简介
数据集
在 ImageNet LSVRC-2010 数据集上的 120万张图片上进行分类(类别数为1000)
错误率
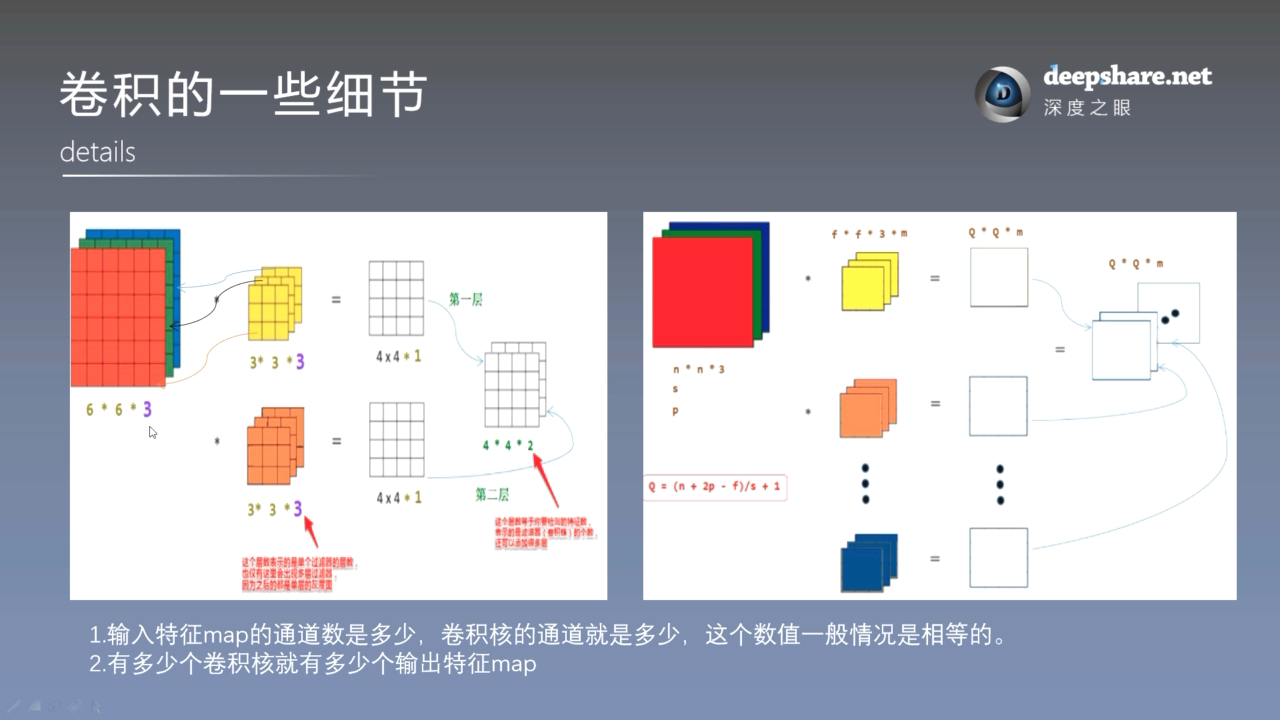
主要架构 Architecture
非线性激活函数——ReLU
常用的激活函数有:

但作者认为 ReLU 函数可以使得神经网络更快的收敛,这在大型网络的训练中非常重要。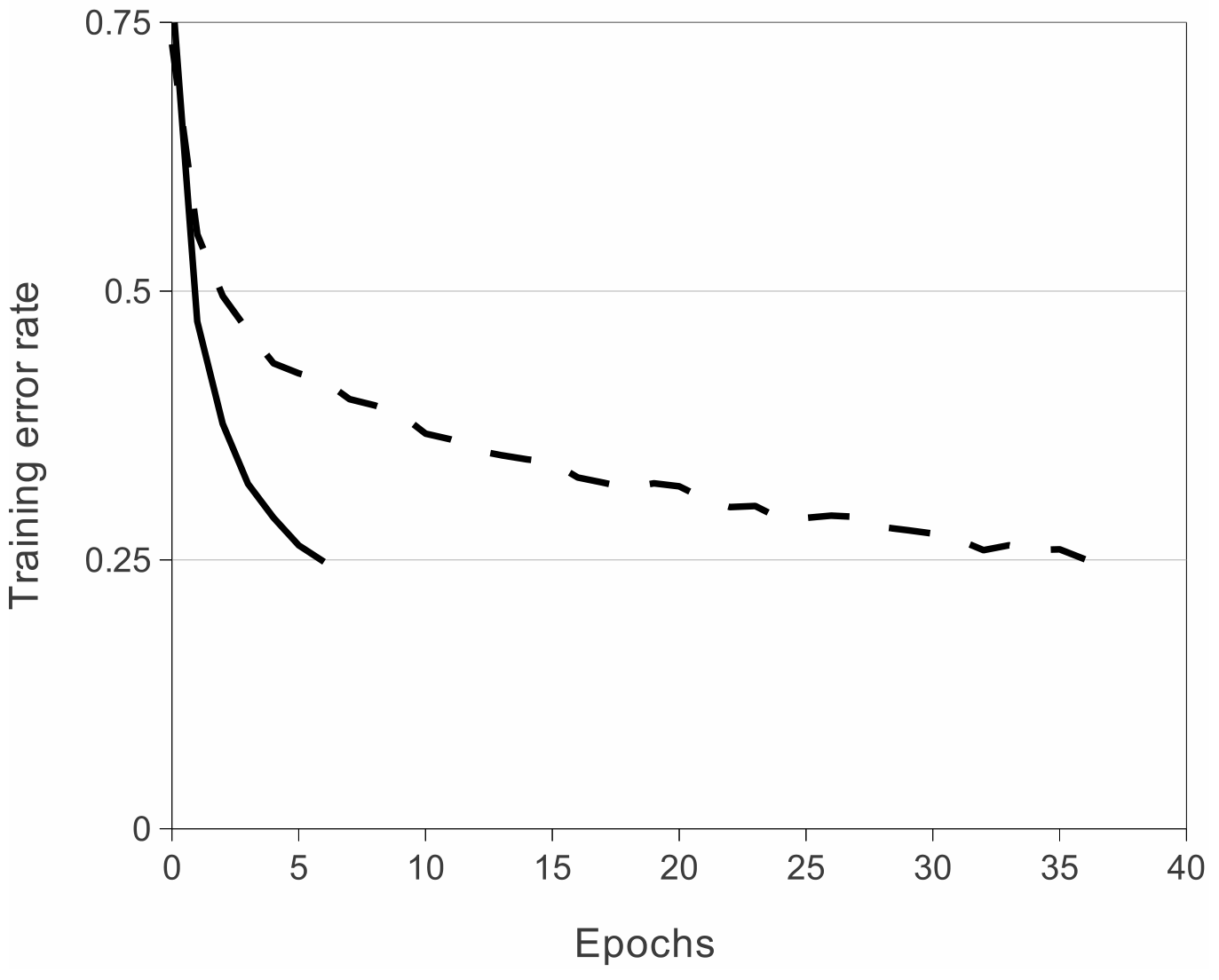
这是4层卷积神经网络在 CIFAR-10 数据集上的训练过程,使神经网络的错误率从75%降到25%.
实线部分是用 ReLU 激活函数,虚线部分是用 tanh 函数,可以看到 ReLU 比 tanh 收敛快了接近6倍。
优点:
- 使网络训练更快(一方面是反向传播时梯度计算更简单)
- 防止梯度消失/梯度爆炸
- 使网络具有稀疏性

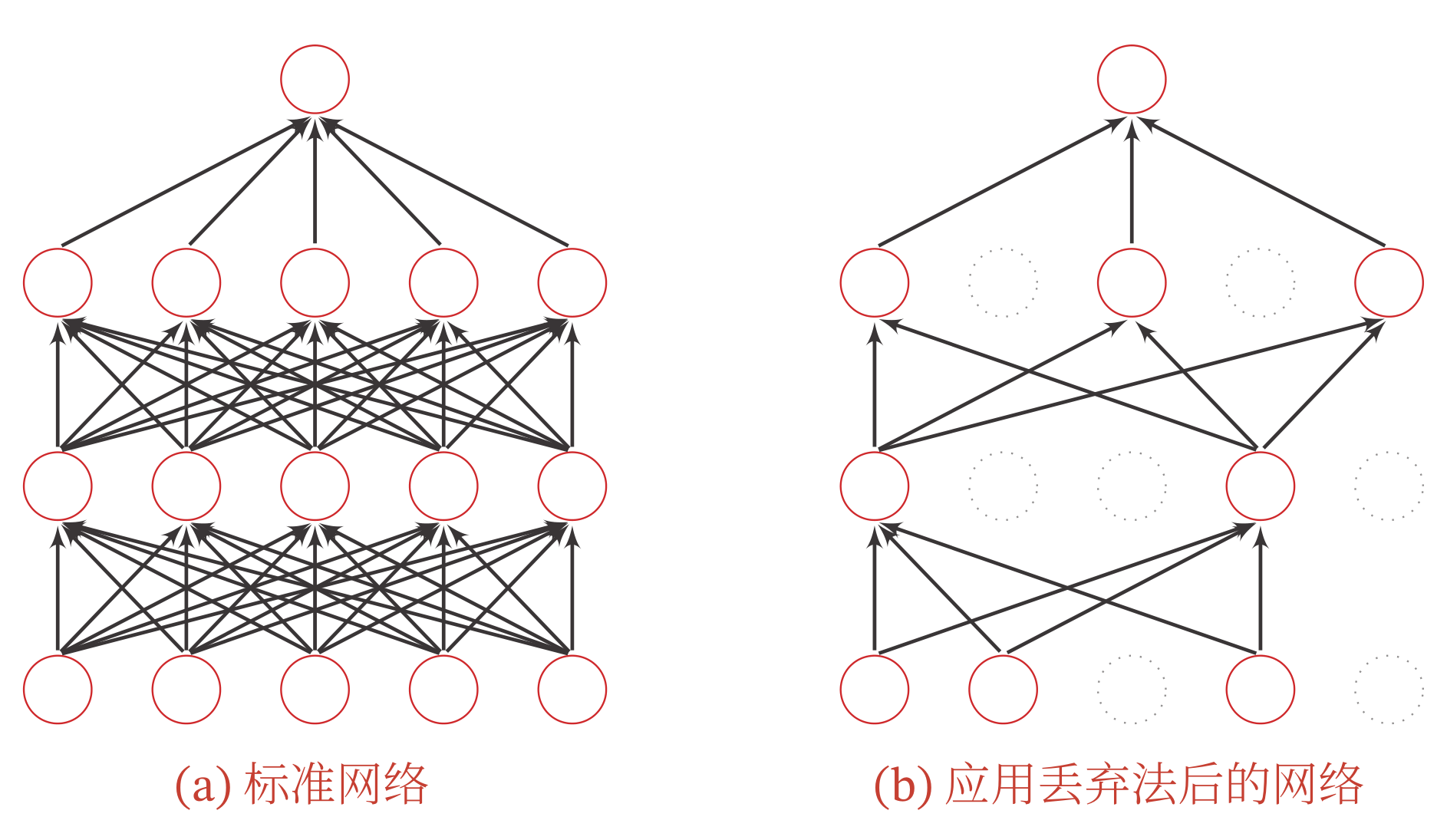
Dropout
当训练一个深度神经网络时,我们可以随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合,这种方法称为丢弃法( Dropout Method ).
花书中认为dropout可以看做一种Bagging方法,例如对以下有4个节点的Base network做dropout,就相当于2^4个subnetwork的ensemble.
在多GPU上训练
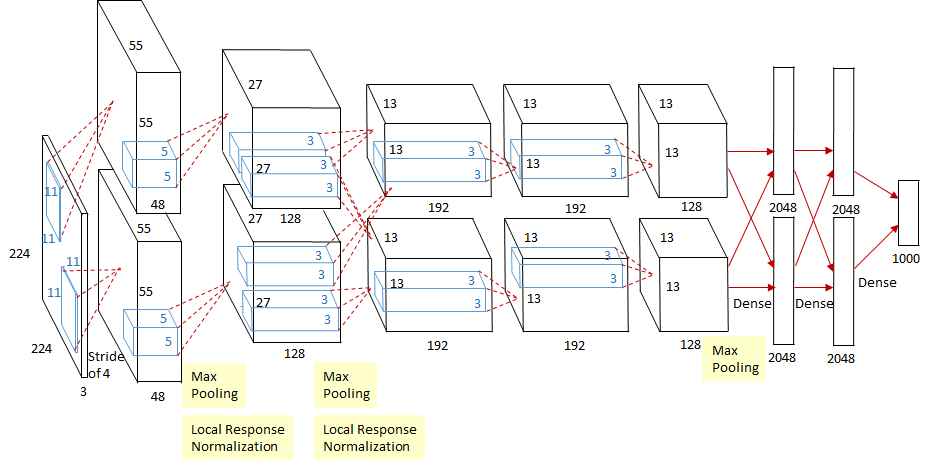
该神经网络是在2块GTX 580 GPU上训练的,由于 GTX 580 的显存只有 3GB,无法储存这么多参数,因此作者将神经网络设计成相同的两部分,在两块GPU上分别训练,如下图所示,一个GPU训练上面的神经网络,另一个GPU训练下面的,两个GPU仅在某些层间(第3个卷积层和后面所有的全连接层)进行数据互传。
作者做过实验,双GPU比单GPU的 top-1 和 top-5 错误率分别下降了 1.7% 和1.2%.
局部响应归一化 Local Response Normalization
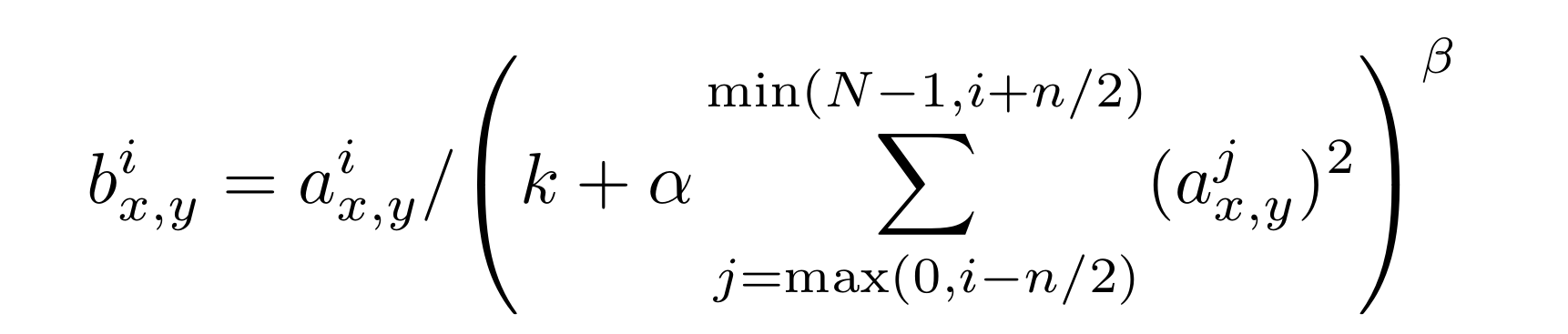
这是一个将数据归一化的方法,大意就是将相邻的n个神经元来做归一化。
但现在的深度网络中很少用到了,一般都是用批归一化(Batch Normalization)或组归一化(Group Normalization),因此就不详细介绍了。
重叠池化 Overlapping Pooling
重叠池化的步幅比池化窗口的长宽都要小,会导致池化感受野和上一步的感受野有重叠的地方,例如文中的池化窗口大小为3x3,但步幅为2,就会产生1个像素的重叠。
作者发现使用重叠池化有助于防止过拟合。
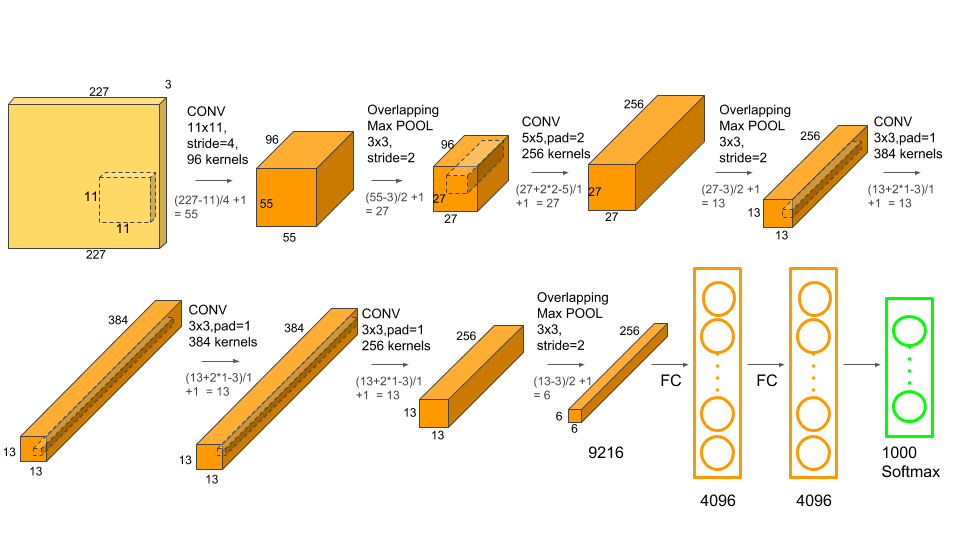
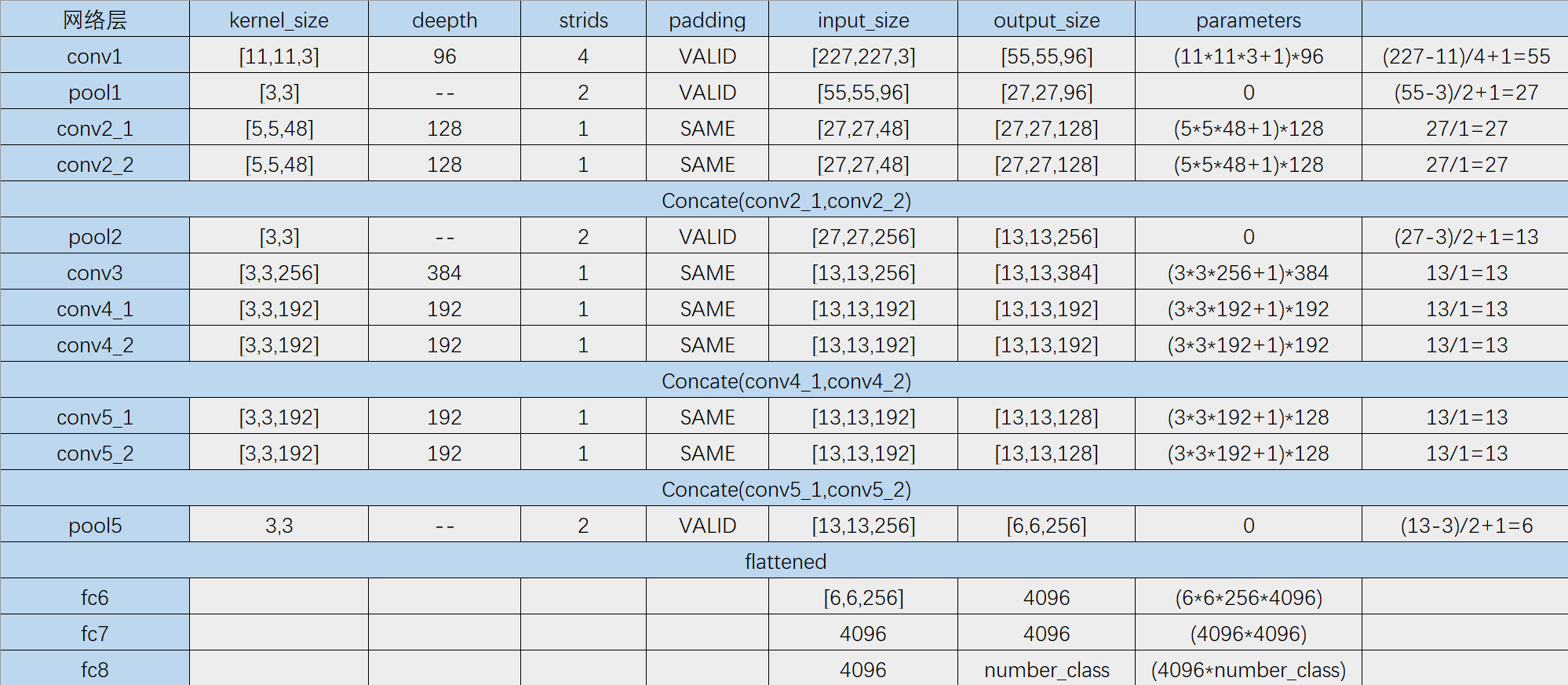
神经网络整体架构
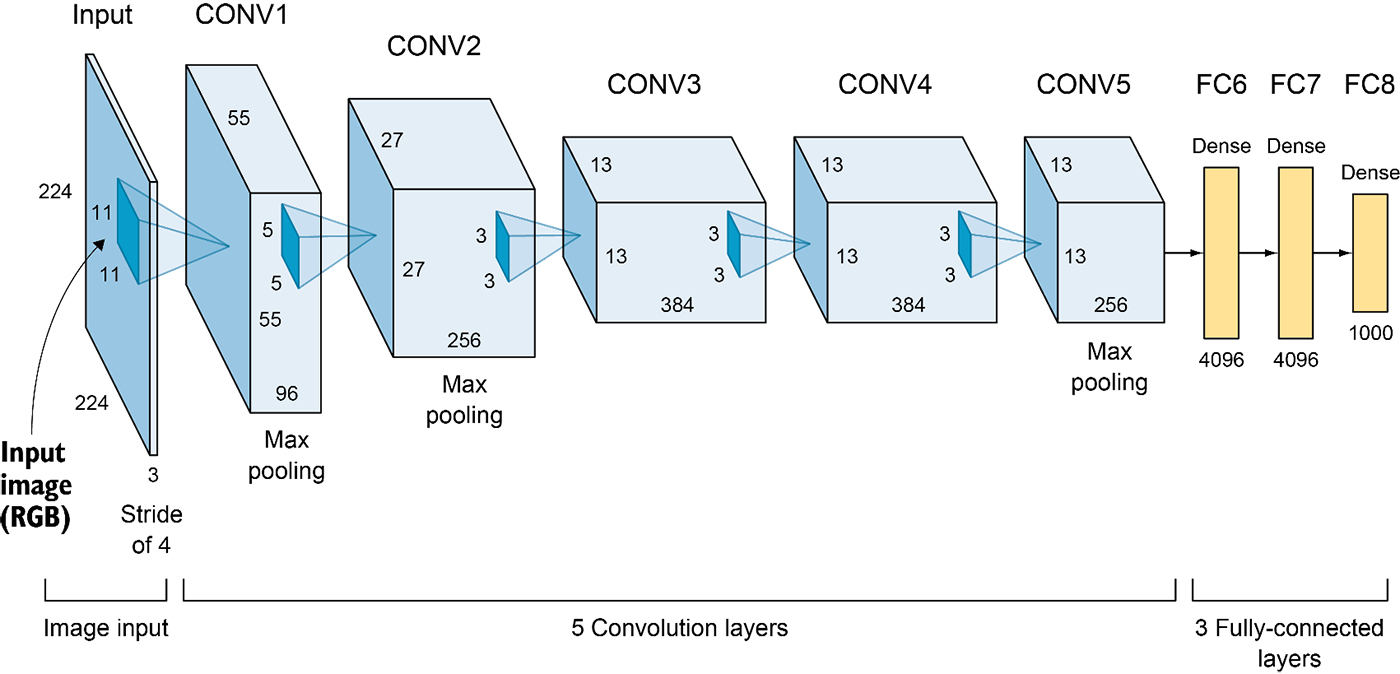
- 输入层( input ):输入的图片的size为

- 卷积层(Conv1):有48*2=96个卷积核,大小为
 ,步幅stride=4,零填充Padding=3
,步幅stride=4,零填充Padding=3 - 池化层( Pool1 ) :Max Pooling 窗口大小为
 ,stride=2
,stride=2 - 卷积层(Conv2):有128*2=256个卷积核,大小为
 ,stride=1,Padding=2
,stride=1,Padding=2 - 池化层( Pool2 ) :Max Pooling 窗口大小为
 ,stride=2
,stride=2 - 卷积层(Conv3):有192*2=384个卷积核,大小为
 ,stride=1,Padding=1
,stride=1,Padding=1 - 卷积层(Conv4):有192*2=384个卷积核,大小为
 ,stride=1,Padding=1
,stride=1,Padding=1 - 卷积层(Conv5):有128*2=256个卷积核,大小为
 ,stride=1,Padding=1
,stride=1,Padding=1 - 池化层( Pool5 ) :Max Pooling 窗口大小为
 ,stride=2
,stride=2 - 全连接层(FC1):有2*2048个神经元
- 全连接层(FC2):有2*2048个神经元
- 全连接层(FC3):有1000个神经元
- Softmax输出层:输出1000个类别的概率
此外, AlexNet 还在Pool1,Pool2 两个池化层之后进行了局部响应归一化( Local Response Normalization, LRN )以增强模型的泛化能力.
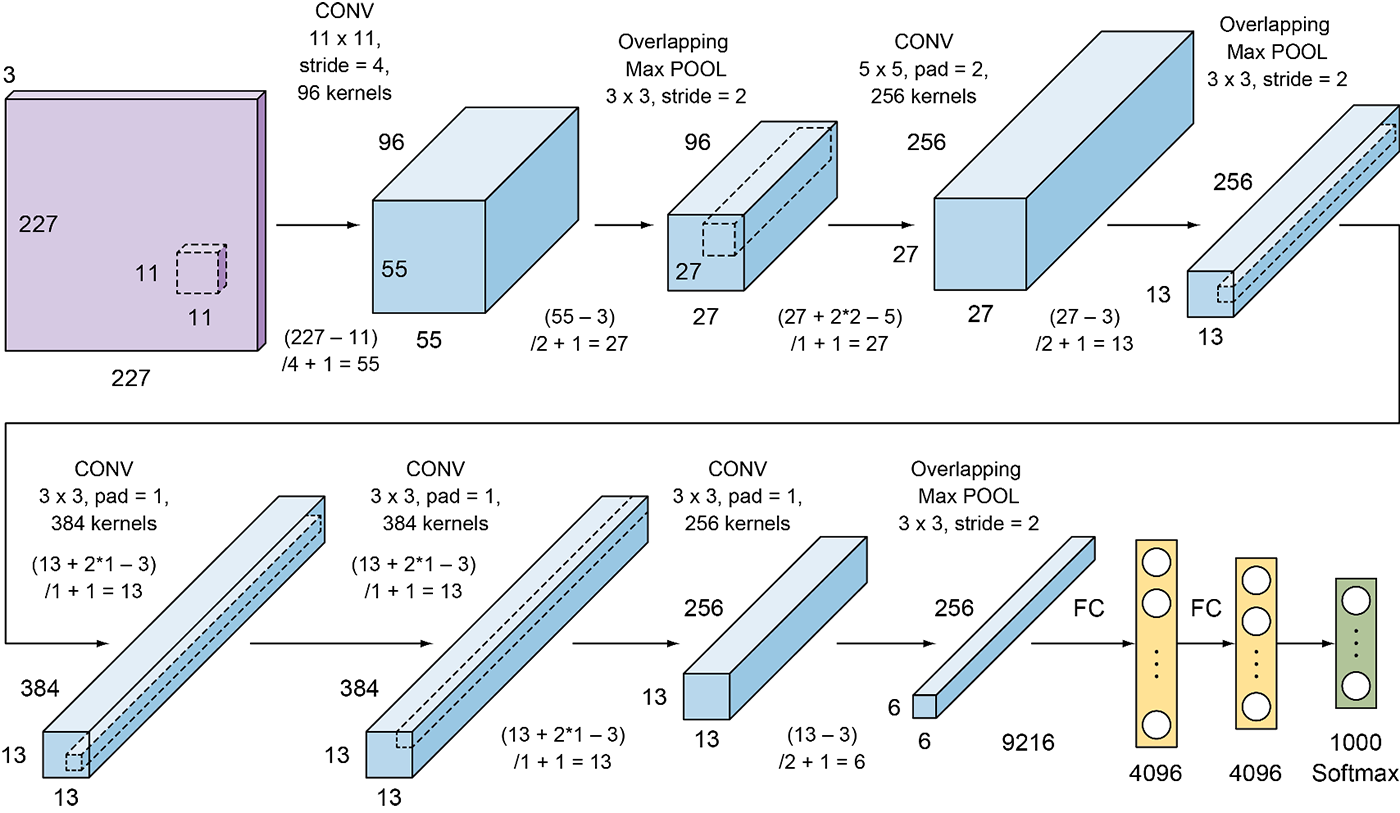
输出特征图大小计算公式为:
- Conv1的特征图尺寸为
 ,特征图大小为55x55x96
,特征图大小为55x55x96 - Pool1的特征图尺寸为
 ,特征图大小为27x27x96
,特征图大小为27x27x96 - Conv2的特征图尺寸为
 ,特征图大小为27x27x256
,特征图大小为27x27x256 - Pool2 的特征图尺寸为
 ,特征图大小为13x13x256
,特征图大小为13x13x256 - Conv3的特征图尺寸为
 ,特征图大小为13x13x384
,特征图大小为13x13x384 - Conv4的特征图尺寸为
 ,特征图大小为13x13x384
,特征图大小为13x13x384 - Conv4的特征图尺寸为
 ,特征图大小为13x13x256
,特征图大小为13x13x256 - Pool5 的特征图尺寸为
 ,特征图大小为6x6x256
,特征图大小为6x6x256
Pytorch 实现
import torchimport torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=(11, 11), stride=4, padding=3)self.pool1 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)self.conv2 = nn.Conv2d(96, 256, (5, 5), 1, 2)self.pool2 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)self.conv3 = nn.Conv2d(256, 384, (3, 3), 1, 1)self.conv4 = nn.Conv2d(384, 384, (3, 3), 1, 1)self.conv5 = nn.Conv2d(384, 256, (3, 3), 1, 1)self.pool5 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)self.drop = nn.Dropout(0.5)self.fc1 = nn.Linear(6*6*256, 4096)self.fc2 = nn.Linear(4096, 4096)self.fc3 = nn.Linear(4096, 1000)def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = F.relu(self.conv3(x))x = F.relu(self.conv4(x))x = self.pool5(F.relu(self.conv5(x)))# 将 x 转化成向量x = x.view(-1, self.num_flat_features(x))x = self.drop(F.relu(self.fc1(x)))x = self.drop(F.relu(self.fc2(x)))x = self.fc3(x)return xdef num_flat_features(self, x):size = x.size()[1:] # all dimensions except the batch dimensionnum_features = 1for s in size:num_features *= sreturn num_featuresnet = Net()print(net)
还有一种用 nn.Sequential 的方法:
import torch.nn as nnclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 96, (11, 11), 4, 3),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, (5, 5), 1, 2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, (3, 3), 1, 1),nn.ReLU(inplace=True),nn.Conv2d(384, 384, (3, 3), 1, 1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, (3, 3), 1, 1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.classifier = nn.Sequential(nn.Linear(6*6*256, 4096),nn.ReLU(inplace=True),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = x.view(x.size(0), 256 * 6 * 6)x = self.classifier(x)return xif __name__ == '__main__':# Examplenet = AlexNet()print(net)

若有收获,就点个赞吧
0 人点赞
