担。
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-3.1.1.datas/namenode/namenodedatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-3.1.1.datas/dfs/nn/edits</value>
</property>
<!-- 多久记录一次hdfs镜像,默认1小时 -->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一次记录多达,默认64M -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
fsimage和edits
众所周知我们知道nameNode保存的元信息是存储在内存中的,一旦宕机所有的数据就相当于于都丢失了,所以它会跟redis一样会做持久化存储。这样就会引出两个文件,一个是fsimage,另外一个就是edits。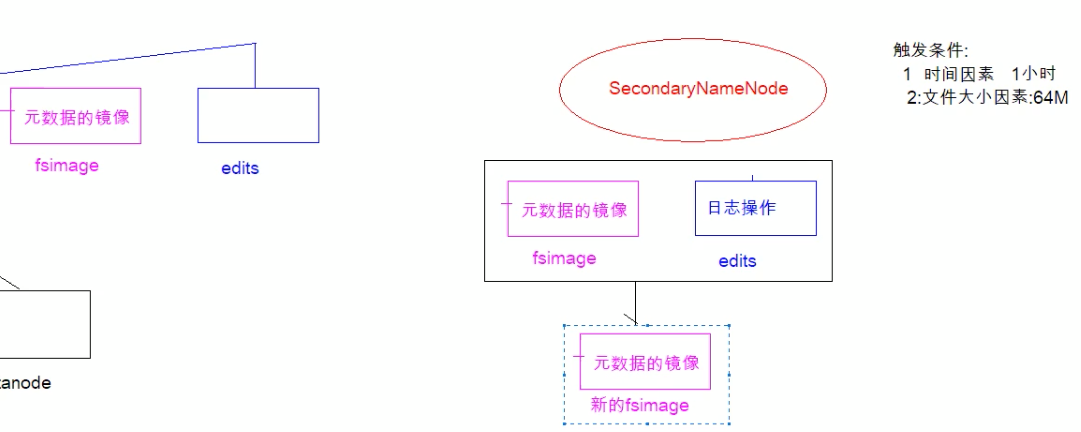
fsimage保存的二级制数据,也就是元数据的镜像(redis的rdb),edits保存的是日志操作,默认是64M(redis的aof)。不过它恢复数据是需要二者结合共同努力把数据恢复,不过久而久之edits日志文件会很大,如果一口气恢复的话会很占cpu,所以secondaryNode就应运而生。它会每间隔1小时或者当edits文件大小超过设定的阈值会把fsimage和edits拷贝过来,并且把原来nameNode上的的edits日志清空(旧的日志文件也得到了瘦身),将这两个文件合并变成一个新的fsimage,然后替换掉nameNode上的fsimage,相当于旧的fsimage得到了更新。
查看
cd /export/servers/hadoop-3.1.1/datas/namenode/namenodedatas
hdfs oiv -i fsimage_0000000000000000864 -p XML -o hello.xml
cd /export/servers/hadoop-3.1.1/datas/dfs/nn/edits
hdfs oiv -i edits_后缀 -p XML -o myedit.xml
hdfs文件写入过程
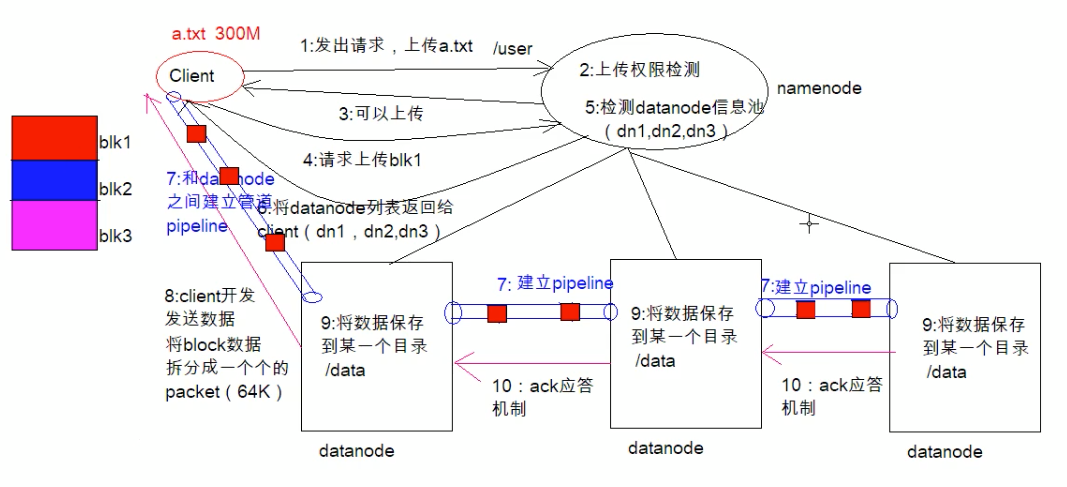
- client发起文件上传请求,通过rpc与nameNode建立通讯,nameNode检查目标文件是否已经存在,父目录是否存在,返回是否可以上传
- clinet请求第一个block该传输到哪些DataNode服务器上
- NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的DataNode地址如:A,B,C hadoop在设计时考虑到数据的安全和高效,数据文件默认在hdfs上存三分,存储策略为本地一份,同机架内其他某一节点一份,不同机架某一个节点一份
- client请求3台DataNode中的一台A上传数据(本质上一个RPC调用,建立pipline),A收到请求会继续调用B,然后B调用C,将整个pipline建立完成,后逐级返回clinet
- clinet开始往A上传第一个block(先从磁盘读取数据放到本地内存缓存),以packet为单位(默认64k),A收到一个packet就会传给B,B传给C,A每传一个packet会放入到一个应答队列等待应答。
- 数据被分割成一个个packet数据包在pipline上一次传输,在pipline反方向上,逐个发送ack,最终由pipline中第一个DataNode节点A将pipline ack发送给clinet
当第一个block传输完成后,clinet再次请求NameNode上传第二个block到服务1
hdfs文件读取过程
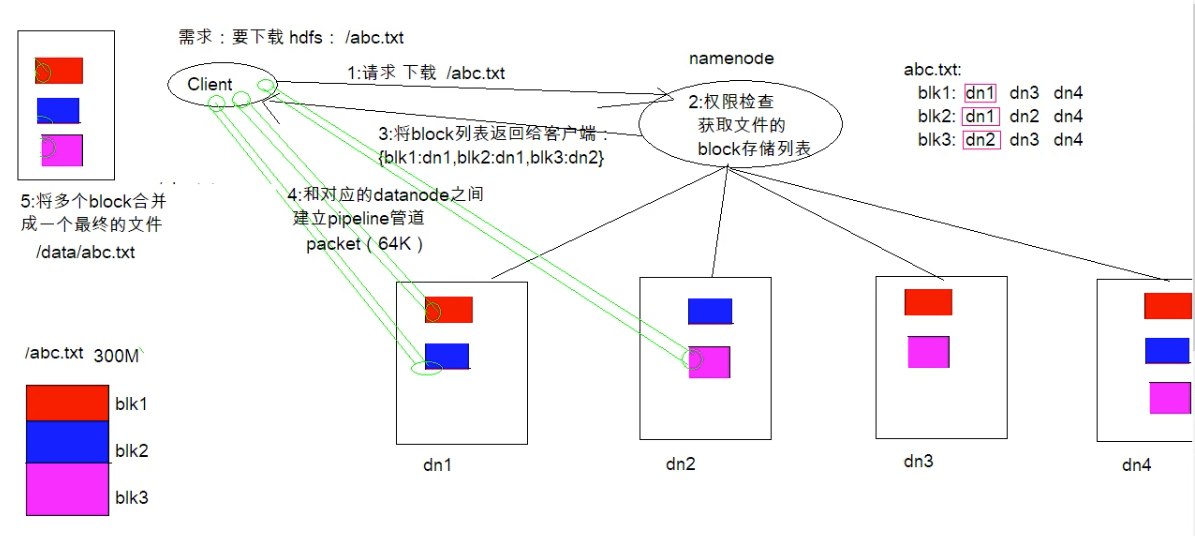
clinent向NameNode发送rpc请求,来确定请求文件block所在的位置
- NameNode会视情况返回文件的部分或者全部blcok列表,对于每个block,NameNode都会返回含有该block部分的DataNode地址;这些返回的地址,会按照集群拓扑结构得出NameNode与客户端的举例,然后进行排序,排序两个规则:网络拓扑结构中举例clent近的考前;心跳机制中超时汇报的DataNode状态为STALE排名靠后
- clinet选取排序考前的DataNode来读取block,如果客户端本身就是DataNode,那么直接将从本地获取数据
- 底层上本质是建立socket stream(FSDataInputStream),重复的调用父类DataInputStream的read方法,直到这个块上的数据全部读取完
- 当读完列表block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;
- 读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block部分的DataNode继续读
- read方法是并行读取block信息,不是一块一块的读取,NameNode只是返回client请求包含块的DataNode地址,并不是返回请求快的数据
- 最终读取所有的blcok会合并成一个完整的最终文件
常用命令
```shell hdfs dfs -ls / #查看
hdfs dfs -mkdir -p /test #创建文件夹,-p递归创建
hdfs dfs -moveFromLocal sourceDir(本地磁盘路径) hdfsDestDir(hdfs路径) #本地文件移到hdfs文件系统中去
hdfs dfs -mv hdfsSourceDir hdfsDestDir #hdfs文件系统文件移动
hdfs dfs -put localDir hdfsDestDir #文件上传到xx目录
hdfs dfs -appendToFile a.txt b.txt /hello.txt #文件合并
hdfs dfs -cat hdfsFile #查看
hdfs dfs -cp hdfsSourceDir hdfsDestDir #拷贝
hdfs dfs -rm -r hdfsSourceDir #删除,会把它放到回收站 -r递归
hdfs dfs -chmod -R 777 /xxx #修改权限为777 -R表示递归 文件夹下的子文件一并修改
hdfs dfs -chown -R hadoop:hadoop /test # 修改用户组和用户
需要注意的一点就是我们权限默认是关闭的,设置是在/export/servers/hadoop-3.1.1/etc/hadoop/hdfs-site.xml 它的配置dfs.permission.enable=false,所以我们设置文件权限是没有意义的,因为它压根不会生效。
<a name="T1wt2"></a>
#### 权限问题
1. 停止hdfs集群,在node01机器上执行
```shell
cd /export/servers/hadoop-3.1.1
sbin/stop-dfs.sh
sbin/stop-yarn.sh
- 修改配置,并重启
```shell
vim /export/servers/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
修改此项配置
dfs.permission.enable true
将当前配置分发给其它机器
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
重启
sbin/start-dfs.sh sbin/start-yarn.sh
<a name="ZohZv"></a>
### hdfs的api操作
<a name="XwhkN"></a>
#### windows配置环境变量
在windows系统配置hadoop运行环境:
1. 下载windows版本hadoop,将apache-hadoop-3.1.1文件夹拷贝到一个没有中文没有空格的路径下面
1. 配置hadoop的环境变量:HADOOP_HOME
1. 在bin目录下的hadoop.dll拷贝到系统盘C:\Windows\Ssytem32
1. 重启电脑
<a name="bBCr0"></a>
#### maven依赖
```xml
<!-- 大数据学习 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.1.1</version>
</dependency>
获取FileSystem几种方式
package com.dongnaoedu.network.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class HdfsApiStudy {
@Test
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
// 指定我们使用的文件系统
configuration.set("fs-defaultFS","hdfs://node01:8082/");// node01 ==> ip 需要配置hosts的映射
// 获取指定的文件系统,相当于获取了主节点中所有的元数据信息
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem.toString());
}
@Test
public void getFileSystem2() throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8082/"),configuration);
System.out.println(fileSystem.toString());
}
@Test
public void getFileSystem3() throws Exception {
Configuration configuration = new Configuration();
configuration.set("fs-defaultFS","hdfs://node01:8082/");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
@Test
public void getFileSystem4() throws Exception {
Configuration configuration = new Configuration();
// 伪造身份去访问文件
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://node01:8082/"),configuration,"root");
System.out.println(fileSystem.toString());
}
}
获取目录下所有文件信息
public class HdfsApiStudy {
@Test
public void listMyFiles() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs-defaultFS","hdfs://node01:8082/");
FileSystem fileSystem = FileSystem.get(configuration);
RemoteIterator<LocatedFileStatus> remoteIterator = fileSystem.listFiles(new Path("/"), true);
while (remoteIterator.hasNext()){
LocatedFileStatus next = remoteIterator.next();
// 文件存储路径
String filePath = next.getPath().toString();
// block 存储信息
BlockLocation[] blockLocations = next.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// block副本存储的位置
String[] hosts = blockLocation.getHosts();
}
}
}
}
创建文件、上传、下载
@Test
public void listMyFiles() throws IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://node01:8082/"),configuration,"root");
// 创建文件夹
if (fileSystem.mkdirs(new Path("/hello/test"))) {
System.out.println("mkdir success");
}
// 创建文件
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/a.txt"));
// 方式一:下载文件到本地
FSDataInputStream inputStream = fileSystem.open(new Path("/exist.txt"));
FileOutputStream outputStream = new FileOutputStream(new File("E://exist.txt"));
IOUtils.copy(inputStream, outputStream);
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
// 方式二:下载文件到本地
fileSystem.copyFromLocalFile(new Path("/exist.txt"),new Path("E://exist.txt"));
// 文件上传
fileSystem.copyFromLocalFile(new Path("E://exist.txt"),new Path("/exist.txt"));
fileSystem.close();
}
小文件合并
由于hadoop擅长村存储大文件,因为大文件的元信息比较少,如果hadoop集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理。
在我们hdfs的shell命令模式下,可以通过命令行将很多hdfs文件合并成一个大文件下载到本地
cd /export/servers
hdfs dfs -getmerge /config/*.xml ./big.xml
本地文件合并上传到hdfs
@Test
public void listMyFiles() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs-defaultFS","hdfs://node01:8082/");
FileSystem fileSystem = FileSystem.get(configuration);
// 本地小文件合并上传到hdfs
FSDataOutputStream out = fileSystem.create(new Path("/big.xml"));
LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration());
FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("file:////E:\\existDir"));
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream in = localFileSystem.open(fileStatus.getPath());
IOUtils.copy(in,out);
IOUtils.closeQuietly(in);
}
IOUtils.closeQuietly(out);
localFileSystem.close();
fileSystem.close();
}

若有收获,就点个赞吧
0 人点赞
