java的序列化(Serialization)是一个重量级的序列化框架,一个对象被序列化后,会附带很多额外的信息
各种校验信息、header、继承体系等),不便于在网络中高效传输,所以hadoop自己开发了一套序列化机制(writable),精简高效,不用java对象类一样传输多层父子关系,需要哪个属性就传输哪个属性,大大减少网络传输的开销。
writable是hadoop序列化格式,hadoop顶一个这样一个writable接口,一个类要支持可序列化只需要实现这个接口即可。另外writable有一个子接口是WritableComparable,它是即可实现序列化也可以实现对key进行比较,我们可以自定义key实现WritableComparable来实现我们的功能。
数据格式如下:排序每一行数据,要求第一列按照字典顺序排序,第二列按照数字从小到大排序(都是a按照后面数字排序)
a 1a 9b 3a 7b 8b 10a 5
分析
我们知道了WritableComparable可以实现对key的进行比较,但是因为我们这里要比较的是两列,所以单独比较是不合适的,需要把k1 v1经过map阶段转为k2 v2,k2是字母数字的结合作为一个对象,v2跟之前v1一样。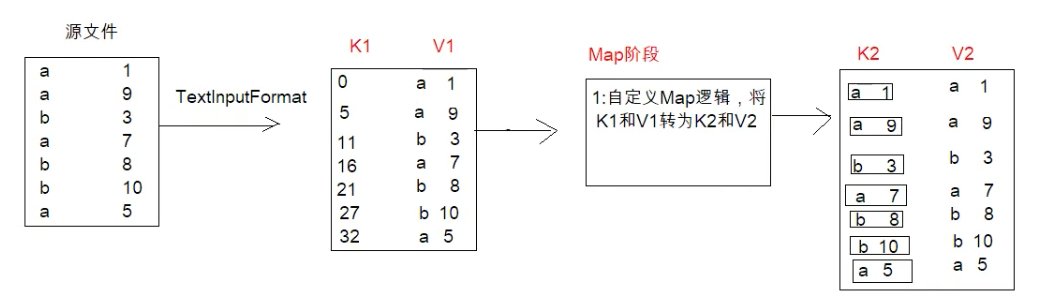
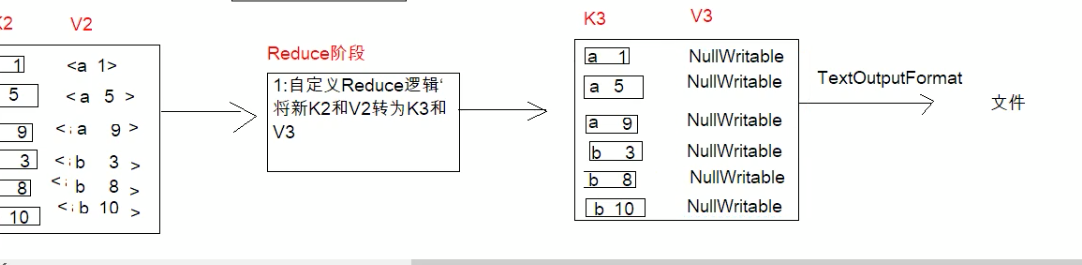
在shuffle阶段,我们对排序规则进行自定义,形成新的k2v2,再到reduce阶段,因为v3我们这可以丢弃。所以用NullWritable表示。然后最后通过TextOutputForma写道文件中去,因为v3丢弃,所以我们这里可以不需要将它写入。
代码实现
PairWritable
package com.dongnaoedu.network.hadoop.mapreduce.sort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PairWritable implements WritableComparable<PairWritable> {
private String first;
private int second;
@Override
public int compareTo(PairWritable other){
// 先比较first,first相同比较second
int result = this.first.compareTo(other.first);
if(result == 0){
return this.second - other.second;
}
return result;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
// 序列化
dataOutput.writeUTF(first);
dataOutput.writeInt(second);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
// 反列化
this.first = dataInput.readUTF();
this.second = dataInput.readInt();
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
}
SortMapper
package com.dongnaoedu.network.hadoop.mapreduce.sort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,PairWritable,Text>{
@Override
public void map(LongWritable key, Text value, Mapper.Context context) throws IOException,InterruptedException{
// 对每一行数据进行拆分,然后封装到PairWritable对象中作为k2
String[] split = value.toString().split("\t");
PairWritable obj = new PairWritable();
obj.setFirst(split[0]);
obj.setSecond(Integer.parseInt(split[1]));
//将k2和v2传递给context
context.write(obj,value);
}
}
SortReducer
package com.dongnaoedu.network.hadoop.mapreduce.sort;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SortReducer extends Reducer<PairWritable, Text,PairWritable, NullWritable> {
@Override
protected void reduce(PairWritable key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
// 我们仅仅是将v2的值传给v3,然后定义v3为个占位符空对象
// context.write(key, NullWritable.get()); 这样写会存在问题,会把重复的值记录到集合中去
/**
* a 1
* a 1
* ==> a 1 <a 1,a 1>
*/
for(Text value:values){
// 为了防止导致重复结果不输出,把每个结果作为key都输出出来
context.write(key, NullWritable.get());
}
}
}
JobMain
记得提前区创建hdfs文件路径和文件
package com.dongnaoedu.network.hadoop.mapreduce.sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Job job = Job.getInstance(super.getConf(), "mapReduce_sort");
//打包放在集群下运行,需要做一个配置
job.setJarByClass(JobMain.class);
// 第一步:设置读取文件的类:k1 v1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/input/sort"));
// 第二步:设置mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map阶段输出类型
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class);
// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)
// 第七步:设置Reduce类
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(PairWritable.class);
job.setOutputValueClass(NullWritable.class);
// 第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出路径
TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/out/out_sort"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
// 启动一个任务 run=0成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
运行结果
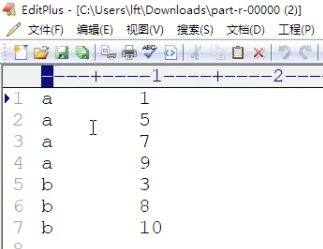
打成jar包后上传到集群任意一个节点服务器,使用hadoop命令运启动hadoop jar jar包名 cn.itcast.mapreduce——sort.JobMain,运行后控制台会输出一下信息,并在我们根目录创建out_sort文件夹,点进去就会有我们输出统 计结果文件。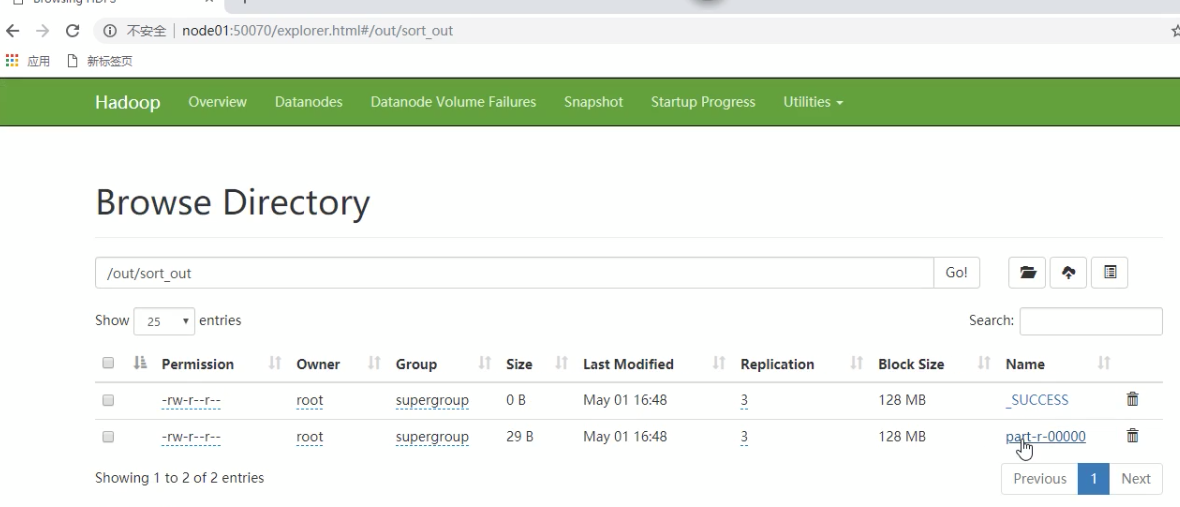

若有收获,就点个赞吧
0 人点赞
