Precise Detection in Densely Packed Scenes.pdf
商超检测冠军 - A Solution for Product Detection in Densely Packed Scenes.pdf
商超检测亚军 - 2ND PLACE SOLUTION TO PRODUCT DETECTION IN DENSELY PACKED SCENES.pdf
Task Introduction
检测超市展示的商品(非常密集),基于 SKU-110K 数据集,也就是第一个PDF——《Precise detection in densely packedscenes》。
顾名思义,SKU-110K 包含了11张个密集商品的图片,分为3个部分:
- 训练集共8233张图片,占70%,共有 1,210,431 个 bounding box
- 验证集588张图片(5%)
- 测试集2941张
评价度量:和COCO类似
冠军方案
Pipeline
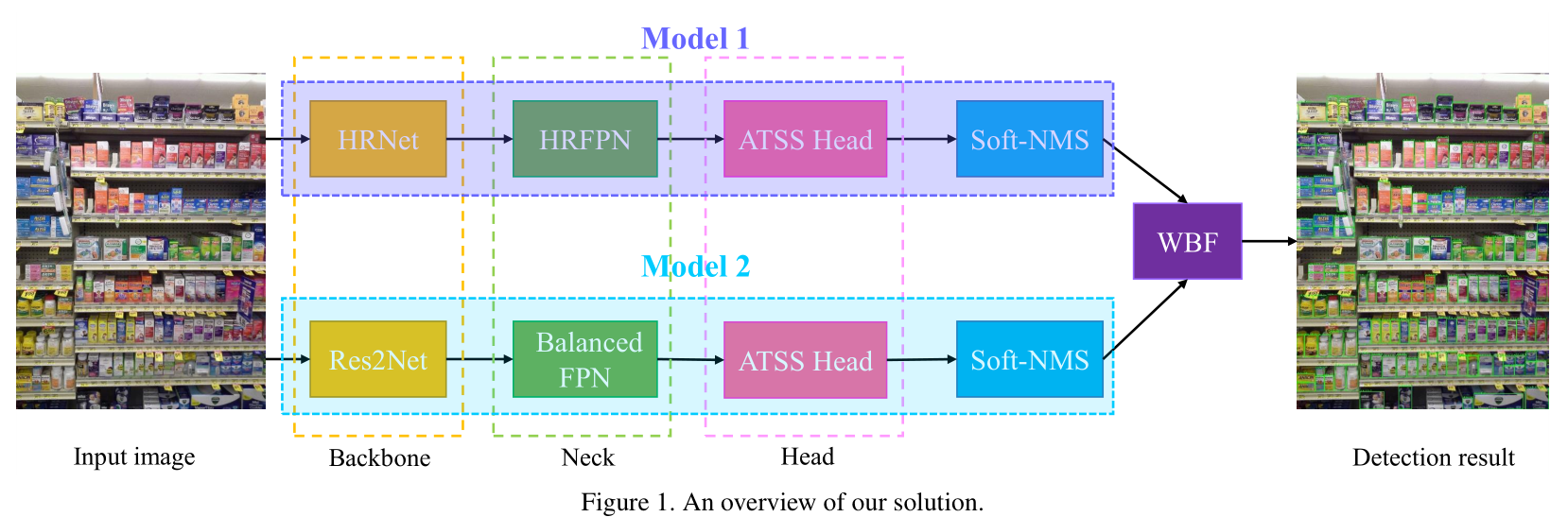
ensemble
他们使用 Weighted Boxes Fusion (WBF) 融合了两个 model 的 bounding boxes。
model1 和 model2 的权重比为 2:1
两个模型的区别在于 backbone 和 neck.
neck 就是连接 backbone 和 detection head 的那一部分。
model1
ATSS
- centerness branch
- regression branch
- classification branch
- GroupNorm
- trainable scalar for each level feature pyramid
detection head
每个模型的 detection head 都是用了 Adaptive Training Sample Selection (ATSS) ,它可以根据对象的统计特性自动选择正样本和负样本。
loss
- regression loss: DIoU loss
- classification loss: Focal loss
Configuration
- 输入图片裁剪到 1333*800
- SGD: 0.9 momentum & 0.0001 weight decay
- 4 GPUs
- 24 epochs
- learning rate: 0.0025
- decrease it by 0.1 after 16 and 22 epochs
- 使用 Synchronized BN 替换 BN
Result
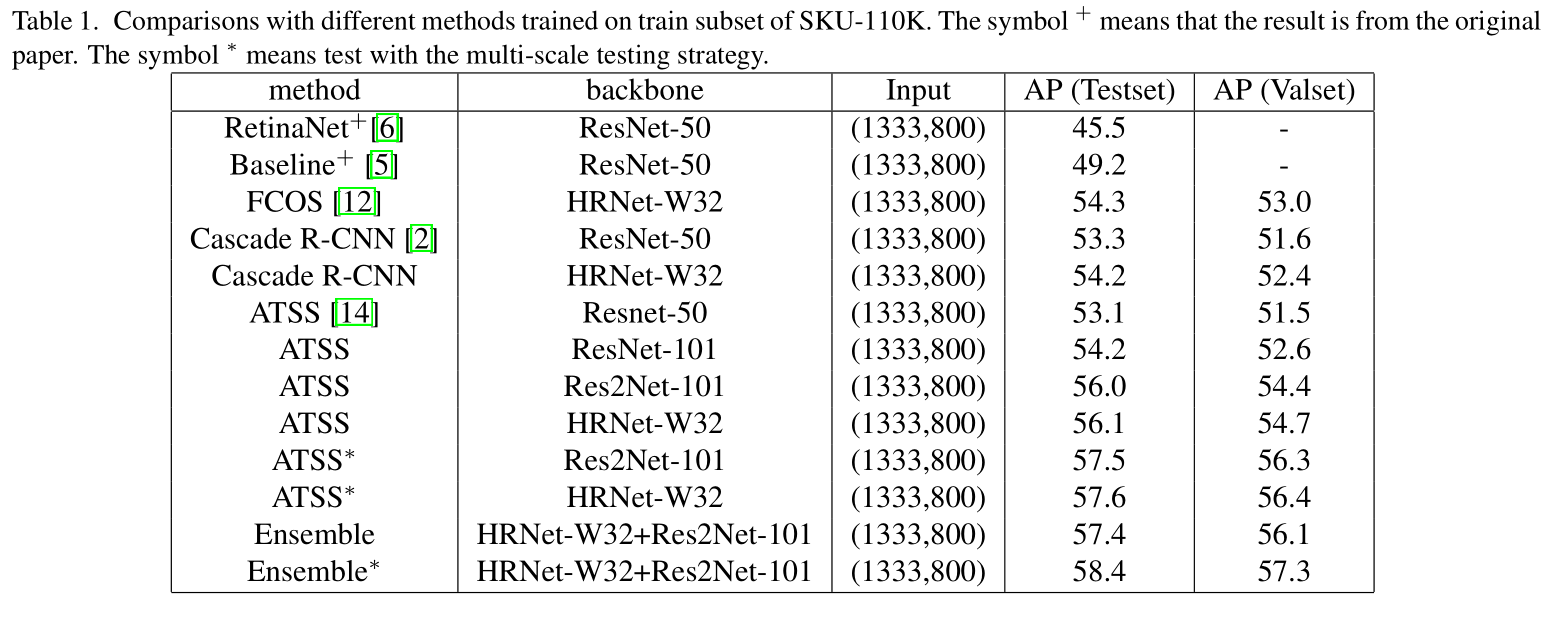
Model1 的AP能达到56.1,Model2 的AP能达到56.0,这已经比 Cascade R-CNN 好了。
把两个模型 ensemble 起来,能达到58.4
亚军方案
数据观察
作者先考察了训练集的图片大小分布: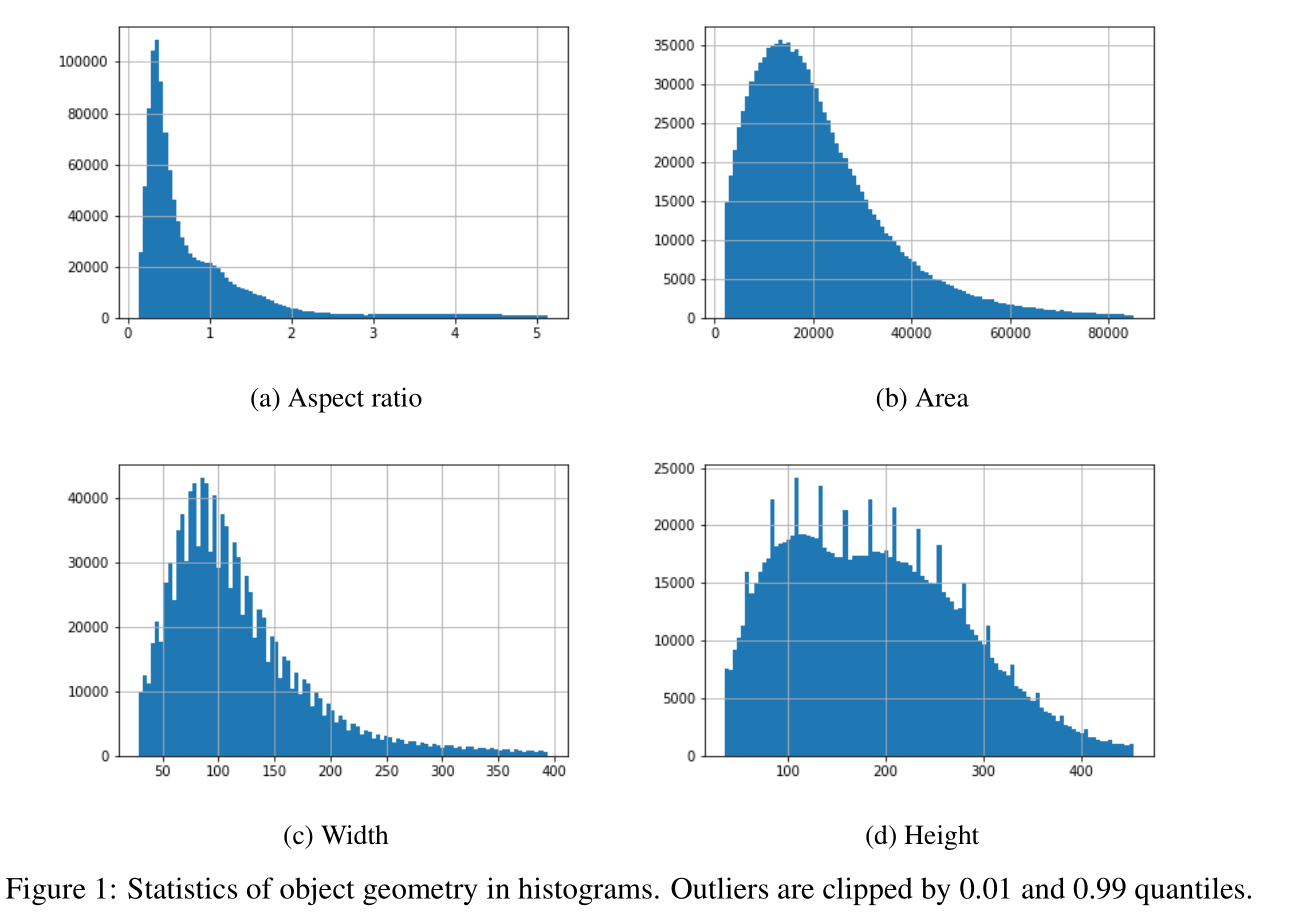
图片主要分为这个几个大小:
- 2448x3264 - 3463 images
- 1920x2560 - 1710 images
- 2336x4160 and 2340x4160- 1133 images
此外,COCO数据集中,”small”, “medium” and “large” 目标占比为 0.12%/18.53%/81.35%
而该数据集中,对应占比为18.64%/80.27%/1.09%,大目标是很少的。
模型比较
作者打算选取 RetinaNet 和 Faster-RCNN 作为 baseline solutions。
于是需要先对这两个模型进行比较:
预处理
- 将图片 resize 到 1333x800,同时不改变横纵比
- “1x”表示训练 12 个epoch
- “RandomFlip” 指训练时以0.5的概率随机将图片翻转,实现 image augmentation
- 评估度量使用COCO标准
结果
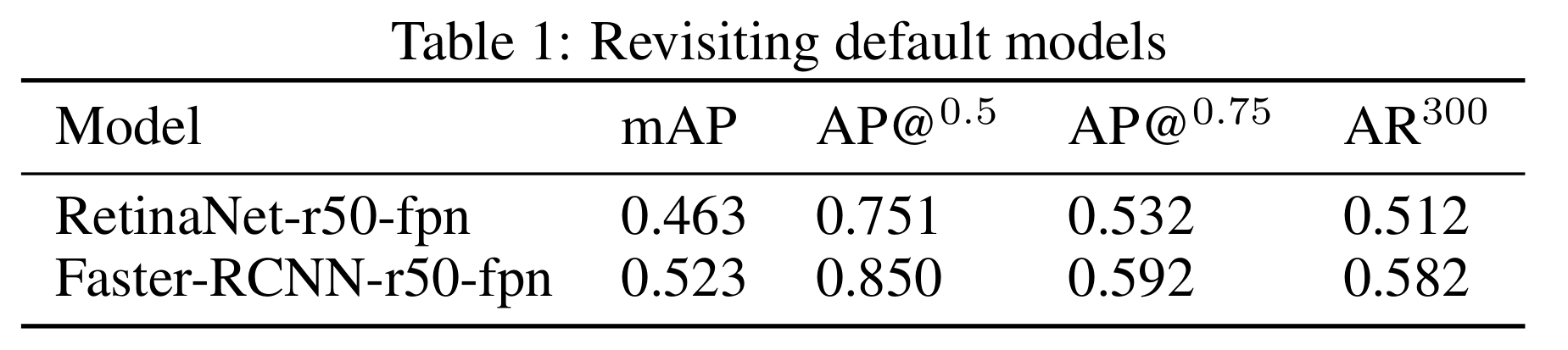
发现 Faster-RCNN 比 RetinaNet 强一些
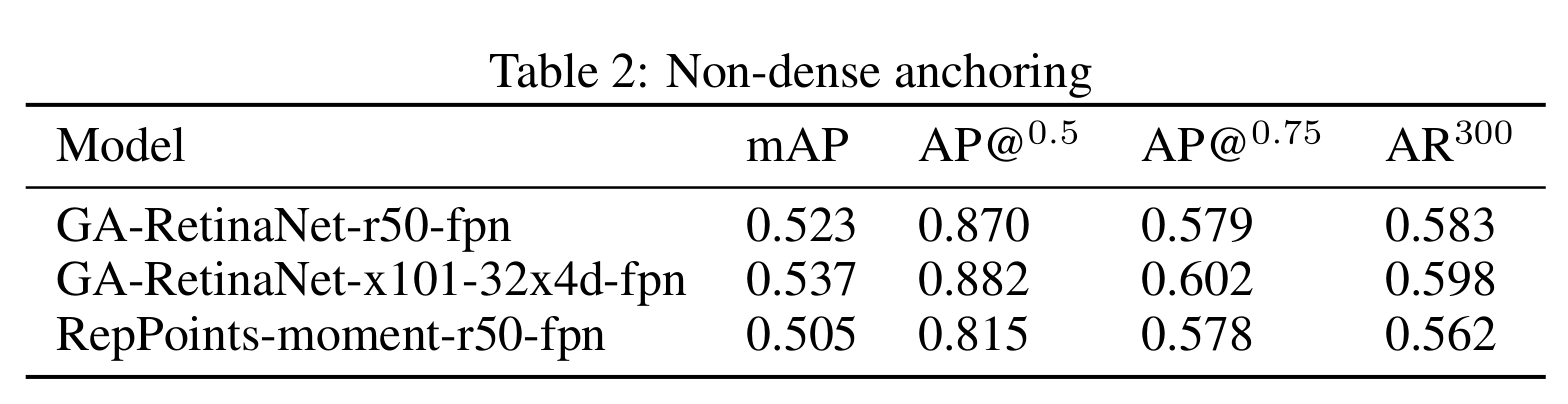
Anchor 法的比较
作者还比较了 Anchor 对训练的影响:
- 他先测试了 Guided Anchoring 方法,发现 GA-RetinaNet-r50-fpn 几乎达到了 Faster-RCNN 的性能
- 然后使用了 RepPoints-moment-r50-fpn,这是一个 Anchor free 方法,比较弱。
Scale相关的tricks
MMDetection 中的 Faster-RCNN 对 Anchor 的大小进行了预设:
但是该数据集中,大目标是非常稀少的,因此作者将 Anchor 的预设大小修改成 : .
.
效果对比如下:
作者还测试了一些其他的tricks,但都效果不大
还测试了不同的 Cascade-RCNN
发现以 ResNeXt-101 为backbone 的 Cascade-RCNN 效果最好.
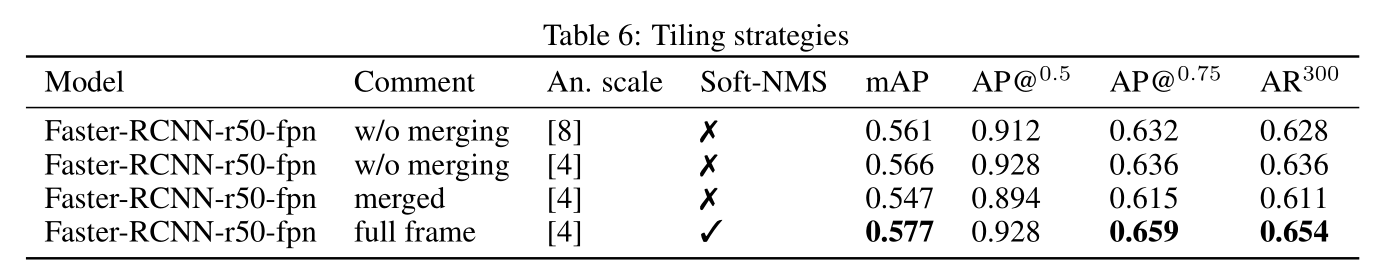
Tiling strategies
Image tiling 是一个针对小目标检测的技巧,在高分辨率图片中,小物体的检测非常困难,Image tiling是将图片裁剪成4张小图片以提升小物体的检测效果。
使用之后,效果明显。
Image tiling as a trick for object detection for large images with small objects on them was previously explored in [ 13 ]. Following the proposed method 2x2 tiling grid was chosen with 20% intersection between consecutive tiles. Keeping in mind dense object location bounding box annotations of objects with residual area less than 20% of the original were removed. In their work [ 13 ] proposed to also take a full frame for merging detectors. Although it might seem helpful for “large” objects, I’d like to emphasize that we almost never have those, so this option seems redundant. Hence, I decided to test the two following approaches:
- Tile-combine . In this scenario each image in train and test parts of the dataset is split into 4 tiles. Appropriate annotations are created. During test time inference is run on each tile and the results are saved into a JSON file.
Then the results are manually merged. Duplicated objects on overlapping areas are resolved by NMS.
- Train-time tiling . Here the model on 4 tiles is trained. Test-time inference is run using a 4 times larger resolution. The last one is possible because we do not have to store gradients in the test time.
Tile-combine seemed promising when evaluating on tiles (w/o merging), but the metrics dramatically decreased for full frames after combining the results (merged). I also tried to resolve multiple bounding boxes on tiles edges by NMS providing normalized areas instead of probability scores from the detector, which did not improve the score. Obviously when image tiling is applied ‘anchor_scale‘ parameter becomes much less important. Finally, train-time tiling and applying detection on a full frame with 1632x2176 resize showed the best results and I used this configuration for final training. See Table 6.
最终方案
- Faster-RCNN-r50-fpn
- anchor_scale = [4]
- resizing to 1632x2176
- Soft-NMS
- No TTA or ensembling

若有收获,就点个赞吧
0 人点赞
