什么是数仓
基本概念
数据仓库英文名:Data Warehouse,数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持,它出于分析报告和决策支持目的而创建(比如爬虫获取的数据)。数据仓库并不产生任何数据,同时自身也不需要消费任何数据,数据来源于外部,并且开放给外部应用。
主要特征
数据仓库是面向主题的(subject-oriented)、集成的(integrated)、非易失的(non-volatile)和时变的(time-variant)数据集合,用于支持管理决策
面向
数据库和数据仓库的区别?
实则就是OLTP和OLAP的区别。
- 操作型处理:叫联机事务处理OLTP,也可以称之为面向交易的处理系统,它是针对具体的业务在数据库联机的日常操作,通过对少数记录进行查询,修改。用户较为关心操作的响应时间、数据安全性、完整性和并发支持的用户数等问题。传统的数据库作为数据管理的主要手段,主要用于操作型处理。
- 分析性处理:叫联机分析性处理OLAP,一般针对于某些主题的历史数据进行分析,支持管理决策。首先要明白数据仓库的出现并不是为了取代数据库。
- 数据库是面向事务的设计,数据仓库是面向主题的设计
- 数据库一般存储业务数据,数据仓库存储一般是历史数据
- 数据库设计一般避免冗余,一般针对某一个业务用于进行设计,比如一张user表,记录用户吗、密码等简单数据即可。符合业务应用,但不符合分析。数据仓库在设计是有意引入冗余,依照分析需求、分析维度、分析指标而设计。
- 数据库是为了捕获数据而设计,数据仓库是为了分析数据而设计
以银行业务为例,客户的每笔交易都会被记录到数据库,这就要求时效性,客户每存一笔钱需要几十秒显然是无法忍受的,这就要求数据库只能存储很短一段时间的数据。而分析系统是事后,它从事务系统中获取数据,并做汇总、加工、为决策者提供依据。比如某银行某分行一个月发生了多少交易,交易额当前存款又是多少等等。又比如当年年龄20-35年龄段消费的理财产品最多,然后决策者做出怎么样的商业决策。
hive和传统数据库对比
hive用于海量数据的离线数据分析,它具有sql数据库的外表,但应用场景完全不同,只适合用来做批量的数据分析
| Hive | RDBMS | |
|---|---|---|
| 基础语言 | hql | sql |
| 数据存储 | hdfs | raw device or local fs |
| 执行 | mapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 高 | 低 |
| 索引 | 0.8版本后加入位图索引 | 有复杂的索引 |
hive
它是基于hadoop的数据仓库工具,可以将结构的数据文件映射为一张数据库表,有了这张表,就可以根据类似sql查询的功能去做各种select。
举个例子,比如某个txt文件记录了一些固定格式的用户访问记录,如下:
1,jack,12:002,tom,13:003,tim,13:014,jack,12:01
目的是统计各个用户的访问次数或者说访问记录。hive就会将这些结构化的数据文件映射为一个数据库表,比如:create table_access(id,name,time),就相当于记录了表和文件的映射关系,同时也可以使用类似于sql的文件语句进行查询hsql:select name,count(*) from access group id;
当然hive会把这些元数据(表与文件之间的映射、表字段与文件之间的映射、表数据与文件的存放位置)存储起来,一般存储在mysql/derby
那它是怎么实现的呢?其本质其实是将hsql语句转换为mapReduce的任务进行运算,底层由hdfs来提供数据存储,说白了hive可以理解为一个将sql转换为mapReduce的任务工具,甚至可以说hive就是一个mapReduce的客户端
为什么使用hive
直接使用hadoop面临的问题
- 人员学习成本太高
- 项目周期要求太短
-
为什么要使用hive
操作接口采用sql语法,提供快速开发能力
- 避免去写mapReduce,减少开发人员的学习成本
-
hive特性
扩展性:可以自由扩展集群规模,一般情况下不需要重启服务
- 延展性:支持用户自定义函数,根据自己的需求来实现自己的函数
-
安装
因为之前安装的hodoop版本是3.1.1所以这个版本最好保持一致,否则会出现版本不兼容问题
下载解压
地址:http://archive.apache.org/dist/hive/hive-3.1.1/apache-hive-3.1.1-bin.tar.gz
上传并解压
将我们的安装包上传到第三方服务器/export/softwares路径下,然后进行解压
cd /export/softwares tar -zxvf apache-hive-3.1.1-bin.tar.gz -C ../servers/安装mysql
因为我们要存储hive的元数据,所以需要安装。因为默认安装的derby存在一个缺陷,所以用mysql替换
方法一:可参考我前面的devops部署章节
方法二:在线安装mysql
yum install mysql mysql-server mysql-devel
# 第二步,启动mysql服务
/etc/init.d/mysqld start
# 第三步:通过mysql安装自带脚本进行设置
/usr/bin/mysql_secure_installation
# 第四步:进入mysql客户端然后进行授权
mysql -u root -p
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
exit
- 修改hive的配置文件
修改hive-env.sh
cd /export/servers/apache-hive-3.1.0-bin/conf
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/export/servers/hadoop-3.1.1
export HIVE_CONF_DIR=/export/servers/apache-hive-3.1.0-bin/conf
修改hive-site.xml
cd /export/servers/apache-hive-3.1.0-bin/conf
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node03.hadoop.com</value>
</property>
</configuration>
- 添加mysql的连接驱动包到hive的lib目录下
hive使用mysql作为元数据存储,必然需要连接mysql数据库,所以我们添加一个mysql的连接驱动包到。hive的安装目录下,然后就可以准备启动hive了,将我们准备好的mysql-connector-java-5.1.38.jar 这个jar包直接上传到 /export/servers/apache-hive-3.1.0-bin/lib 这个目录下即可
export HIVE_HOME=/export/servers/apache-hive-3.1.0-bin export PATH=:$HIVE_HOME/bin:$PATH
<a name="QSjVF"></a>
## 基础使用
<a name="hXMNA"></a>
### 数据库
上述操作执行后,进入到我们解压后的apach-hive-3.1.1-bin目录下
```bash
# 进入到hive的客户端,类似我们mysql的>mysql
cd /export/softwares/apach-hive-3.1.1-bin
hive> bin/hive
# 查看仓库有哪些数据库
hive> show databases;
# 创建数据库
hive> create databases if not exists myhive;
# 创建表,这些表的元数据保存在我们之前创建的mysql上
hive> use myhive;
create table stu(id int,name string);
我们的元数据信息就保存在我们mysql中hive库的Tables,也就说明我们hive和mysql已经建立了关联。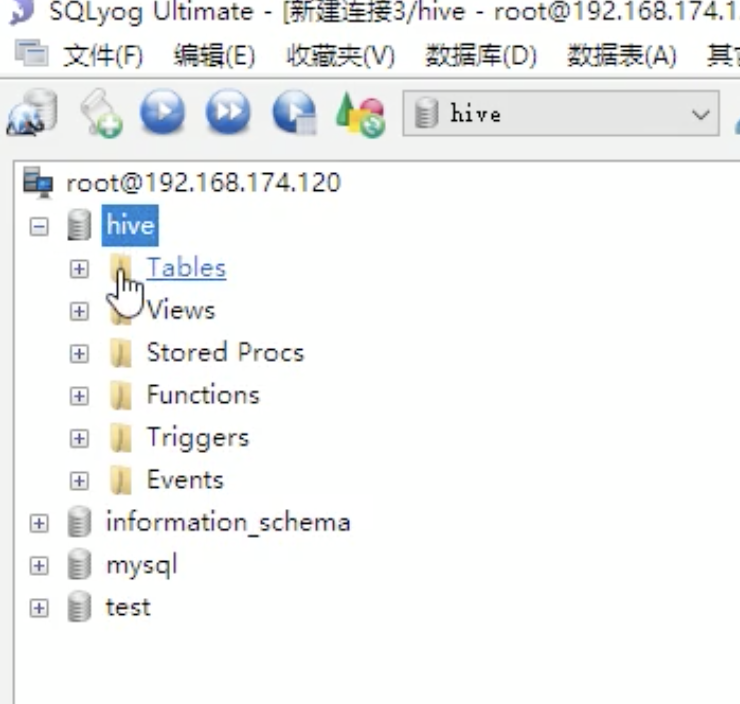
当然也可以不通过进入hive客户端的方式执行sql代码。我们可以将我们要执行的sql编写一个文件如:hive.sql,然后执行hive -f /export/softwares/hive.sql 如果提示命令hive :commond not found 可能是因为你未在/export/softwares/apach-hive-3.1.1-bin/bin 目录下执行,切换到这里即可
create databases if not exists mytest;
use mytest;
create table user(id int,name string);
insert into user(1,"jack");
select * from user;
指定存储位置
hive的表存放位置模式是由hive-site.xml当中的一个属性指定的,可以在浏览器中访问我们的hdfs,浏览器输入node01:50070/explorer.html,所以我们创建的表都是默认存在在/user/hive/warehouse。
<name>hive.matestore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
当然也可以指定我们创建数据的存放位置,比如我把他放在根目录:`create databases myhive2 localtion '/myhive2';`
查看数据库详情
hive>desc database myhive;
hive> desc database extened myhive; # 查看更多的详情

查看表详情
desc table_name;
desc formatted table_name; #查看表详情
删除数据库
# 如果数据库存在表,则会报错
hive> drop database myhive;
# 强制删除,连表一起删除
hive> drop database cascade;
创建数据库表语法
CREATE [EXTERNAL 内部/外部表] TABLE [IF NOT EXISTS] table_name
[(列名 类型 字段注释说明(说明不能使用中文),.....)]
[表注释说明]
[PARTITIONED BY (列名 类型 字段注释说明,....)] 分区会创建文件夹
[CLUSTERED BY (列名,列名,...)] 分桶
[LOCALTION hdfs的存储位置]
- EXTERNAL关键字可以让用户创建一个外部表,hive在创建内部表时,会将数据移动到数据仓库指向的路径,若创建外部表仅记录数据所在路径,不对数据的位置做任何的改变。在删除表时,内部数据和元数据都会被一起删除,而外部表只删除元数据,不删除数据。
创建内部表
# 根据查询的结果转变成一张表(复制表结构和表内容) create table user2 as select * from user; # 单单复制表的结构,不会拷贝内容 create table user3 like user;创建外部表
外部表因为是指其他的hdfs路径的数据加载到表中来的,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs中不会删掉。管理表和外部表的使用场景
每天将收集到的网站日志定期流入hdfs文本文件,在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部存储,数据通过select+insert进入内部表操作案例
分别创建老师和学生外部表,并向表中加载数据create external table teacher(t_id int,t_name string) row format delimited fields terminated by '\t';create external table student(s_id int,s_name string,s_birth string) row format delimited fields terminated by '\t';加载数据
本地加载
下面是上传本地数据到服务器中去,csv一般从数据库导出。不过这里需要注意的是我们的分隔符必须和我们的csv文件的分符号一致,都是 “/t” 的格式hive> load data local inpath '/export/softwares/hivedatas/student.csv' into table student;从hdfs文件系统中加载数据
备注:需要提前将数据上传到hdfs文件系统cd /export/servers/hivedatas hdfs dfs -mkdir -p /hivedatas # 在hdfs上创建一个目录 hdfs dfs -put teacher.csv /hivedatas # 把csv数据上传到 /hivedatas 该目录下 load data inpath '/hivedatas/teacher.csv' into table teacher;创建分区表
在大数据中有一种思想叫做分而治之,就是把大文件切割成一个个小文件,这样每次操作一个小文件就会简单很多。创建分区表的语法# 根据年月日分区 带多个分区 create table score(s_id string,c_id string,s_score int) partitioned by(year string,month string,day string) row format delimited fields terminated by '\t';加载数据到单分区表中
比如我每个月份都会生产一个文件,这时候就可以按照月份把对应的文件放到不同的文件夹# 会在对应仓库新增一个名为month=201806的文件夹 load data local inpath '/export/servers/hivedatas/score.csv' into table score partition(month='201806'); # 在执行同一个表里面会有month=201807的文件夹 load data local inpath '/export/servers/hivedatas/score.csv' into table score partition(month='201807');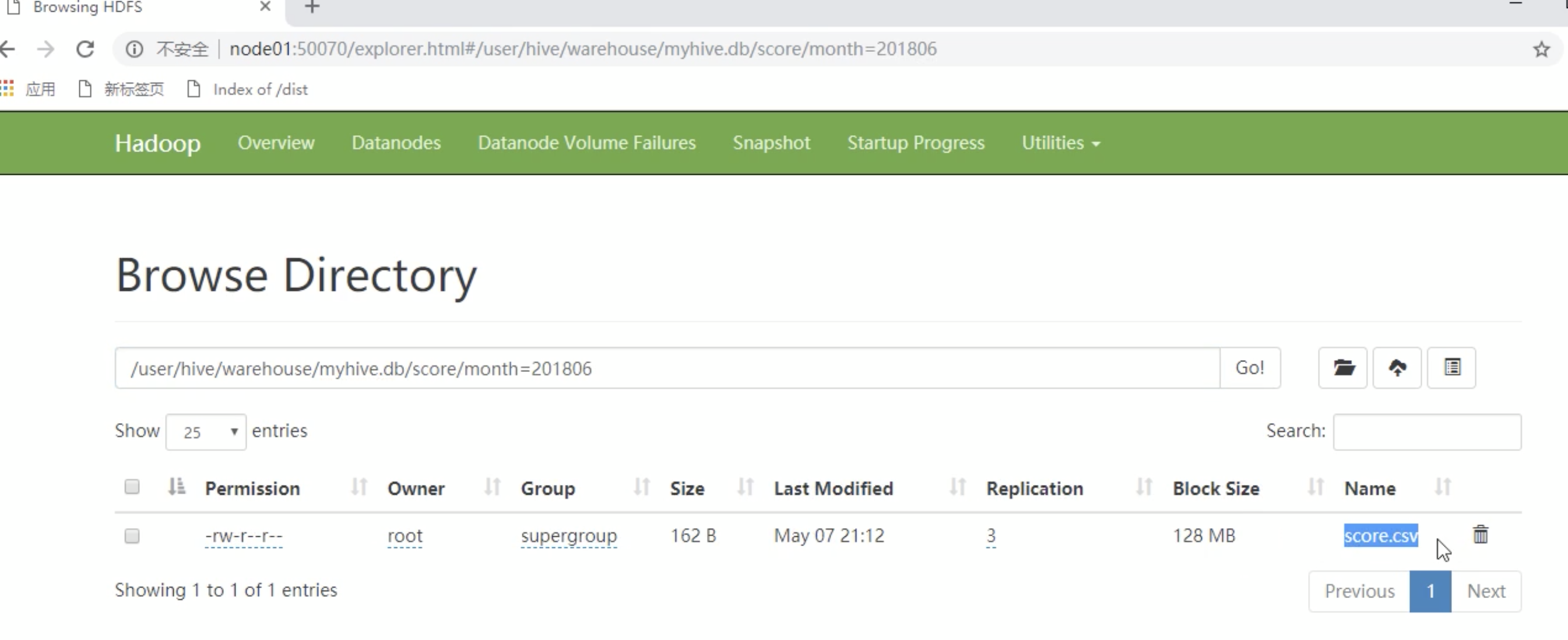
加载数据到多分区表中
这时候会创建三个文件夹,并且里面是包含的关系,三级相互嵌套# 会在对应仓库新增一个名为month=201806的文件夹 load data local inpath '/export/servers/hivedatas/score.csv' into table score2 partition(year='2018',month='06',day='01');分区数据联合查找
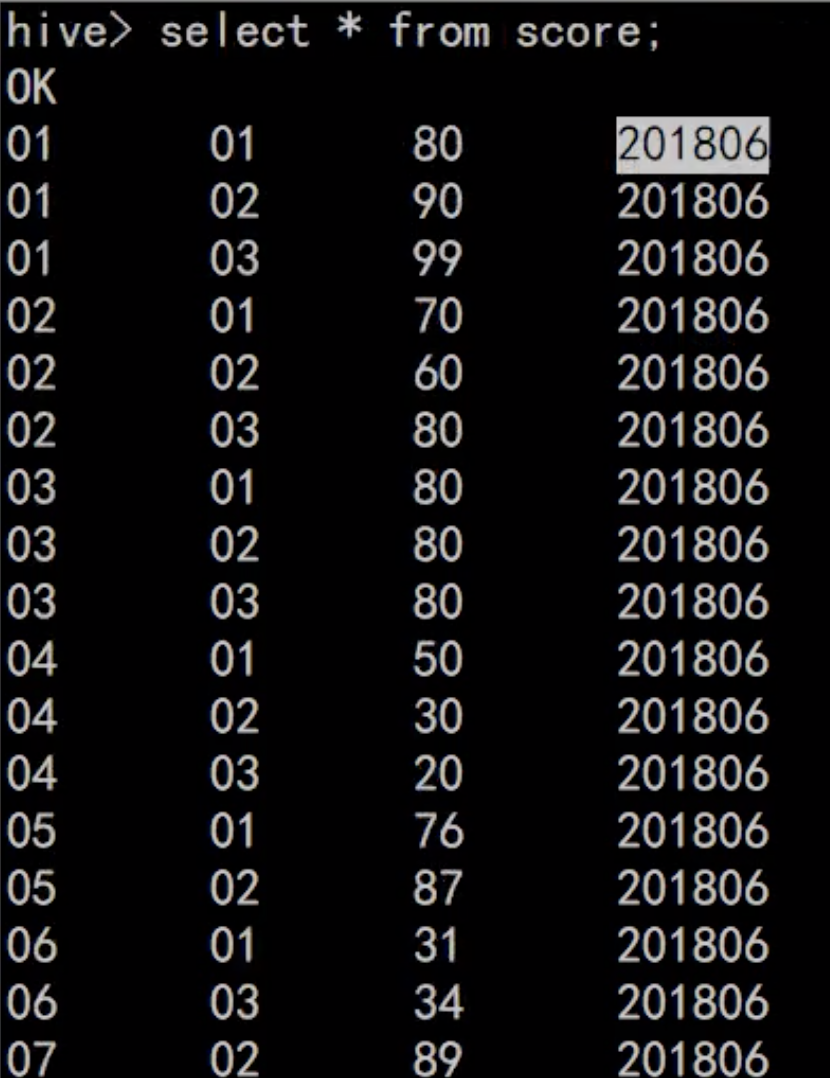 ```bash
```bash这时候会出现四列数据,因为第四列会有分区字段,当然这里下面还有数据比如201807的分区列没下拉出来
select * from score;
只查询 month=201807 文件夹的数据
select * from score where month=’201807’;
只查询 month=201806和month=201807 文件夹的数据
select from score where month=’201807’ union all select from score where month=’201807’;
<a name="i2ZgR"></a>
#### 分桶表
将数据按照指定字段的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,将其划分到多个文件中去,开启hive的分桶功能
```bash
hive> set hive.enforce.bucketing=true # 默认未开启
设置reduce的个数
hive> set mapreduce.job.reduces=3 # 默认-1
创建分桶表
create table cource(c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
桶表的数据加载,由于桶表的数据加载通过hdfs dfs -put文件或者通过load data均不好使,只能通过insert overwrite,创建普通表,并通过insert overwrite的方式将普通表的数据通过查询的方式加载到分 桶表中去。<br />**创建中间表course**
create table course_common(c_id string,c_name string,t_id string) row format delimited fields terminated by '\t';
给中间表course_common添加数据
load data local inpath '/export/servers/hivedatas/course.csv' into table course_common;
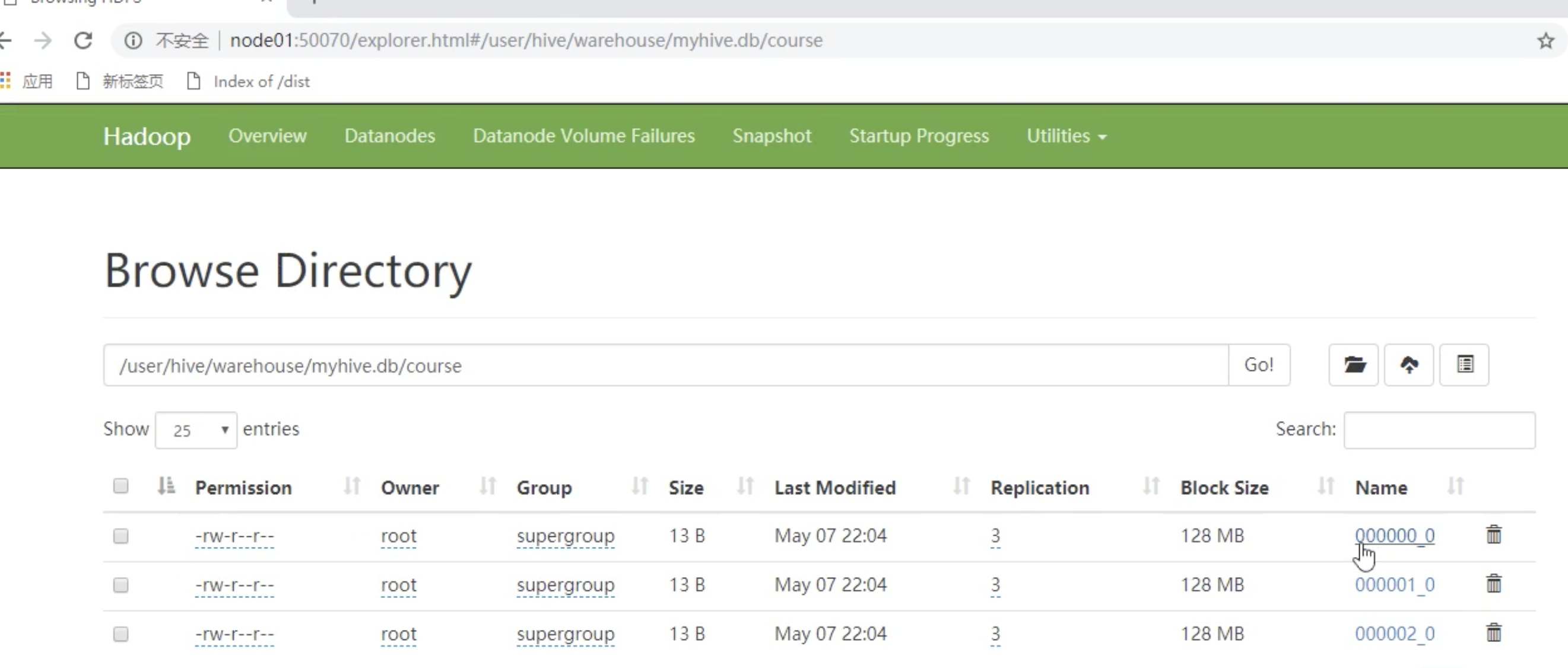
通过insert overwrite
可以发现原本一个大的文件被拆分成了三个小文件
insert overwrite table course select * from course_common cluster by(c_id);

若有收获,就点个赞吧
0 人点赞
