介绍
hadoop是一个分布式基础框架,它允许使用简单的编程模型跨大型计算机的大型数据集进行分布式处理,它主要解决2个问题:
- 大数据的存储问题:hdfs
- 大数据计算问题:mapReduce
问题:
1. 大文件怎么存储?
假设一个文件非常大,大小为1PB(1024T),该怎么存储?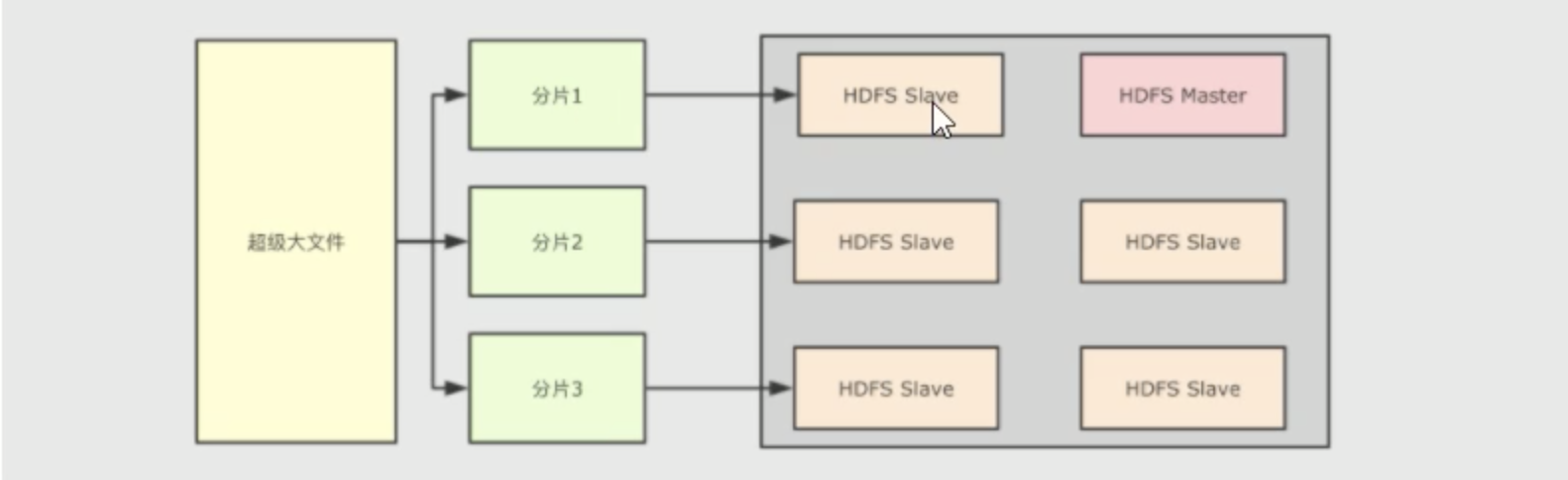
把大文件分片,拆分多个小文件,专业术语也可以称之为块block。然后把各个块放在不同的机器上(hdfs节点),同时为了统一提供对外访问,让外部可以像是访问本地一样访问分布式文件系统,它有一个统一的hdfs master,它保存了整个文件系统的元信息(文件大小、文件权限、文件位置,文件内容则不能称之为元数据),所有的文件元数据都从master修改。当然hadoop主节点又被称之为NameNode,从节点称之为DateNode2. 大数据怎么计算?
从一个日志文件中计算独立ip,以及出现的次数,如果数据量特别大我们可以将整个任务拆开,划分比较小的任务进行计算。分而治之的思想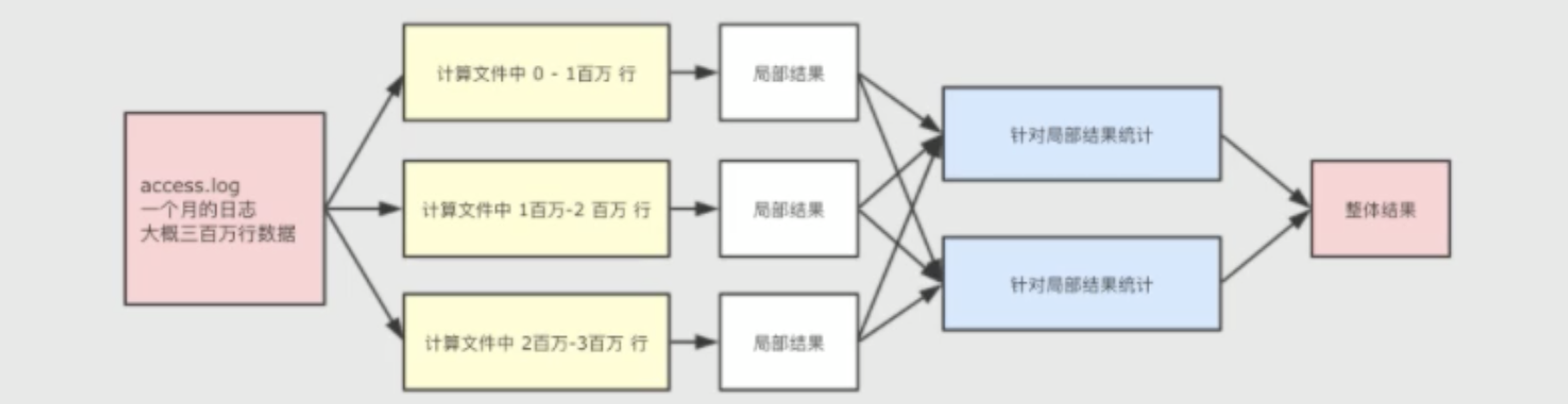
比如我们的nginx的access日志,记录里一个月的访问日志, 首先同上先拆分,然后通过我们的程序计算出各个块执行结果,然后整合合并结果hadoop组成
- hadoop分布式文件系统(hdfs):提供对应用程序数据的高吞吐量访问的分布式文件系统
- hadoop common其它hodoop模块所需的java库和应用程序,这些库提供了文件系统和操作系统的抽象,并包含启动hadoop所需的必要java文件和脚本
- hadoop MapReduce 分布式计算,基于yarn的大型数据集并行处理系统
-
安装
上传安装解压
从apache官网下载hadoop压缩包解压到/export/software目录下,建议下载version>=3的版本
- 解压:cd export/software;tar -xvf hadoop-3.1.1.tar.gz -C /servers(我这里解压到上一级的servers目录);进入到解压后的hadoop的/etc配置文件
- 修改配置文件
core-site.xml
hadoop-env.sh
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
- 创建临时文件夹
待更新

若有收获,就点个赞吧
0 人点赞
