在上一篇我们的一个案例中,我们对出现单词的各个统计进行了mapreduce的入门学习,其中重要的两个步骤就是对map阶段和reduce阶段进行了代码的编写。但是在shuffle阶段使用了默认的分区、排序、规约、分组。在我们工作当中应该更多的是将不同的分区交给不同的reduce,从而产生不同的结果。
在MapReduce中,通过我们指定的分区,会将同一个分区的数据发送到同一个reduce当中去处理。例如:为了数据的统计,可以把一批类似的数据发送到同一个reduce当中,在同一个reduce当中统计相同类型的数据,就可以实现类似的数据分区和统计等。其实就死相同的类型数据,有共性的数据送到一起出来,reduce当中默认的分区只有一个。
单词统计任务拓展
还是跟上篇案例类似,假设有个a.txt文件300M,在单词统计的基础上要求对单词长度>=5放到一个结果集,<5放到另外一个结果集。此时的reduceTask就不是下图这个了,而是存在两个reduceTask,也就是说同一个分区的数据会放到同一个reduce,同一个reduce会产生一个文件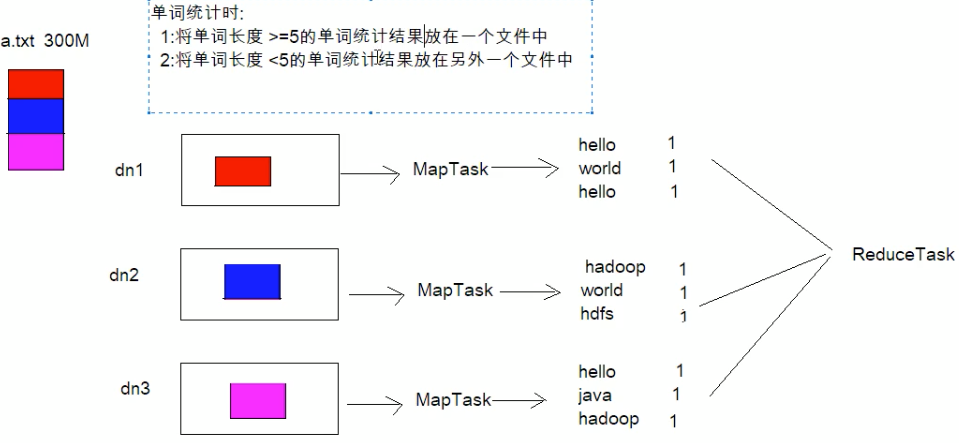
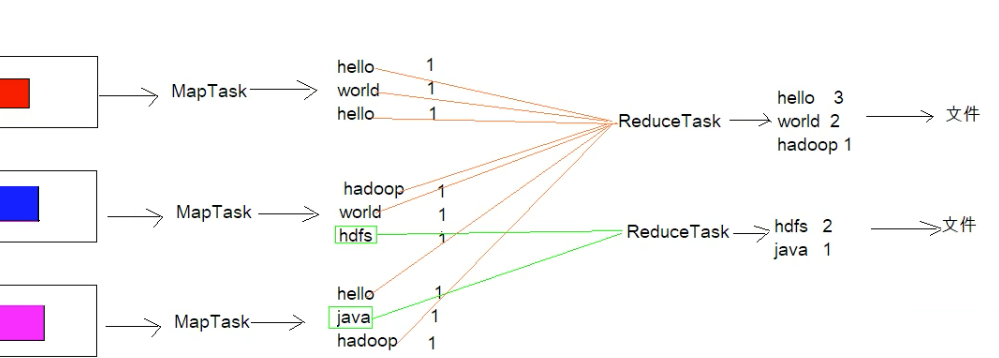
代码实现
新增PartitionerOwn类
要实现分区必须要重写Partitioner,然后自定义我们的分区规则
package com.dongnaoedu.network.hadoop.mapreduce.partition;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Partitioner;public class PartitionerOwn extends Partitioner<Text, LongWritable>{/*** text:表示k2* longWritable:表示v2* i:reduce个数*/@Overridepublic int getPartition(Text text,LongWritable longWritable,int i) {// 如果单词的长度>=5进入第一个分区==>第一个reduceTask==>reduce编号是0if(text.toString().length() >= 5){return 0;}else{// 如果长度<5,进入第二个分区==>第二个reduceTask==>reduce编号是1return 1;}}}
主方法设置分区代码
package com.dongnaoedu.network.hadoop.mapreduce.partition;import com.dongnaoedu.network.hadoop.mapreduce.WordCountMapper;import com.dongnaoedu.network.hadoop.mapreduce.WordCountReduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class JobMain extends Configured implements Tool{@Overridepublic int run(String[] strings) throws Exception{Job job = Job.getInstance(super.getConf(), "mapReduce_wordCount");//打包放在集群下运行,需要做一个配置job.setJarByClass(JobMain.class);// 第一步:设置读取文件的类:k1 v1job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job, new Path("hdfs://node01:8082/wordcount"));// 第二步:设置mapper类job.setMapperClass(WordCountMapper.class);// 设置map阶段输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 第三 四 五 六步采用默认方式(分区 排序 规约 分组)// 设置我们的分区类job.setPartitionerClass(PartitionerOwn.class);// 第七步:设置Reduce类job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 设置reduce的个数jjob.setNumReduceTasks(2);// 第八步:设置输出类job.setOutputFormatClass(TextOutputFormat.class);// 设置输出路径TextOutputFormat.setOutputPath(job, new Path("hafs://node01:8082/wordcount_cout"));boolean b = job.waitForCompletion(true);return b ? 0:1;}public static void main(String[] args) throws Exception{Configuration configuration = new Configuration();// 启动一个任务 run=0成功int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}}
运行结果
查看我们的hdfs结果,会发现有两个文件,编号为0的就是我们长度>=5(第一个分区),编号为1的就是我们长度<5的(第二个分区)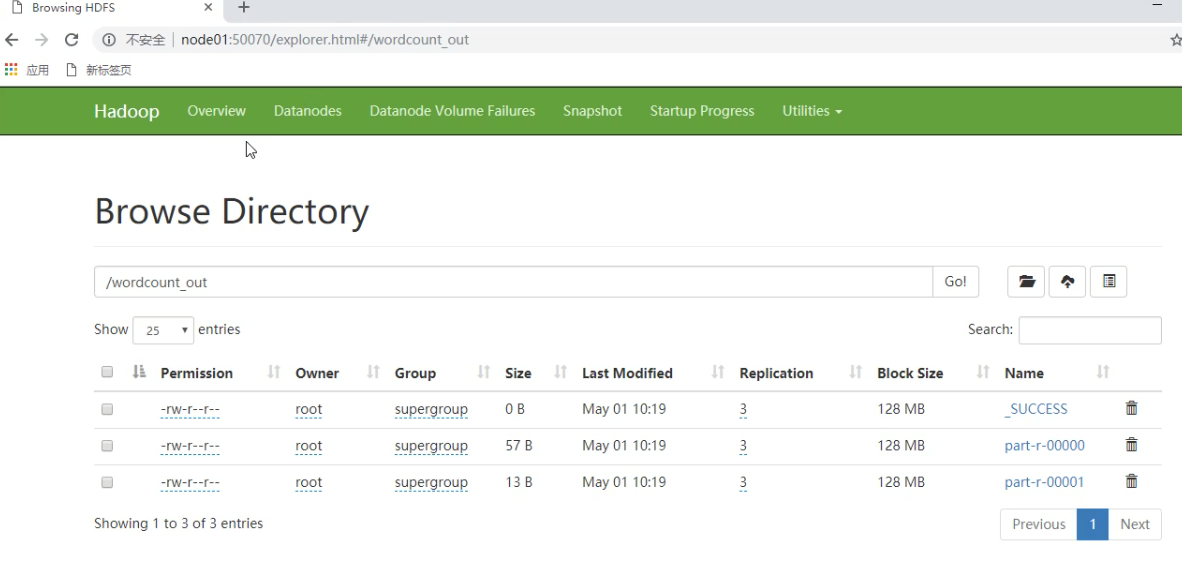

若有收获,就点个赞吧
0 人点赞
