预备
Redis 不是万金油,有些数据结构和命令必须在特定情况下使用。一旦使用不当可能对 Redis 本身或者应用本身造成致命伤害。
全局命令
查看所有键
$ keys *
键总数
返回当前数据库中所有键的总数,不会遍历所有键,而是直接获取 Redis 内置的键总数变量,而 keys 会遍历所有键,线上环境禁止使用 keys。
$ dbsize
检查键是否存在
$ exists java
删除键
$ del java # 删除一个键$ del a b c # 删除多个键
键过期
$ expire hello 10
ttl 命令会返回键的过期时间,它有 3 种返回值:
- 大于等于 0 的整数:键的剩余时间
- -1:键没设置过期时间
- -2:键不存在
$ ttl hello
键的数据结构类型
$ type a
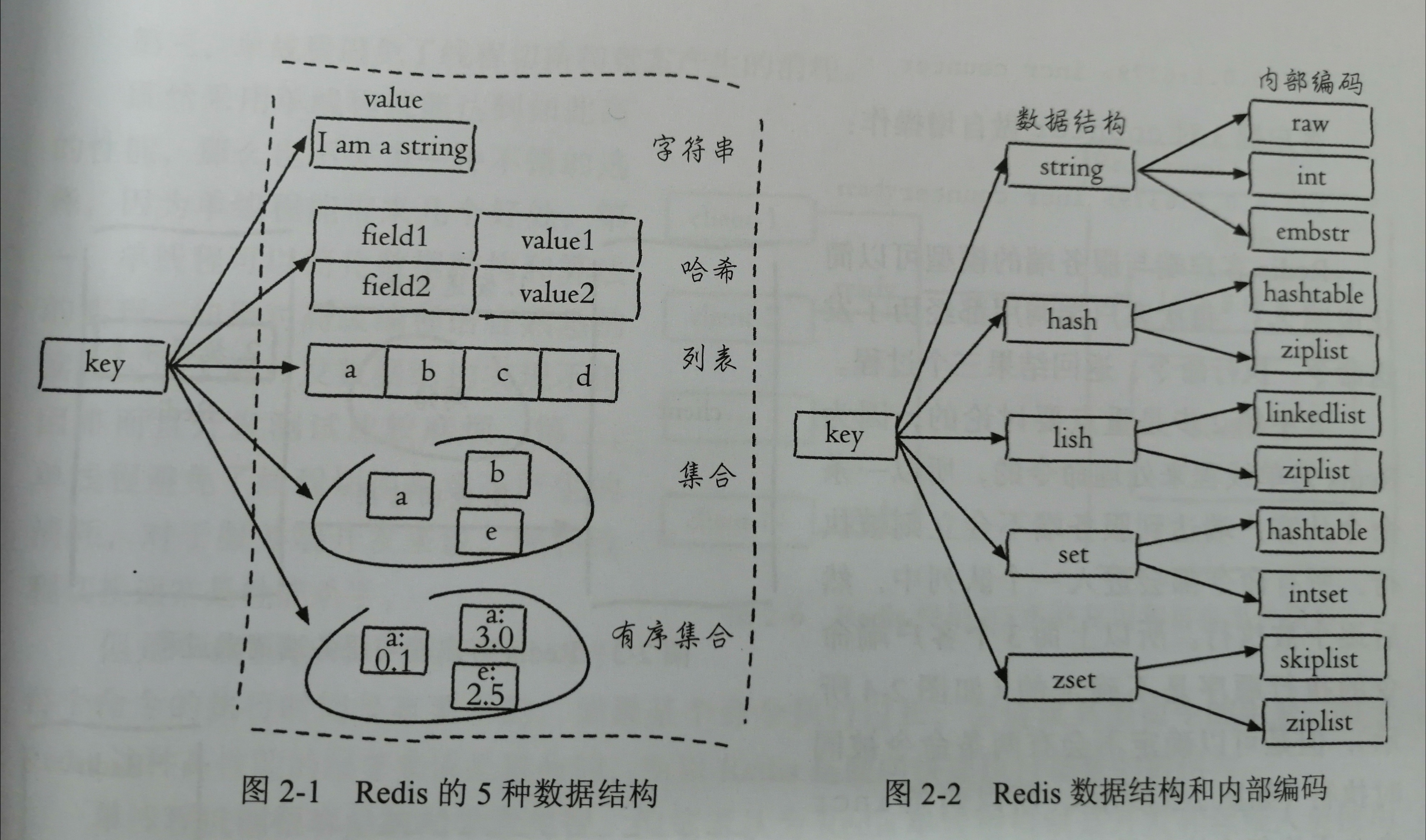
数据结构和内部编码
每种数据结构都有两种以上的内部编码实现,这样 Redis 会在合适的场景下选择适合的编码。
查询内部编码
$ object encoding hello
单线程架构
单线程模型
每次客户端调用都经历了发送命令、执行命令、返回结果这三个过程。
因为 Redis 是单线程的,每个命令不会立即执行,而是放到执行队列中逐个被执行,命令的执行顺序不确定。
为什么单线程还能这么快
- 纯内存访问
- 非阻塞 I/O
- 单线程避免了线程切换和竞争产生的消耗
字符串
命令
设置值
设置值有几种选项:
ex seconds:设置秒级过期时间px millisecond:设置毫秒级过期时间nx:键必须不存在,才能设置,用于添加xx:键必须存在,才能设置,用于更新- 除了
set选项还提供了setex和setnx命令
$ set hello world$ setnx hello world$ set hello world nx$ set hello world xx
获取值
$ get hello
批量设置值
$ mset a 1 b 2 c 3 d 4
批量获取值
使用批量操作,有助于提高业务处理效率,但是注意的是批量操作的数量不是无节制的,如果数量过多可能造成 Redis 阻塞或者网络阻塞。
$ mget a b c d
计数
incr 命令用于对值做自增操作,返回结果分为三种情况:
- 值不是整数,返回错误。
- 值是整数,返回递增后的结果。
- 键不存在,按照值为 0 自增,返回结果为 1。
$ incr key
decr 自增、incrby 自增指定数、decrby 自减指定数、incrbyfloat 自增浮点数
不常用命令
追加值
$ append key value
字符串长度
$ strlen key
设置并返回原值
$ getset hello world
设置指定位置的字符
$ setrange redis 0 b
获取部分字符串
$ getrange redis 0 1
内部编码
字符串内部编码有三种:
- int:8 个字节的长整型
- embstr:小于等于 39 个字符的字符串
- raw:大于 39 个字符的字符串
典型使用场景
- 缓存
- 计数
- 共享 Session
- 限速:限制手机号接口获得频率,例如一分钟不超过 5 次。
键名的命名
推荐使用 业务名:对象名:id:[属性] 作为键名。
哈希
命令
设置值
为 user:1 添加一对 field-value
$ hset user:1 name tom
获取值
$ gset user:1 name
删除值
$ hdel user:1 name
计算 field 个数
$ hlen user:1
批量设置或者获取 field-value
$ hmset user:1 name mike age 12 city tianjin$ hmget user:1 name city
判断 filed 是否存在
$ hexists user:1 name
获取所有 key
$ hkeys user:1
获取所有的 field-value
使用 hgetall 时,如果哈希元素过多,或存在阻塞 Redis 的可能。如果只需要获得一部分的 field,可以使用 hmget,一定获得全部使用 hscan。
$ hgetall user:1
hincrby hincrbyfloat
$ hincrby key field
计算 value 的字符长度
$ hstrlen user:1 name
内部编码
- ziplist(压缩列表):节省内存比 hashtable 更加优秀,value 大于 64 字节或者 field 个数大于 512 会变成 hashtable。
- hashtable(哈希表)
使用场景
哈希类型和关系型数据库有两点不同:
- 哈希类型是稀疏的,而关系数据库是完全结构化的。
- 关系型数据库可以做复杂的查询操作,而 Redis 去模拟复杂查询开发困难,维护成本高。
列表
命令
插入操作
从右边插入元素
$ rpush listkey c b a
从左边插入元素
$ lpush key value [value ...]
向某个元素前或者后插入元素
$ linsert key before| after pivot value$ linsert listkey before b java
查找
获取指定范围内的元素列表
lrange 中的 end 包含自身
$ lrange key start end$ lrange listkey 1 3
获取列表指定下标的元素
$ lindex listkey -1
获取列表长度
$ llen listkey
删除
从列表左侧弹出元素
$ lpop listkey
从列表右侧弹出元素
$ rpop listkey
删除指定元素: lrem key count value
- count>0,从左到右,删除最多 count 个元素
- count<0,从右向左,删除最多 count 绝对值个元素
- count=0,删除所有元素
删除第四个为 a 的元素
$ lrem listkey 4 a
按照索引范围修剪列表,只保留列表 listkey 第 2 个到第 4 个元素:
$ ltrim listkey 1 3
修改
参考
【1】Redis 开发与运维@付磊 张益军

若有收获,就点个赞吧
0 人点赞
