静态查找(重点)
顺序查找
基本思路
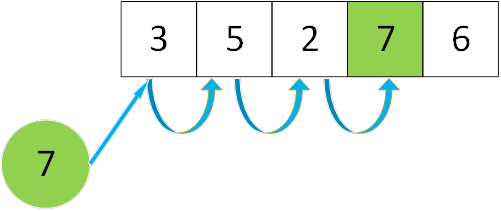
从数据的第一个元素开始,依次比较,直到找到目标数据或查找失败:
- 从表中的第一个元素开始,依次与关键字比较。
- 若某个元素匹配关键字,则查找成功。
- 若查找到最后一个元素还未匹配关键字,则查找失败。
时间复杂度
顺序查找平均关键字匹配次数为表长的一半,其时间复杂度为O(n)。
优缺点
优点:对于待查的结构没有任何要求,而且算法非常简单,当待查表中的记录个数较少时,采用顺序查找较好,顺序查找既适用于顺序存储结构,又使用于链接存储结构。
缺点:时间复杂度较大,数据规模较大时效率较低。
代码实现
#include <stdio.h>int seq_search(int array[], int n, int key){int i;for(i = 0; i < n; i++){if(key == array[i]){return i; //查找成功}}return -1; //查找失败}int main(){int array[] = {3, 5, 2, 7, 6};int num = 7;int len = sizeof(array) / sizeof(int);int index = seq_search(array, len, num);if(-1 != index){printf("%d的位置为%d\n", num, index);}else{printf("没有找到此元素");}return 0;}
折半查找
基本思路
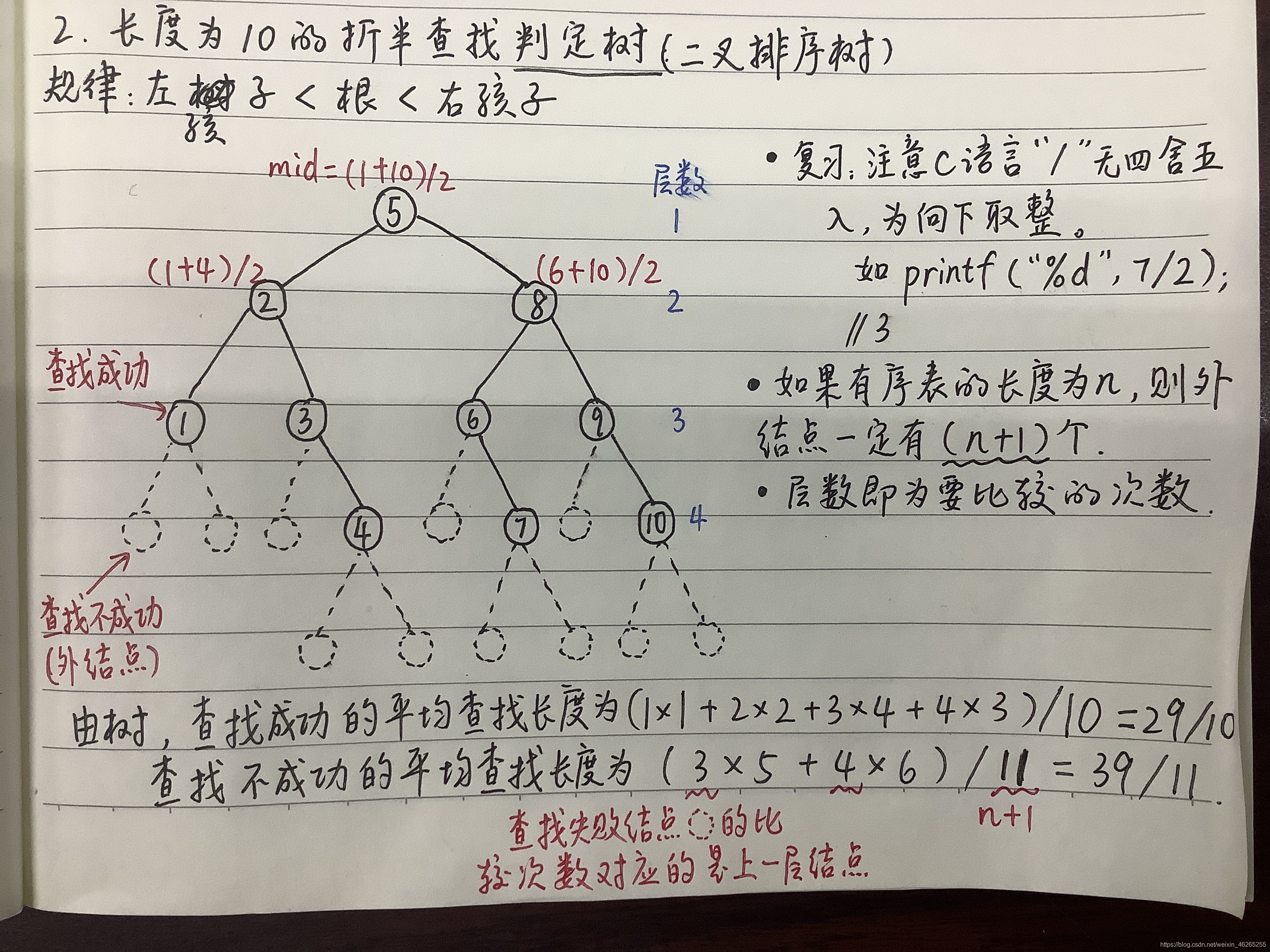
- 首先确定整个查找区间的中间位置 mid = ( left + right )/ 2
用待查关键字值与中间位置的关键字值进行比较;
若相等,则查找成功
若大于,则在后(右)半个区域继续进行折半查找
若小于,则在前(左)半个区域继续进行折半查找对确定的缩小区域再按折半公式,重复上述步骤。
最后,得到结果:要么查找成功, 要么查找失败。折半查找的存储结构采用一维数组存放。
优缺点
优点:比较次数少,查找速度快,平均性能好。
缺点:要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
判断树
是一棵平衡二叉树,也是一棵二叉排序树,高度⌈log(n+1)⌉,中序遍历是一个有序序列。
2,4,5,7,15,24,30,42,54,63,72,87,95的折半查找判定树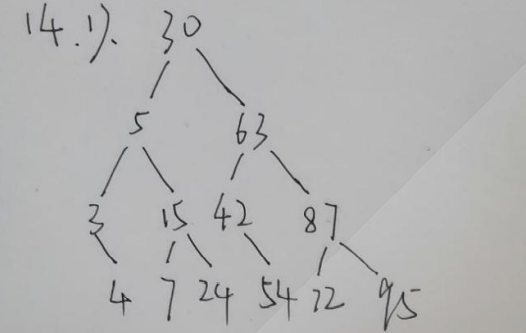
不成功的查找
平均查找长度
log(n)
分块查找
又称索引顺序查找,它是顺序查找的一种改进方法。
基本思路
将 n 个数据元素“按块有序”划分为 m 块(m<=n)。每一块中的数据元素不必有序,但块与块之间必须“按块有序”,即第 1 块中的任一元素的关键字都必须小于第 2 块中任一元素的关键字;而第 2 块中任一元素又都小于第 3 块中的任一元素,图示分块如下:
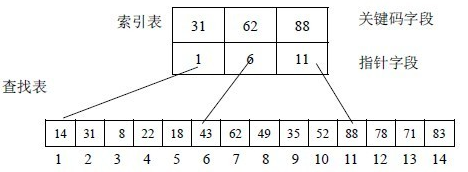
(分块查找实例)
- 先选取各块中的最大关键字构成一个索引表
- 查找分两部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后在已确定的块中用顺序法进行查找。
分块查找平均查找长度:
设长度为 n 的表均匀地分成 b 块,每块含有 s 个记录,则 b=n/s;
顺序查找所在块,分块查找的平均查找长度 = (b+1)/2 + (s+1)/2 = (n/s+s)/2+1;
折半查找所在块,分块查找的平均查找长度 = log2(n/s+1)+s/2;
优缺点
优点:在表中插入或删除一个记录时,只要找到该记录所在块,就在该块中进行插入或删除运算(因快内无序,所以不需要大量移动记录)。
缺点:增加了一个辅助数组的存储空间和将初始表分块排序的运算。
性能:介于顺序查找和二分查找之间。
平均查找长度

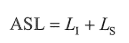

代码实现
#include <stdio.h>#include <stdlib.h>#define MAX 3#define MAXSIZE 18typedef int ElemType;typedef struct IndexItem{ElemType index;int start;int length;}IndexItem;IndexItem indexlist[MAX];ElemType MainList[MAXSIZE] = {22, 12, 13, 8, 9, 20, 33, 42, 44, 38, 24, 48, 60, 58, 74, 49, 86, 53};int sequential(IndexItem indexlist[], ElemType key){int index;if(indexlist[0].index >= key) return 1;for(index = 1; index <= MAX; index++){if((indexlist[index-1].index < key)&&(indexlist[index].index >= key))return index+1;}return 0;}int mainsequential(ElemType MainList[], int index, ElemType key){int i, num=0;for(i = 0; i < index-1; i++){num += indexlist[i].length;}for(i = num; i < num+indexlist[index-1].length; i++){if(MainList[i] == key) return i+1;}return -1;}int main(void){indexlist[0].index = 22;indexlist[0].start = 1;indexlist[0].length = 6;indexlist[1].index = 48;indexlist[1].start = 7;indexlist[1].length = 6;indexlist[2].index = 86;indexlist[2].start = 13;indexlist[2].length = 6;int index = sequential(indexlist, 38);printf("index = %d.\n", index);int mainindex = mainsequential(MainList, index, 38);printf("mainindex = %d.\n", mainindex);return 0;}
动态查找表(重点)
二叉排序树(识记)
又称为二叉搜索树
基本性质
具有以下性质的树称为二叉排序树:
- 若它的左子树不为空,左子树上所有的结点的值都小于它的根结点的值。
- 若它的右子树不为空,则右子树上所有结点的值均大于它的结点的值。
- 它的左右子树都为二叉排序树
用途
构造二叉排序树不是为了排序,而是提高查找删除的效率。
平均查找长度
n*logn
平衡二叉树(AVL 树)
概念
平衡二叉树是基于二分法的策略提高数据的查找速度的二叉树的数据结构;
特点
平衡二叉树是采用二分法思维把数据按规则组装成一个树形结构的数据,用这个树形结构的数据减少无关数据的检索,大大的提升了数据检索的速度;平衡二叉树的数据结构组装过程有以下规则:
- 非叶子节点只能允许最多两个子节点存在。
- 每一个非叶子节点数据分布规则为左边的子节点小当前节点的值,右边的子节点大于当前节点的值(这里值是基于自己的算法规则而定的,比如hash值);
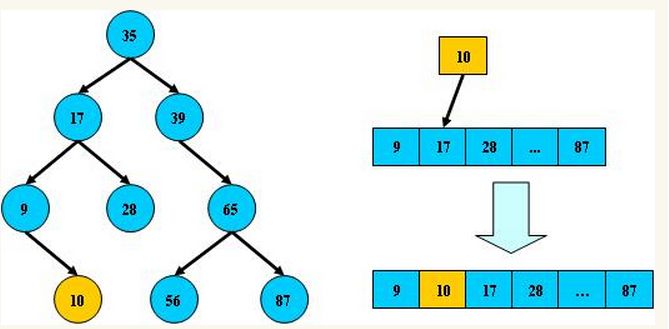
平衡树的层级结构:因为平衡二叉树查询性能和树的层级(h高度)成反比,h值越小查询越快、为了保证树的结构左右两端数据大致平衡降低二叉树的查询难度一般会采用一种算法机制实现节点数据结构的平衡,实现了这种算法的有比如AVL、Treap、红黑树,使用平衡二叉树能保证数据的左右两边的节点层级相差不会大于1.,通过这样避免树形结构由于删除增加变成线性链表影响查询效率,保证数据平衡的情况下查找数据的速度近于二分法查找;
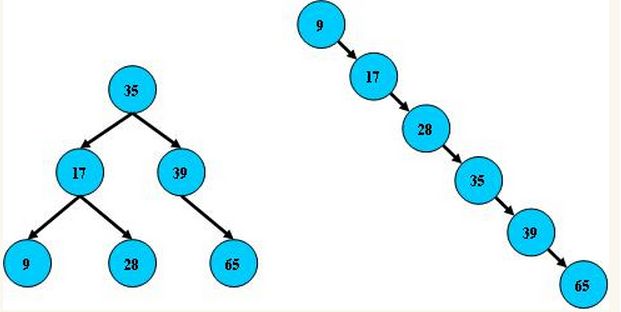
总结平衡二叉树特点:
- 非叶子节点最多拥有两个子节点;
- 非叶子节值大于左边子节点、小于右边子节点;
- 树的左右两边的层级数相差不会大于1;
- 没有值相等重复的节点;
B 树
B 树 和 B-tree 这两个是同一种树
概念
B 树也称 B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
规则
一颗m阶的B树定义如下:
- 每个结点最多有m棵子树,即最多有m-1个关键字。
- 根结点最少可以只有1个关键字。
- 非根结点至少有Math.ceil(m/2)-1个关键字,至少有Math.ceil(m/2)个子树。
- 每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
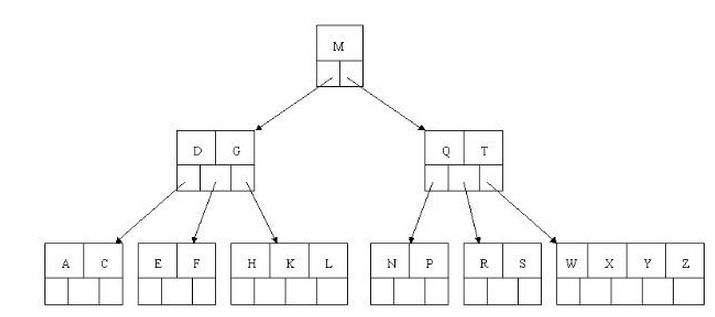
B树的查询流程
如上图我要从上图中找到E字母,查找流程如下
(1)获取根节点的关键字进行比较,当前根节点关键字为M,E
B树的插入节点流程
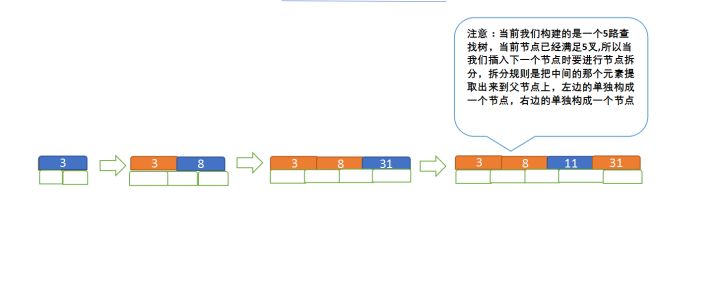
定义一个5阶树(平衡5路查找树;),现在我们要把3、8、31、11、23、29、50、28 这些数字构建出一个5阶树出来;
遵循规则:
(1)节点拆分规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须<=5-1(这里关键字数>4就要进行节点拆分);
(2)排序规则:满足节点本身比左边节点大,比右边节点小的排序规则;
先插入 3、8、31、11
再插入23、29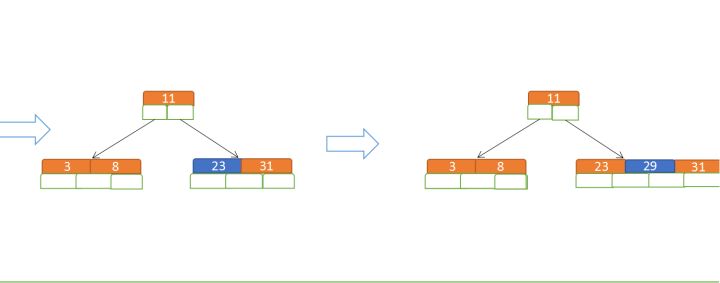
再插入50、28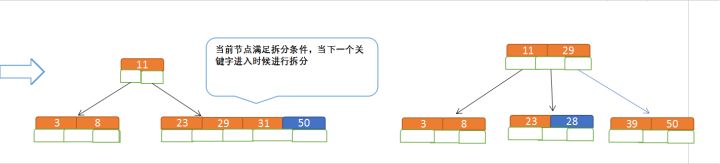
B树节点的删除
规则
(1)节点合并规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须大于等于ceil(5/2)(这里关键字数<2就要进行节点合并);
(2)满足节点本身比左边节点大,比右边节点小的排序规则;
(3)关键字数小于二时先从子节点取,子节点没有符合条件时就向向父节点取,取中间值往父节点放;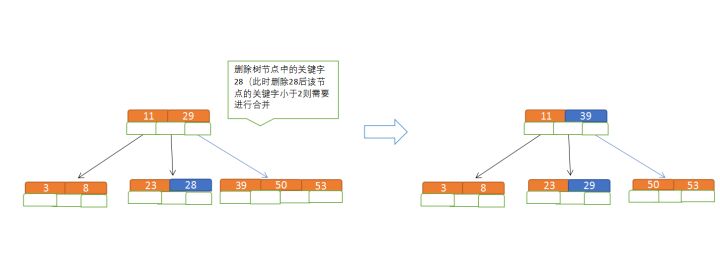
特点
B 树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在 B 树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
B+ 树
概念
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说B+树查找的效率要比B树更高、更稳定;我们先看看两者的区别
规则
- B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
- B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
- B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
- 非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);
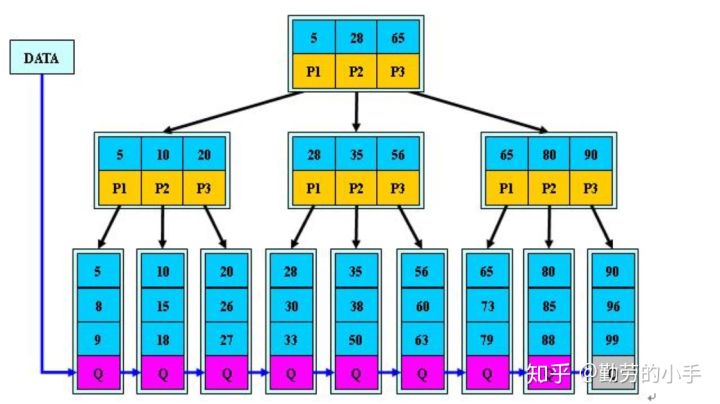
(百度百科算法结构示意图)
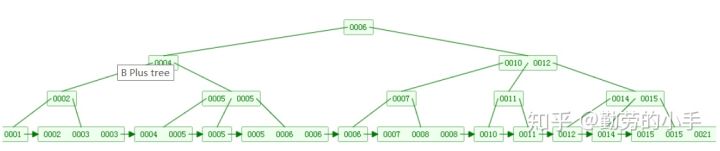
(维基百科算法结构示意图)
特点
- B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
- B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
- B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
- B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
2-3 树
2-3-4 树
键树
哈希表(重点)
定义
散列技术是在记录存储位置和它的关键字之间建立一个明确的对应关系 f,使得每个关键字 key 对应一个存储位置 f(key)。查询时,根据这个确定的对应关系找到给定值的映射 f(key),若查找集合中存在这个记录,则必定在 f(key)的位置上。我们把这种对应关系称为散列函数,又称为哈希函数。按照这个思想将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或者哈希表。
散列表的查找步骤
- 在储存时,通过散列函数计算记录的散列地址,按这个散列地址存储该记录。
- 当查找记录时,通过同样的散列函数计算出散列地址,按该地址记录访问该记录。
散列函数的构造方法
除留余数法
对于散列表长为 m 的散列函数公式为: f(key) = key mod p(p<=m) 。p 通常为大于或者等于表长(最好接近 m)的最小质数或者不包含小于 20 质因子的合数。
处理散列表冲突的方法
开放定址法(线性探测法)
一旦发生了冲突,就寻找下一个空的散列地址,将记录存入。
链地址法(拉链法)
链接地址法的思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第 i 个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
装填因子
装填因子:a=n/m 其中 n 为关键字个数,m 为表长。
加载因子是表示 Hsah 表中元素的填满的程度。若加载因子越大,填满的元素越多,空间利用率高了,但冲突的机会加大了。反之,加载因子越小,填满的元素越少,冲突的机会减小了,但空间浪费多了。冲突的机会越大,则查找的成本越高。反之,查找的成本越小。因而查找时间就越小。
因此必须在 “冲突的机会”与”空间利用率”之间寻找一种平衡与折衷。这种平衡与折衷本质上是数据结构中有名的”时-空”矛盾的平衡与折衷。
平均查找长度
Σ每个元素的查找次数 ➗ 元素个数
参考

若有收获,就点个赞吧
0 人点赞
