前言
VGG的名字来源于牛津大学的 Visual Geometry Group,他们提出用多个 33小卷积核组合的方式来代替大卷积核。
人们通常认为卷积核越大,那么其感受野(receptive field)也越大,能匹配的模式也就更多。
对于两个串联的33卷积核,其感受野大小为55,和一个55的卷积核感受野一样大。
但前者的参数量为 18,而后者的参数量为25,并且小卷积核串联的方式能增加网络的深度,可以更好地学习高级特征。
测试结果
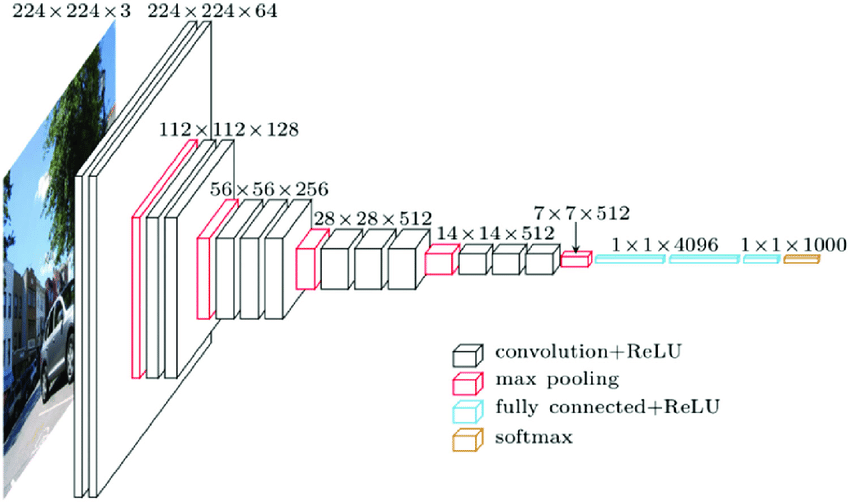
网络结构
作者进行了6组对比试验,从左到右网络结构依次加深。
LRN 就是局部响应归一化 Local Response Normalization,也就是之前在AlexNet中提到的操作。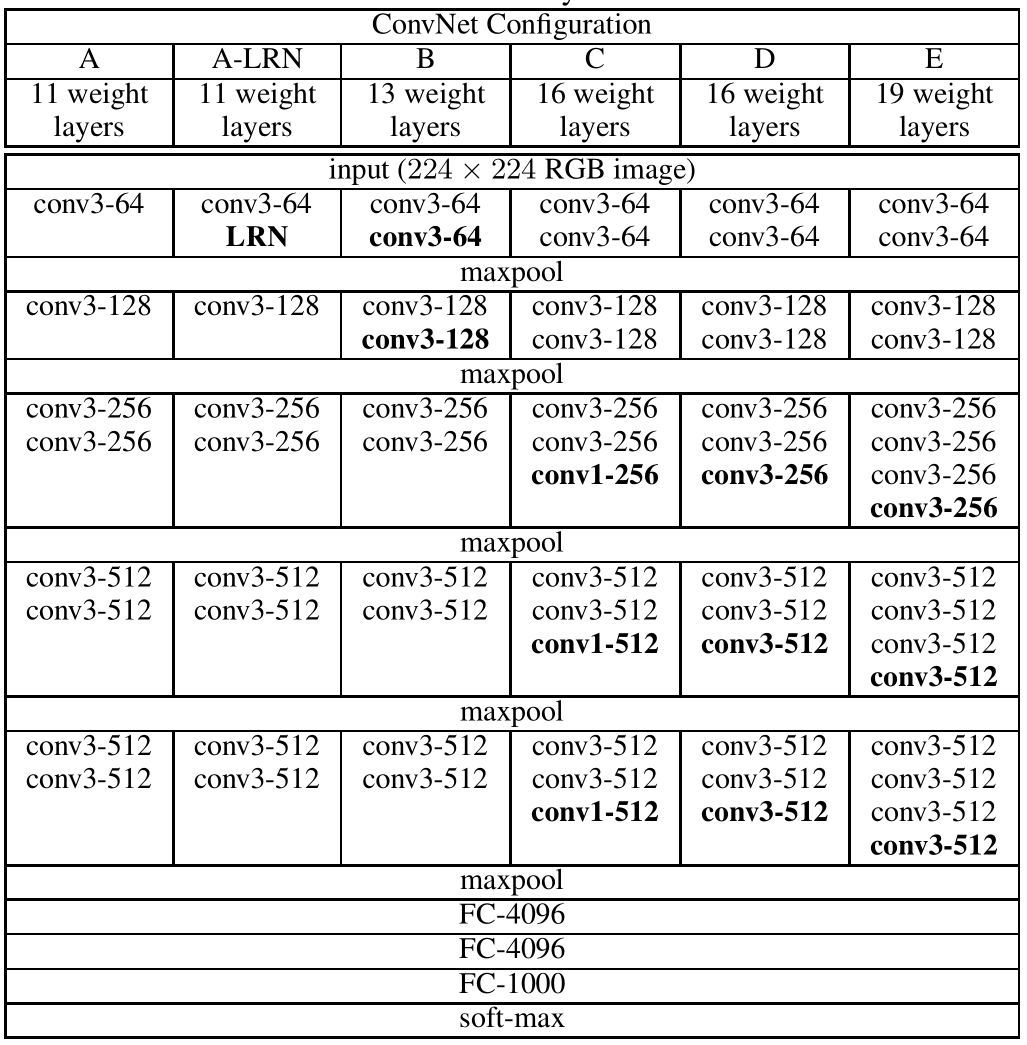
单/多尺度测试结果
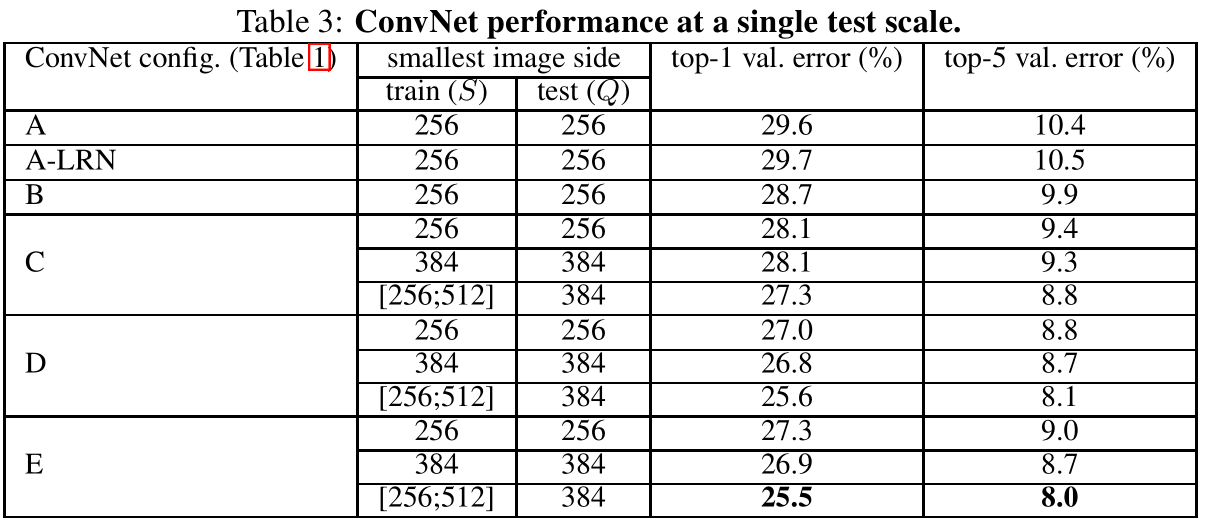
在单尺度测试结果如上图:
- LRN :✘
- 变换输入图片大小:✘
- 多尺度训练:✔
- 增加网络深度:✔
- VGG-19效果最好
在多尺度测试结果如下图: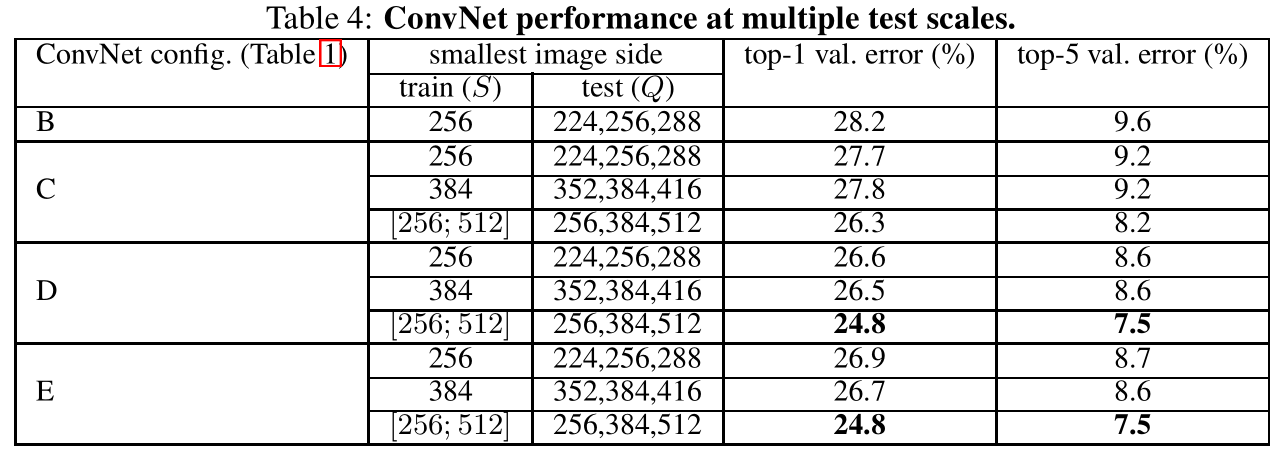
结论:
- VGG-16和VGG-19精度一样,但参数更少
- 多尺度训练在多尺度测试中效果更好
Dense ConvNet和mult-crop
Dense ConvNet 就是将最后的全连接层先转化为卷积层(第一个全连接层转为7x7的卷积层,后两个转化为1x1的卷积层),这样可以对不同尺寸图像进行训练。
假设最后的输入特征为 77512,使用1000个77512的卷积核,令stride=1,那么输出尺寸为[1,1,1,1000],即[1,1000]。
当输入特征为1414512时,令stride=2,那么输出尺寸为[1,2,2,1000],为一个scoremap,然后求平均得到[1,1000]的向量。
将dense ConvNet和mult-crop方法进行对比,结论是两者我全都要: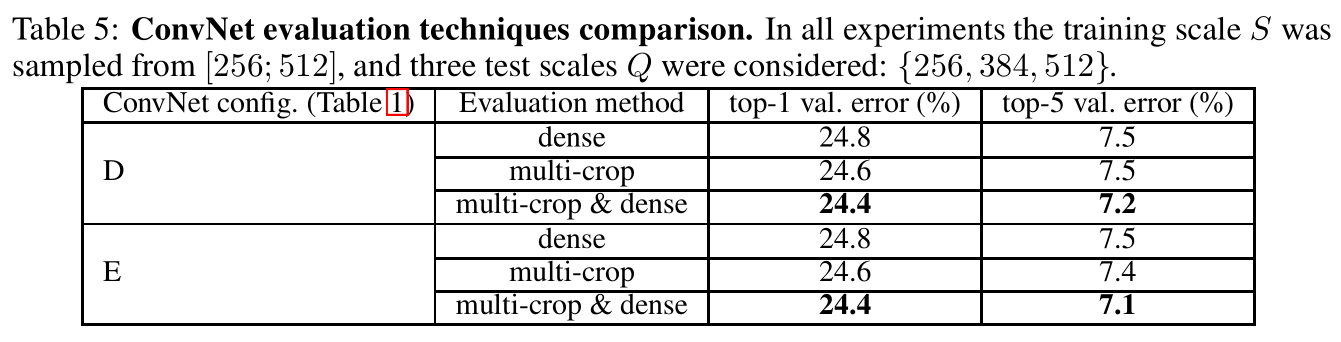
模型融合

参考链接

若有收获,就点个赞吧
0 人点赞
