1、导入csv/excel
csv
f=open('./file.csv')Df=pd.read_csv(f)# usecols只读取下标为2,4,15的列Df=pd.read_csv(f, usecols=[2,4,15], encoding='gbk') # 数据内含中文字符时尽量使用GBK编码格式读入。
excel
import pandas as pd# 读入默认第一列(0)为index,且默认读入第一个sheet# sheet1第一行为列名df = pd.read_excel('test.xlsx',index_col = 0)# 读取Sheet2的内容,默认读取第一行数据为column列列名# sheet2第一行为数据。df = pd.read_excel('test.xlsx',sheet_name='Sheet2',index_col = 0)# 设置header=None避免把第一行作为column列列名的情况,生成的列名默认为1。df = pd.read_excel('test.xlsx',sheet_name='Sheet2',index_col = 0, header=None)
2、基本信息查询
Df.shape # # 查看数据集大小# 显示大小设置pd.set_option('display.max_columns', None) # 下方代码输出显示所有列pd.set_option('display.max_rows', None) # 下方代码输出显示所有行pd.set_option('display.float_format', lambda x:'%.f'%x) #为了直观的显示数字,浮点数不采用科学计数法pd.set_option('max_colwidth',100) # 设置value的显示长度为100,默认为50pd.set_option('display.expand_frame_repr', False) # 设置不折叠数据Df.head(10) # 读取前10行数据pd.isnull(Df).sum() # 查看各列数据存在Null的个数Df.isnull().any() # 查看各列数据是否存在Null,是的话返回True,否的话选择FalseDf.info() # 查看各列数据类型信息及非空值计数信息Df.dtypes # 查看各列数据类型信息Df.describe() # 输出数据count、std标准差、min、上四分位数0.75、中位数0.5、下四分位数0.25、max;
3、字符串转换数值
1)转换数据不存在异常值或缺失
Df[['a']].astype(float)Df[['a']].astype(int)
2)转换数据存在异常值或缺失
在转换数值的时候可能会存在列数据中存在其他字符或者数据缺失的情况,此时并不能直接使用astype进行转换,这时候使用下列代码即可完成转换,转换的时候将其他字符或者数据缺失的单元格赋值为NaN
Df['a']=Df['a'].apply(pd.to_numeric, errors='coerce')
4、找出有空值的行或者列
方式1代码
Df[Df.isnull().T.any()] # # 输出所有‘a’列存在空值的所在行的所有数据列内容Df[Df.isnull().T.any()]['a','b'] # 输出所有‘a’列存在空值的所在行的所有数据(指定输出a与b列)Df[Df.isnull().any()] # 找有空值的列列名
示例:
import pandas as pdimport numpy as npn = np.arange(20, dtype=float).reshape(5,4)n[2,3] = np.nanindex = ['index1', 'index2', 'index3', 'index4', 'index5']columns = ['column1', 'column2', 'column3', 'column4']frame3 = pd.DataFrame(data=n, index=index, columns=columns)print(frame3[frame3.isnull().T.any()]) # 找有空值的行
结果,程序成功找到了第三行为有空值的行。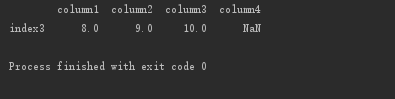
之所以使用转置:
非转置:frame3.isnull().any(),得到的每一列求any()计算的结果,输出为列的Series。
转置:frame3.isnull().T.any(),得到的每一行求any()计算的结果,输出为行的Series。
import pandas as pdimport numpy as npn = np.arange(20, dtype=float).reshape(5,4)n[2,3] = np.nanindex = ['index1', 'index2', 'index3', 'index4', 'index5']columns = ['column1', 'column2', 'column3', 'column4']frame3 = pd.DataFrame(data=n, index=index, columns=columns)print(frame3.isnull().any()) # 找有空值的列print(frame3.isnull().T.any())

方式2代码
Df[Df['a']!=Df['a']] # 输出所有‘a’列存在空值的所在行的所有数据列内容Df[Df['a']!=Df['a']]['a','b'] # 输出所有‘a’列存在空值的所在行的所有数据(指定输出a与b列)[['tenure','MonthlyCharges','TotalCharges']]
空值替换
Df.loc[:,'a']=Df.loc[:,'a'].fillna(Df.loc[:,'b']) # 用b列内容填充a列内容的空值-方式1Df['a']=Df['a'].fillna(Df['b']) # 用b列内容填充a列内容的空值-方式2# 将‘c’列中的0修改为1Df.loc[:,'c'].replace(to_replace=0,value=1,inplace=True)df.fillna(0)df.fillna({1:0, 2:0.5}) #对第一列nan值赋0,第二列赋值0.5df.fillna(method='ffill') #在列方向上以前一个值作为值赋给NaN
列空值与非空值计数
计算控制个数
data.isnull().sum()
计算非空值个数
data.notnull().sum()
计算NaN个数
data.notna().sum()
isna()和notna()是isnull()和notnull()的别名,它们的用法是一样的
参考资料:https://blog.csdn.net/hooyying/article/details/123304197

若有收获,就点个赞吧
0 人点赞
