计数器
计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。如果需要将日志信息传输到map或reduce阶段,更好的方法通常是看能否用一个计数值来记录某一特定的事件的发生。对于大型分布式作业而言,使用计数器更为方便,还有根据计数器值统计特定事件要比分析一堆日志容易的多。
hadoop内置计数器
| MapReduce任务计数器 | org.apache.hadoop.mapreduce.TaskCounter |
|---|---|
| 文件系统计数器 | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat 计数器 | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat 计数器 | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| 作业计数器 | org.apache.hadoop.mapreduce.JobCounter |
每次mapreduce执行完成之后,我们都会看到一些日志记录出来,其中最重要的一些日志记录如下截图: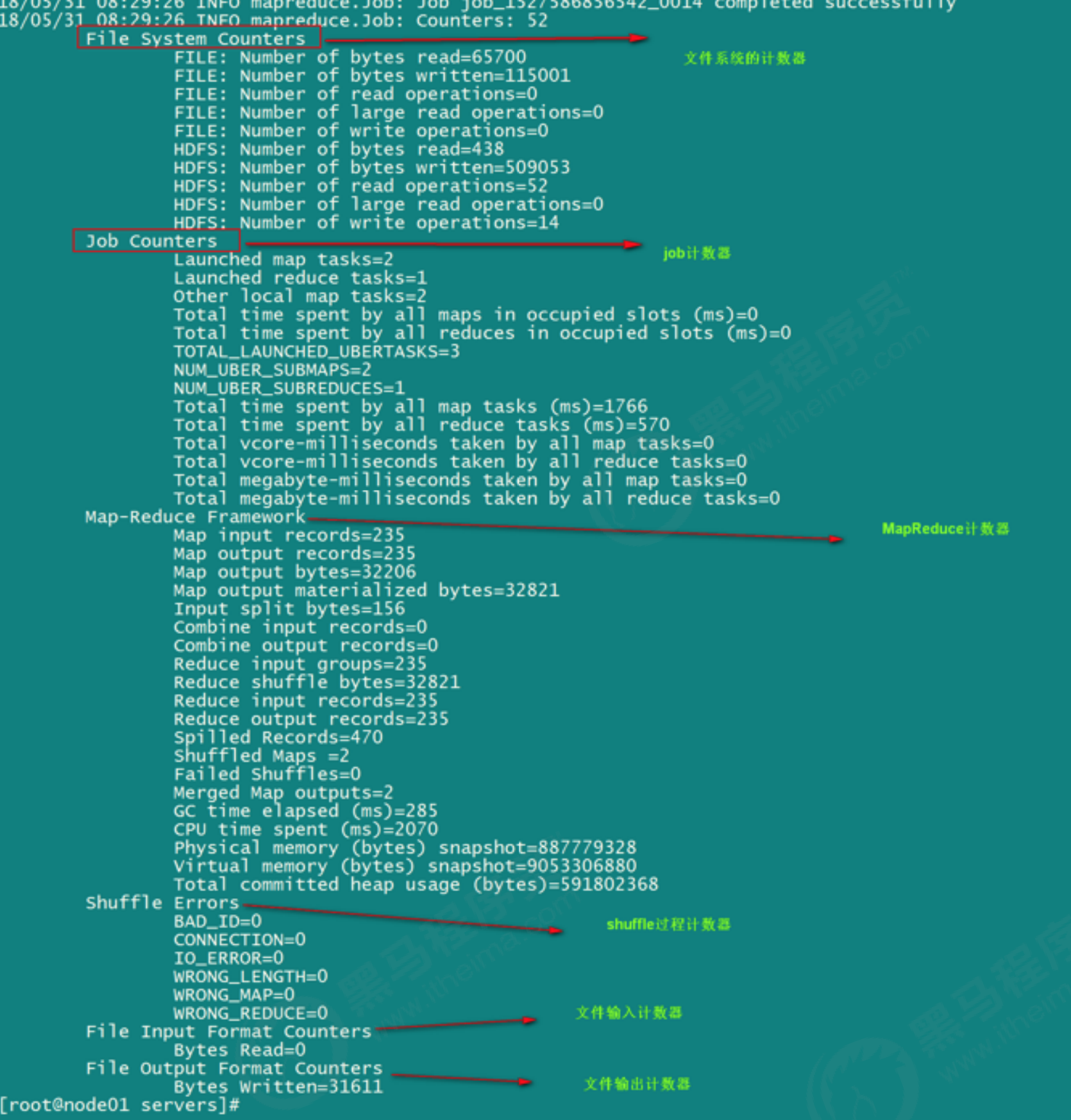
所有的这些都是MapReduce的计数器的功能,既然MapReduce当中有计数器的功能,我们如何实现自己的计数器???我们以上一篇排序案例举例,来统计map阶段接收到的数据记录条数
自定义计时器方式
第一种方式
通过context上下文对象可以获取到我们的计数器,进行记录通过context上下文对象,在map端使用计数统计。加上之后我们可以什么都不做,任务执行是计数器会在控制台输出体现
public class WordCountMapper extends Mapper<LongWritable,Text,PairWritable,Text>{@Overridepublic void map(LongWritable key, Text value, Mapper.Context context) throws IOException,InterruptedException{// 自定义计数器 第一个参数计数器的分类,第二个参数计时器分类的其中一个计数器Counter counter = context.getCounter("MR_COUNT", "MapRecueCounter");counter.increment(1L);// 对每一行数据进行拆分,然后封装到PairWritable对象中作为k2String[] split = value.toString().split("\t");PairWritable obj = new PairWritable();obj.setFirst(split[0]);obj.setSecond(Integer.parseInt(split[1]));//将k2和v2传递给contextcontext.write(obj,value);}}
第二种方式
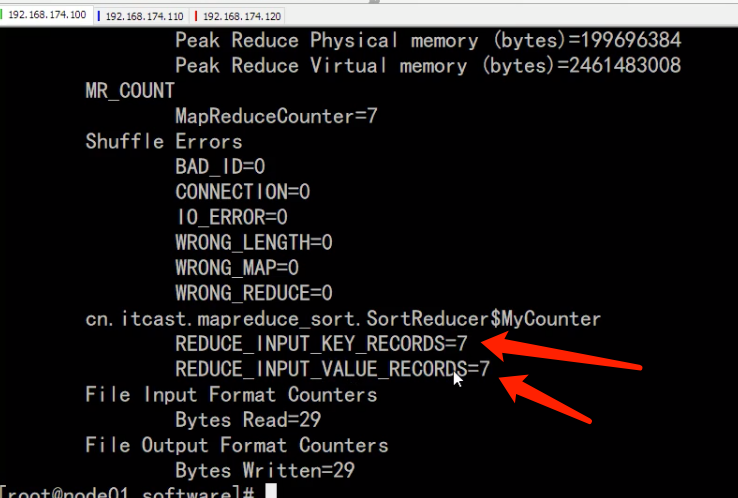
通过枚举方式定义计数器,这种情况是计数器类型比较多的时候用的比较多。统计reduce端数据的输入的key有多少个,对应的value有多少个。
public class SortReducer extends Reducer<PairWritable, Text,PairWritable, NullWritable> {
// 自定义计数器使用枚举方式创建
public static enum MyCounter{
REDUCE_INPUT_RECORDS,
RECUDE_INPUT_VAL_NUMS
}
@Override
protected void reduce(PairWritable key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
// 我们仅仅是将v2的值传给v3,然后定义v3为个占位符空对象
// context.write(key, NullWritable.get()); 这样写会存在问题,会把重复的值记录到集合中去
/**
* a 1
* a 1
* ==> a 1 <a 1,a 1>
*/
// 统计key个数
context.getCounter(MyCounter.REDUCE_INPUT_RECORDS).increment(1L);
for(Text value:values){
// 为了防止导致重复结果不输出,把每个结果作为key都输出出来
context.getCounter(MyCounter.RECUDE_INPUT_VAL_NUMS).increment(1L);
context.write(key, NullWritable.get());
}
}
}
mapTask运行机制
简要概述
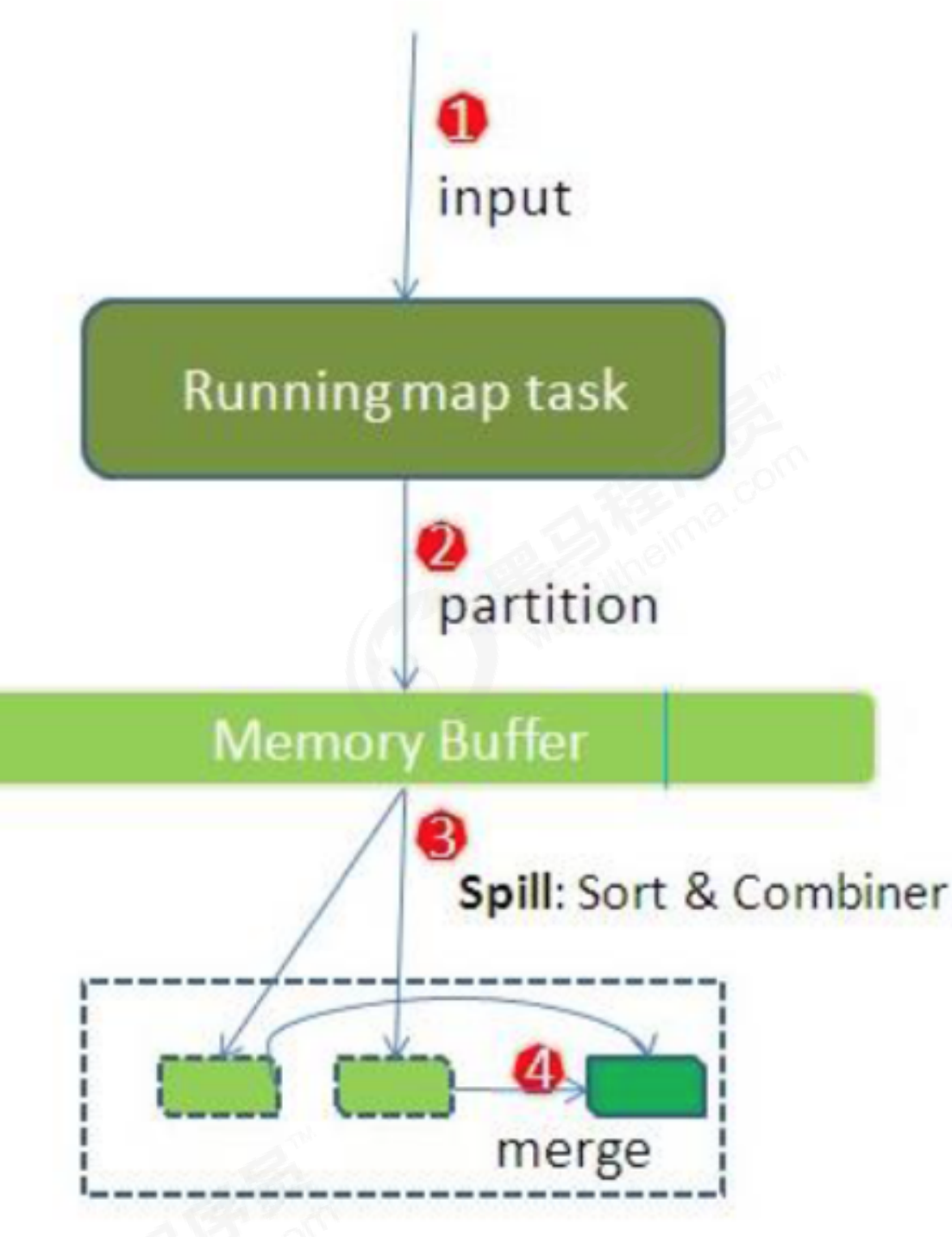
整个map阶段流程大体如上图所示:inputFile通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map处理结束之后交给OutputCollector收集器,对其结果key进行分区(默认使用hash分区),然后写入buffer,每个maptask都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个maptask结束后再对磁盘中这个maptask产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reducetask来拉。
详细步骤
- 1.读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,有多少个split就应启动多少个MapTask,split与block对应关系默认是1:1
- 将输入文件切分为splits之后,由RecordReader对象(默认是LineRecordReader)进行读取,以”\n“作为分隔符,读取一行数据,返回(key,value),key表示每行首字符的偏移值,valye表示这一行文本内容
- 读取split返回
- Mapper逻辑结束后,将Mapper的每条数据通过context.write进行collect数据收集,在collect中,会先对其进行分区处理,默认使用HashPartitioner
接下来会将数据写入到内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集Mapper结果,减少IO的影响,我们的key/value以及对Partition的结果都会被写入缓冲区,写入前key和value值都会被序列化成字节数组。
- 环形缓冲区其实是一个数组,数组中存放着key,value的序列化数据和Key,value的元数据信息。包括Partition,key的起始位置,value的起始位置以及value的长度,环形结构是一个抽象的概念
- 缓冲区是有大小限制的,默认是100M。当mapper的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区.这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写.这个溢写是由单独线程来完成,不影响往缓冲区写Mapper结果的线程.溢写线程启动时不应该阻止Mapper的结果输出,所以整个缓冲区有个溢写阈值的。spill.percent 这个比例默认是0.8,也就是当缓冲区的数据已经达到。buffer size spill percent = 100MB 0.8 = 80MB,溢写线程启动,锁定这80MB的内存,执行溢写过程。Mapper的输出结果还可以往剩下的20MB内存中写,互不影响
当溢写线程启动后,需要对这80MB空间内的Key做排序(Sort).排序是MapReduce。模型默认的行为,这里的排序也是对序列化的字节做的排序
- 如果Job设置过Combiner,那么现在就是使用Combiner的时候了.将有相同Key的Key/Value对的Value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用
- 那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果.Combiner只应该用于那种Reduce的输入Key/Value与输出Key/Value类型完全一致,且不影响最终结果的场景.比如累加,最大值等.Combiner的使用一定得慎重,如果用好,它对Job执行效率有帮助,反之会影响Reducer的最终结果
合并溢写文件,每次溢写会在磁盘上生成一个临时文件(写之前判断是否有Combiner),如果Mapper的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在.当整个数据处理结束之后开始对磁盘中的临时文件进行Merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量
# 设置环型缓冲区的内存值大小 mapreduce.task.io.sort.mb=100 # 设置溢写比例 mapreduce.map.sort.spill.percent=0.8 # 溢写数据目录 mapreduce.cluster.local.dir=${hadoop.tmp.dir}/mapred/local # 设置一次合并多少个溢写文件 mapreduce.task.io.sort.factor=10流量统计案例
案例一(流量统计)
统计每个手机号的上行数据包总和、下行数据包总和、上行流量总和,下行流量总和。
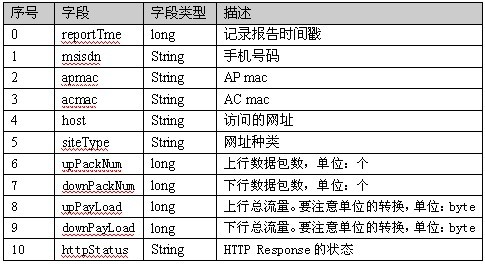
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 游戏娱乐 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 jd.com 京东购物 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 taobao.com 淘宝购物 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 cnblogs.com 技术门户 4 0 240 0 200 1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200 1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 未知 20 16 4116 1432 200 1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 sougou.com 综合门户 18 15 1116 954 200 1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200 1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 baidu.com 综合搜索 4 0 240 0 200 1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200 1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200 1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 zhilian.com 招聘门户 15 9 918 4938 200 1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 csdn.net 技术门户 3 3 180 180 200 1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200 1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 图片大全 12 12 3008 3720 200 1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200 1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200 1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200 1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 http://youku.com/ 视频网站 2 2 120 120 200 1363157985079 13823070001 20-7C-8F-70-68-1F:CMCC 120.196.100.99 img.qfc.cn 图片浏览 6 3 360 180 200 1363157985069 13600217502 00-1F-64-E2-E8-B1:CMCC 120.196.100.55 www.baidu.com 综合门户 18 138 1080 186852 200分析
以手机号码作为key值,上行流量上行数据包总和、下行数据包总和、上行流量总和,下行流量总和作为value。作为map阶段的输出,reduce阶段的输入。首先在v1阶段,拿到v1的值,然后将它拆分成以手机号作为k2和以所需参数对象FlowBean作为v2,然后根据sheullfe的特性,会自动把规约把v2变成v2集合,也就是新的v2,然后再到reduce阶段将各个flowbean对象参数累加即可。
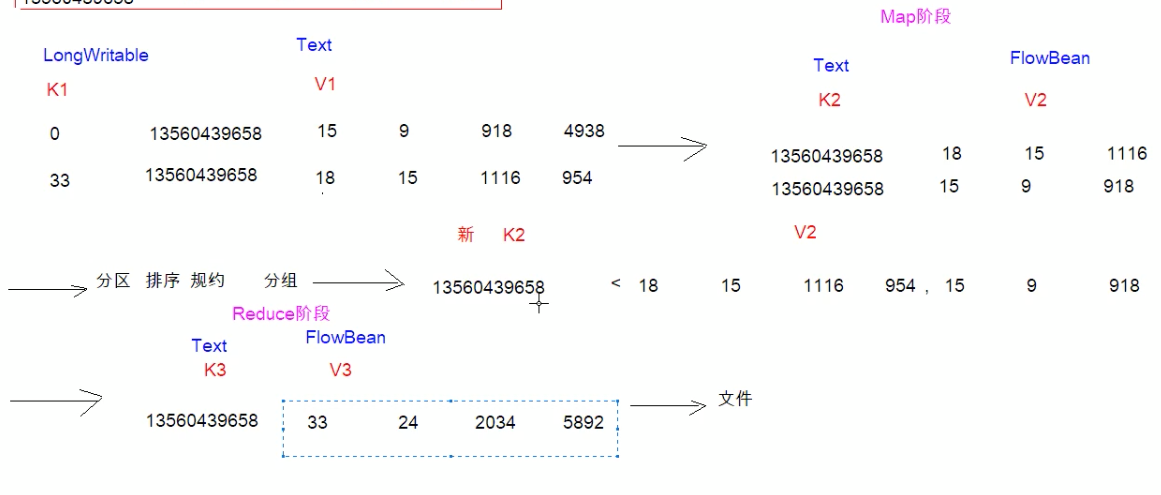

代码实现
FlowBean
package com.dongnaoedu.network.hadoop.mapreduce.flowcount;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Setter
@Getter
@ToString
public class FlowBean implements Writable {
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.upCountFlow = dataInput.readInt();
this.downCountFlow = dataInput.readInt();
}
}
FlowCountMapper
package com.dongnaoedu.network.hadoop.mapreduce.flowcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
public void map(LongWritable k1,Text v2,Context context) throws IOException,InterruptedException{
String[] split = v2.toString().split("\t");
String phoneNum = split[1];
FlowBean bean = new FlowBean();
bean.setUpFlow(Integer.parseInt(split[6]));
bean.setDownFlow(Integer.parseInt(split[7]));
bean.setUpCountFlow(Integer.parseInt(split[8]));
bean.setDownCountFlow(Integer.parseInt(split[9]));
// 将k2 v2传递给责任链
context.write(new Text(phoneNum),bean);
}
}
FlowCountReduce
package com.dongnaoedu.network.hadoop.mapreduce.flowcount;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReduce extends Reducer<Text,FlowBean, Text,FlowBean> {
@Override
protected void reduce(Text k2, Iterable<FlowBean> values, Context context) throws IOException,InterruptedException{
FlowBean bean = new FlowBean();
Integer upFlow = 0;
Integer downFlow = 0;
Integer upCountFlow = 0;
Integer downCountFlow = 0;
for (FlowBean value : values) {
upFlow += value.getUpFlow();
downFlow = value.getDownFlow();
upCountFlow = value.getUpCountFlow();
downCountFlow = value.getDownCountFlow();
}
bean.setUpFlow(upFlow);
bean.setDownFlow(downFlow);
bean.setUpCountFlow(upCountFlow);
bean.setDownCountFlow(downCountFlow);
context.write(k2,bean);
}
}
JobMain
package com.dongnaoedu.network.hadoop.mapreduce.flowcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Job job = Job.getInstance(super.getConf(), "mapReduce_flowCount");
//打包放在集群下运行,需要做一个配置
job.setJarByClass(JobMain.class);
// 第一步:设置读取文件的类:k1 v1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/input/flowcount"));
// 第二步:设置mapper类
job.setMapperClass(FlowCountMapper.class);
// 设置map阶段输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)
// 第七步:设置Reduce类
job.setReducerClass(FlowCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出路径,会自动创建
TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/out/flowcount"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
// 启动一个任务 run=0成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
运行结果
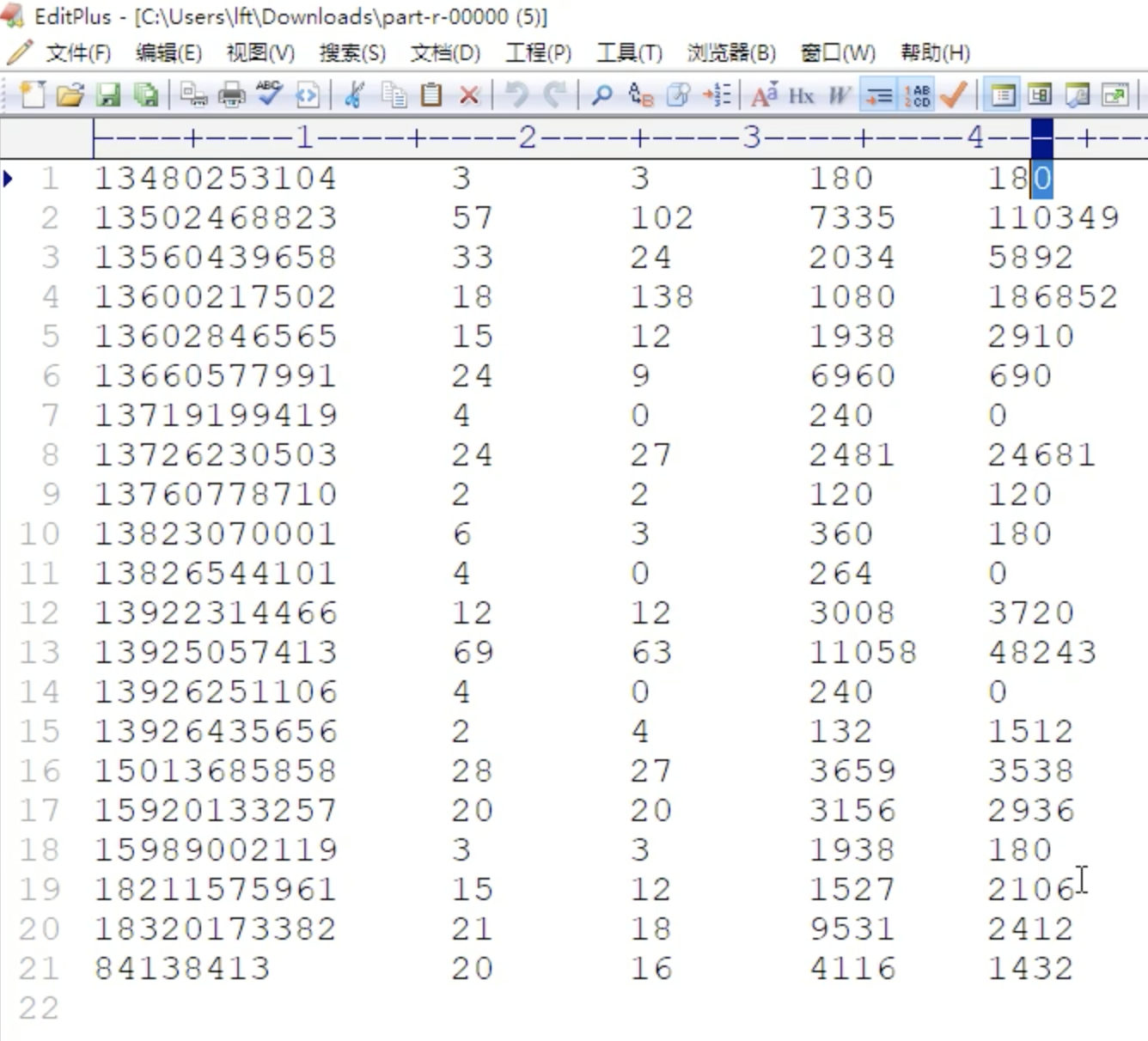
案例二(流量排序)
在上面输出后,以此为结果集在对 upFlow 也就是上行流量包进行排序。
代码实现
FlowSortBean
@Setter
@Getter
@ToString
public class FlowSortBean implements WritableComparable<FlowSortBean> {
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(upCountFlow);
dataOutput.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.upCountFlow = dataInput.readInt();
this.downCountFlow = dataInput.readInt();
}
@Override
public int compareTo(FlowSortBean o) {
// 按照升序 如果按照降序乘以-1
return this.getUpFlow().compareTo(o.getUpFlow())*(-1);
}
}
FlowCountSortMapper
public class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowSortBean, Text > {
@Override
public void map(LongWritable k1,Text v2,Context context) throws IOException,InterruptedException{
// 将k1 v1 ==> k2 v2
String[] split = v2.toString().split("\t");
// 手机号作为v2
String phoneNum = split[0];
FlowSortBean bean = new FlowSortBean();
bean.setUpFlow(Integer.parseInt(split[1]));
bean.setDownFlow(Integer.parseInt(split[2]));
bean.setUpCountFlow(Integer.parseInt(split[3]));
bean.setDownCountFlow(Integer.parseInt(split[4]));
// 将k2 v2传递给责任链
context.write(bean,new Text(phoneNum));
}
}
FlowSortCountReduce
package com.dongnaoedu.network.hadoop.mapreduce.flowcount.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowSortCountReduce extends Reducer<FlowSortBean, Text, Text,FlowSortBean> {
@Override
protected void reduce(FlowSortBean k2, Iterable<Text> v2, Context context) throws IOException,InterruptedException{
for (Text phone : v2) {
context.write(phone,k2);
}
}
}
JobMain
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Job job = Job.getInstance(super.getConf(), "mapReduce_flowCount");
//打包放在集群下运行,需要做一个配置
job.setJarByClass(JobMain.class);
// 第一步:设置读取文件的类:k1 v1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/input/flowcount"));
// 第二步:设置mapper类
job.setMapperClass(FlowCountMapper.class);
// 设置map阶段输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)
// 第七步:设置Reduce类
job.setReducerClass(FlowCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出路径,会自动创建
TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/out/flowcount"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
// 启动一个任务 run=0成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
运行结果

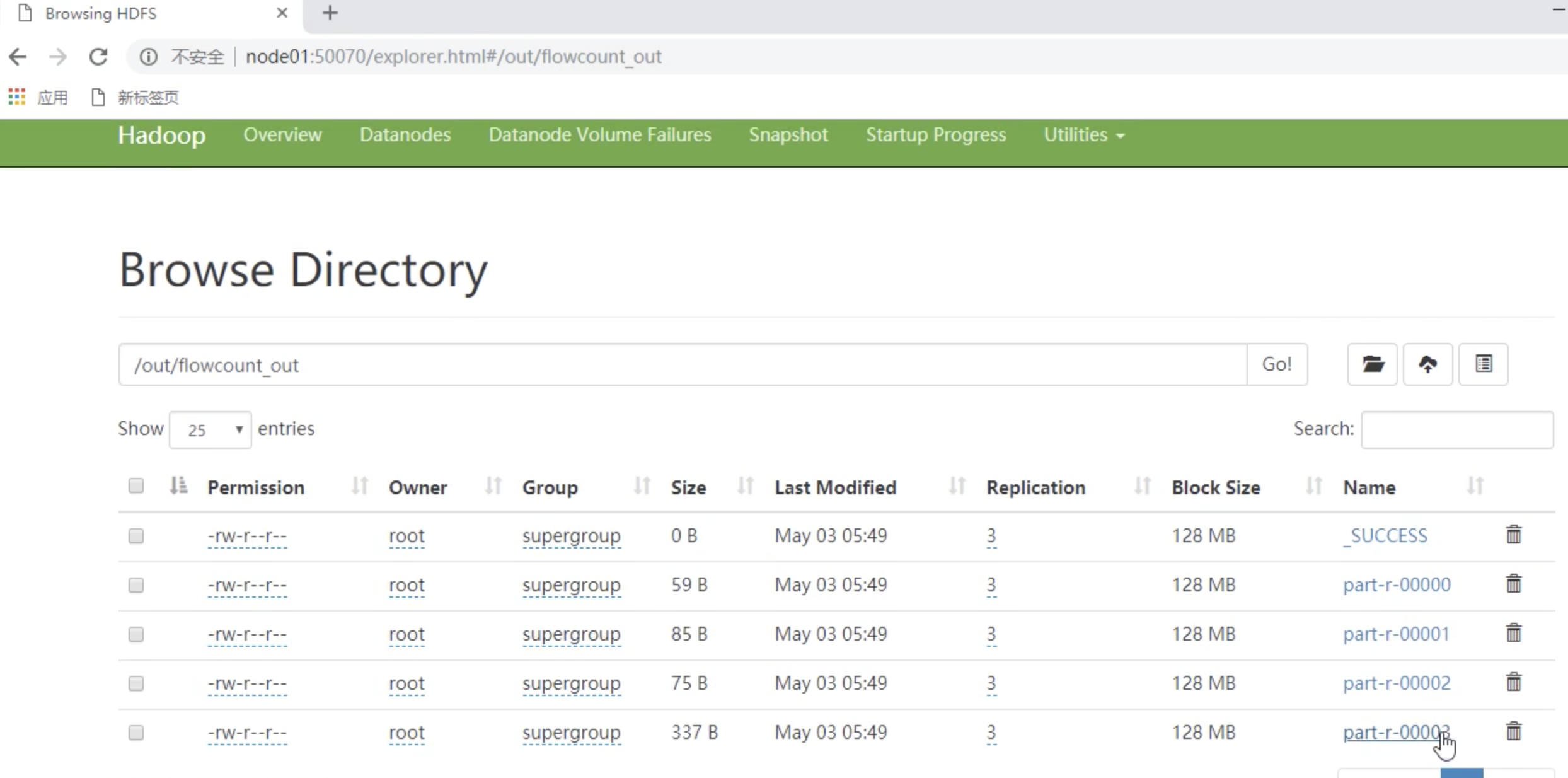
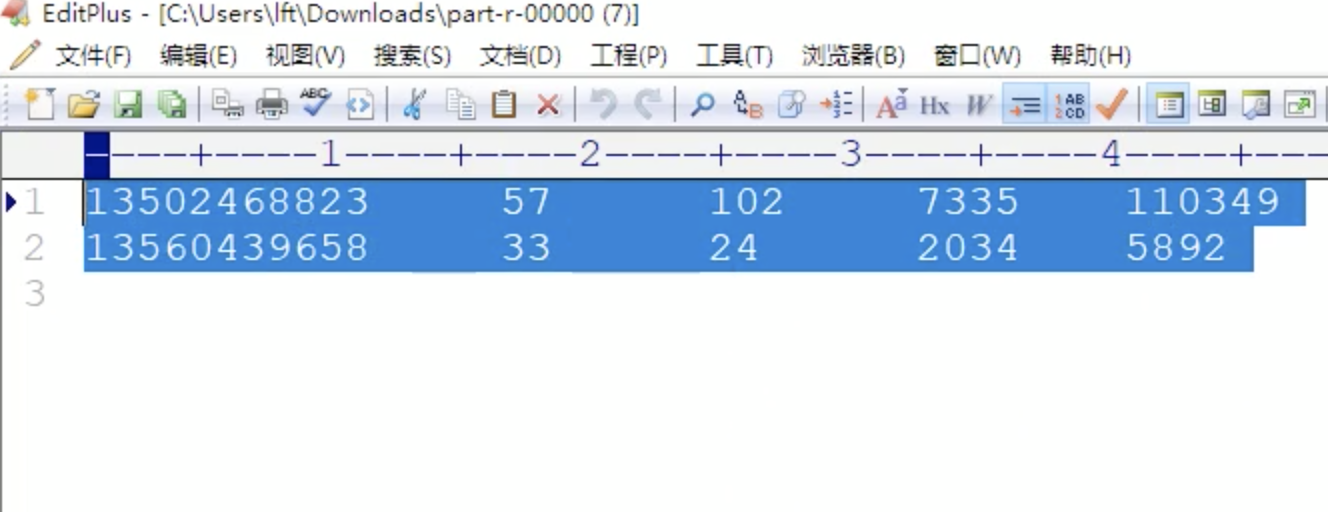
案例三(流量分区)
在案例一的需求上,将不同手机号的数据文件分到不同的数据文件当中去。也就是这样
135 开头的到一个分区文件
136 开头的到一个分区文件
137 开头的到一个分区文件
....
代码实现
FlowPartition
public class FlowPartition extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text k2, FlowBean flowBean, int i) {
if (k2.toString().startsWith("135")){
return 0;
}else if (k2.toString().startsWith("136")){
return 1;
}else if (k2.toString().startsWith("137")){
return 2;
}else {
return 3;
}
}
}
JobMain
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Job job = Job.getInstance(super.getConf(), "mapReduce_flowCount");
//打包放在集群下运行,需要做一个配置
job.setJarByClass(JobMain.class);
// 第一步:设置读取文件的类:k1 v1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/input/flowcount"));
// 第二步:设置mapper类
job.setMapperClass(FlowCountMapper.class);
// 设置map阶段输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)
job.setPartitionerClass(FlowPartition.class);
// 第七步:设置Reduce类
job.setReducerClass(FlowCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置reduce分区个数
job.setNumReduceTasks(4);
// 第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出路径,会自动创建,如果存在记得删除hdfs路径
TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/out/flowcount_out"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
// 启动一个任务 run=0成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
运行结果

若有收获,就点个赞吧
0 人点赞
