MapReduce编程规范
MapReduce的开发有八个阶段,其中Map阶段分为2个步骤,Shuffle阶段4个步骤,Reduce阶段分为2个步骤
Map的2个阶段
- 设置inputFormat类,将数据切分为k1和v1,输入到第二步
自定义map逻辑,将第一步的结果转换为另外的k2和v2,对结果进行输出
Shuffle(洗牌)的4个阶段
对输出的k2和v2进行分区
- 对不同分区的数据按照相同的key排序
- (可选)对分组过的数据初步规约,降低数据的网络拷贝
-
Reduce的2个阶段
对多个map任务结果进行排序以及合并,编写reduce函数实现自己的逻辑,对输入的key-value进行处理,转为新的key-value(k3和v3)
- 设置outputFaormat处理并保存reduce输出的key-value数据
案例
比如存在一个a.text,里面记录了一些各个单词,通过TextInputFormat组件读每一行数据(无需我们操作,组件自动完成) ,形成一个kv键值对数据,k为每个数据的偏移量,v为我们要记录的每行数据。(完成了第一步骤)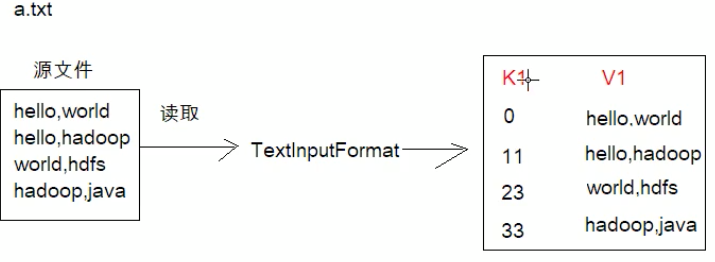
上述已经拿到k1和v1,现在要自定义有个Mapper类重写map方法,在map方法中将k1和v1转为k2和v2,至于转成什么样的,需要根据我们的业务逻辑。我们假设要统计源文件各个单词出现的次数。将v1读取到的数字按照“逗号”分割,将读取到的每个值变成k2 v2的形式,k2的值即为单词,v2可以理解为固定的值1。(完成了第二步骤)。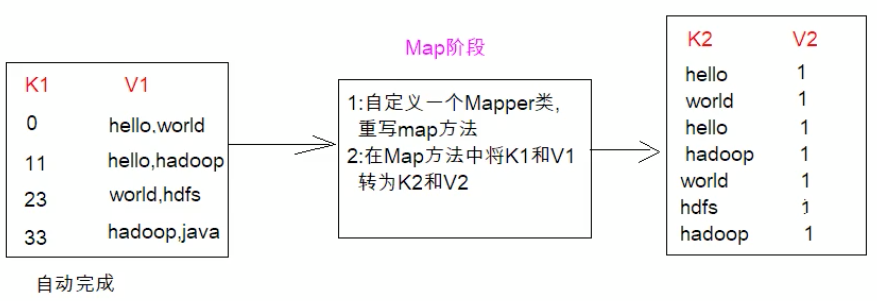
现在到了我们的shuffle阶段,它会陆续的进行分区、排序、规约、分组(java8 stream语法很多类似名词)。最终它会形成新的k2 v2,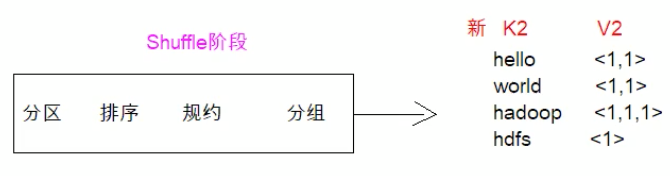
到了reduce阶段,肯定是要形成一个k3和v3,格式肯定是单词作为键值,出现次数肯定是出现的次数了,然后通过OutPutFormat的子类TextOutPutFormat,它会将我们的结果保存成文件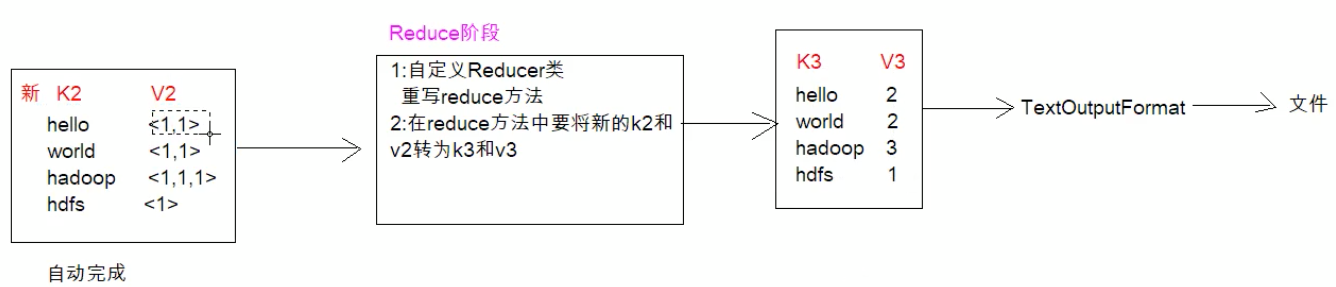
案例准备工作
创建一个新的文件
cd /export/serversvim wordcount.txt
向其中放入一下内容并保存
hello,world,hadoophive,sqoop,flume,hellokitty,tom,jerry,worldhadoop
上传到hdfs
hdfs dfs -mkdir /wordcount/ #在根目录创建文件夹hdfs dfs -put wordcount.txt /wordcount/ #在对应文件夹放入对应文件
代码阶段
map阶段方法
重点注意:Mapper的四个泛型对应着我们的k1 v1和k2 v2的泛型,复写的map方法中的参数key和value是我们k1和v1,然后转成k2和v2传递给context ```java package com.dongnaoedu.network.hadoop.mapreduce;
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper
<a name="F0nhH"></a>##### reduce方法重点注意:Reduce的四个泛型对应着我们的k2 v2和k3 v3的泛型,复写的reduce方法中传递第一个和第二个参数分别是我们的k2和一个集合(记录了v2的值,因为它是经过分组排序后的结果)```javapackage com.dongnaoedu.network.hadoop.mapreduce;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReduce extends Reducer<Text,LongWritable, Text,LongWritable> {/*** 自定义我们的reduce逻辑* 所有key都是我们的单词,所有的values都是我们单词出现的次数*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException,InterruptedException{long count = 0;for(LongWritable value : values){count += value.get();}context.write(key,new LongWritable(count));}}
定义主类,描述job并提交job
package com.dongnaoedu.network.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool{
@Override
public int run(String[] strings) throws Exception{
Job job = Job.getInstance(super.getConf(), "mapReduce_wordCount");
//打包放在集群下运行,需要做一个配置
job.setJarByClass(JobMain.class);
// 第一步:设置读取文件的类:k1 v1
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/wordcount"));
// 第二步:设置mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map阶段输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)
// 第七步:设置Reduce类
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 第八步:设置输出类
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出路径
TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/wordcount_cout"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
// 启动一个任务 run=0成功
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
- 打成jar包运行主程序
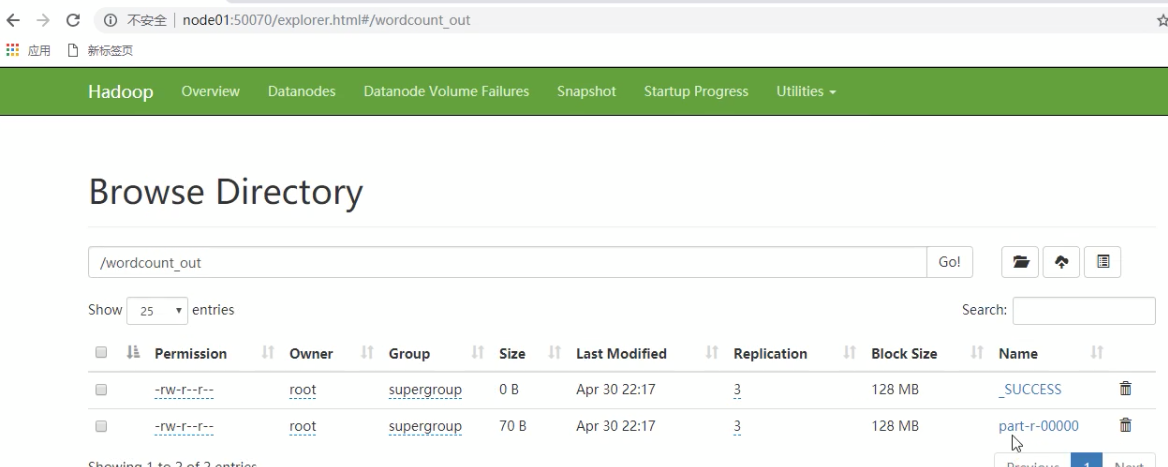
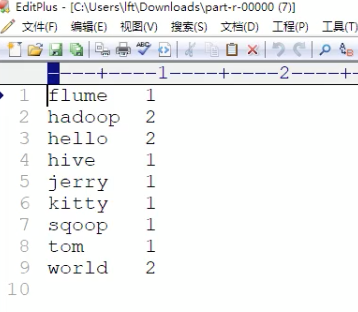
打成jar包后上传到集群任意一个节点服务器,使用hadoop命令运启动hadoop jar jar包名 cn.itcast.mapreduce.JobMain,运行后控制台会输出一下信息,并在我们根目录创建wordcount_cout文件夹,点进去就会有我们输出统 计结果文件


若有收获,就点个赞吧
0 人点赞
