1. 函数生成简单的DataFrame
import pandas as pdimport numpy as npdef make_df(cols, ind):# 一个简单的DataFramedata = {c: [str(c) + str(i) for i in ind]for c in cols}return pd.DataFrame(data, ind)df = make_df('ABC', range(3))print(df)A B C0 A0 B0 C01 A1 B1 C12 A2 B2 C2
2. Numpy数组的合并
print('Numpy数组的合并')x = [1, 2, 3]y = [4, 5, 6]z = [7, 8, 9]np.concatenate([x, y, z])Numpy数组的合并array([1, 2, 3, 4, 5, 6, 7, 8, 9])
3. Pandas的合并
1、 Series合并
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])print('按行合并')print(pd.concat([ser1, ser2], axis=0))print('按列合并')print(pd.concat([ser1, ser2], axis=1))print(pd.concat([ser1, ser2], axis='columns'))按行合并1 A2 B3 C4 D5 E6 Fdtype: object按列合并0 11 A NaN2 B NaN3 C NaN4 NaN D5 NaN E6 NaN F0 11 A NaN2 B NaN3 C NaN4 NaN D5 NaN E6 NaN F
2、 DataFrame-concat合并
2.1 指定合并轴
print('对DataFrame的合并,可以指定合并轴')df1 = make_df('AB', [1, 2])df2 = make_df('AB', [3, 4])print(df1)print(df2)print(pd.concat([df1, df2]))print(pd.concat([df1, df2], axis='columns')) # 也可以axis=1对DataFrame的合并,可以指定合并轴A B1 A1 B12 A2 B2A B3 A3 B34 A4 B4A B1 A1 B12 A2 B23 A3 B34 A4 B4A B A B1 A1 B1 NaN NaN2 A2 B2 NaN NaN3 NaN NaN A3 B34 NaN NaN A4 B4
2.2 并集合并
对DataFrame的合并,sort默认值为True,此时默认进行并集合并(join=’outer’).当更改sort为False时,列的顺序维持原样.
df5 = make_df('BAC', [1, 2])df6 = make_df('BCD', [3, 4])print(df5)print(df6)print("sort值为True时,列的顺序进行排序")print(pd.concat([df5, df6]))print(pd.concat([df5, df6], sort=True))print("sort值为False时,列的顺序维持原样,不进行重新排序")print(pd.concat([df5, df6], sort=False))对DataFrame的合并,默认进行并集合并(join='outer')sort默认值为True,表示B A C1 B1 A1 C12 B2 A2 C2B C D3 B3 C3 D34 B4 C4 D4sort值为True时,列的顺序进行排序A B C D1 A1 B1 C1 NaN2 A2 B2 C2 NaN3 NaN B3 C3 D34 NaN B4 C4 D4A B C D1 A1 B1 C1 NaN2 A2 B2 C2 NaN3 NaN B3 C3 D34 NaN B4 C4 D4sort值为False时,列的顺序维持原样,不进行重新排序B A C D1 B1 A1 C1 NaN2 B2 A2 C2 NaN3 B3 NaN C3 D34 B4 NaN C4 D4
2.3 交集合并
print(df5)print(df6)print('交集合并')print(pd.concat([df5, df6],join='inner'))B A C1 B1 A1 C12 B2 A2 C2B C D3 B3 C3 D34 B4 C4 D4交集合并B C1 B1 C12 B2 C23 B3 C34 B4 C4
3、 DataFrame-merge合并
3.1 merge左合并右合并
print('\n按左边df5数据的行进行合并:')print(pd.merge(df5, df6, how='left', left_index=True, right_index=True))print('\n按右边df6数据的行进行合并:')print(pd.merge(df5, df6, how='right', left_index=True, right_index=True))按左边df5数据的行进行合并:B_x A C_x B_y C_y D1 B1 A1 C1 NaN NaN NaN2 B2 A2 C2 NaN NaN NaN按右边df6数据的行进行合并:B_x A C_x B_y C_y D3 NaN NaN NaN B3 C3 D34 NaN NaN NaN B4 C4 D4
3.2 一对一连接
merge默认丢弃原来的索引,按相同列进行合并,employee这一列完全一样,所以就按照这一列进行合并
import pandas as pddf1 = pd.DataFrame({'employee': ['Lisa', 'Bob', 'Jake', 'Sue'],'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})df2 = pd.DataFrame({'employee': ['Lisa', 'Bob', 'Jake', 'Sue'],'hire_date': [2004, 2008, 2012, 2014]})print(df1)print(df2)print('一对一连接')df3 = pd.merge(df1, df2)print(df3)employee group0 Lisa Accounting1 Bob Engineering2 Jake Engineering3 Sue HRemployee hire_date0 Lisa 20041 Bob 20082 Jake 20123 Sue 2014一对一连接employee group hire_date0 Lisa Accounting 20041 Bob Engineering 20082 Jake Engineering 20123 Sue HR 2014
3.3 一对多连接
df4 = pd.DataFrame({'group': ['Accounting', 'Engineering', 'HR'],'supervisor': ['Carly', 'Guido', 'Steve']})print(df3)print(df4)print(pd.merge(df3, df4))employee group hire_date0 Lisa Accounting 20041 Bob Engineering 20082 Jake Engineering 20123 Sue HR 2014group supervisor0 Accounting Carly1 Engineering Guido2 HR Steveemployee group hire_date supervisor0 Lisa Accounting 2004 Carly1 Bob Engineering 2008 Guido2 Jake Engineering 2012 Guido3 Sue HR 2014 Steve
3.4 多对多连接
df5 = pd.DataFrame({'group': ['Accounting', 'Accounting', 'Engineering', 'Engineering', 'HR'],'skills': ['math', 'spreadsheets', 'coding', 'spreadsheets', 'organization']})print(df1)print(df5)print(pd.merge(df1, df5))employee group0 Lisa Accounting1 Bob Engineering2 Jake Engineering3 Sue HRgroup skills0 Accounting math1 Accounting spreadsheets2 Engineering coding3 Engineering spreadsheets4 HR organizationemployee group skills0 Lisa Accounting math1 Lisa Accounting spreadsheets2 Bob Engineering coding3 Bob Engineering spreadsheets4 Jake Engineering coding5 Jake Engineering spreadsheets6 Sue HR organization
3.5 按照不同列名的两列进行融合
df3 = pd.DataFrame({'name': ['Lisa', 'Bob', 'Jake', 'Sue'],'salary': [7000, 9000, 10000, 20000]})aa = pd.merge(df1, df3, left_on='employee', right_on='name')print(df1)print(df3)print(aa)employee group0 Lisa Accounting1 Bob Engineering2 Jake Engineering3 Sue HRname salary0 Lisa 70001 Bob 90002 Jake 100003 Sue 20000employee group name salary0 Lisa Accounting Lisa 70001 Bob Engineering Bob 90002 Jake Engineering Jake 100003 Sue HR Sue 20000
3.6 内连接与外连接
merge()函数默认的是使用内连接
df4 = pd.DataFrame({'employee': ['Lisa', 'David', 'Ben'],'salary': [7000, 9000, 10000]})print(df1)print(df4)print(pd.merge(df1, df4))employee group0 Lisa Accounting1 Bob Engineering2 Jake Engineering3 Sue HRemployee salary0 Lisa 70001 David 90002 Ben 10000employee group salary0 Lisa Accounting 7000
可以指定merge()里的how参数更改连接方式为外连接
print(df1)print(df4)print('连接方式改为外连接')print(pd.merge(df1, df4, how='outer'))employee group0 Lisa Accounting1 Bob Engineering2 Jake Engineering3 Sue HRemployee salary0 Lisa 70001 David 90002 Ben 10000连接方式改为外连接employee group salary0 Lisa Accounting 7000.01 Bob Engineering NaN2 Jake Engineering NaN3 Sue HR NaN4 David NaN 9000.05 Ben NaN 10000.0
4、 DataFrame-join合并
pandas.DataFrame.join
参数说明
other:【DataFrame,或者带有名字的Series,或者DataFrame的list】如果传递的是Series,那么其name属性应当是⼀个集合,并且该集合将会作为结果DataFrame的列名
on:【列名称,或者列名称的list/tuple,或者类似形状的数组】连接的列,默认使⽤索引连接
how:【{‘left’, ‘right’, ‘outer’, ‘inner’}, default:‘left’】连接的⽅式,默认为左连接
lsuffix:【string】左DataFrame中重复列的后缀
rsuffix:【string】右DataFrame中重复列的后缀
sort:【boolean, default False】按照字典顺序对结果在连接键上排序。如果为False,连接键的顺序取决于连接类型(关键字)。
通过索引连接DataFrame
import pandas as pdfirst=pd.DataFrame({'item_id':['a','b','c','b','d'],'item_price':[1,2,3,2,4]})other=pd.DataFrame({'item_id':['a','b','f'],'item_atr':['k1','k2','k3']})print(first)print(other)print(first.join(other, lsuffix='_left', rsuffix='_right'))

通过指定的列连接DataFrame
import pandas as pdfirst=pd.DataFrame({'item_id':['a','b','c','b','d'],'item_price':[1,2,3,2,4]})other=pd.DataFrame({'item_id':['a','b','f'],'item_atr':['k1','k2','k3']})print(first)print(other)print(first.set_index('item_id').join(other.set_index('item_id')))

通过on参数指定连接的列
通过on参数指定连接的列,DataFrame.join总是使⽤other的索引去连接first,因此我们可以把指定的列设置为other的索引,然后⽤on去指定first的连接列,这样可以让连接结果的索引和first⼀致
import pandas as pdfirst=pd.DataFrame({'item_id':['a','b','c','b','d'],'item_price':[1,2,3,2,4]})other=pd.DataFrame({'item_id':['a','b','f'],'item_atr':['k1','k2','k3']})print(first)print(other)print(first.join(other.set_index('item_id'),on='item_id'))

左右连接
import pandas as pdfirst=pd.DataFrame({'item_id':['a','b','c','b','d'],'item_price':[1,2,3,2,4]})other=pd.DataFrame({'item_id':['a','b','f'],'item_atr':['k1','k2','k3']})print(first)print(other)# 左右连接print(first.join(other,how='right',lsuffix='_left',rsuffix='_right')) # 右连接print(first.join(other,how='left',lsuffix='_left',rsuffix='_right')) # 左连接 同索引连接效果相同
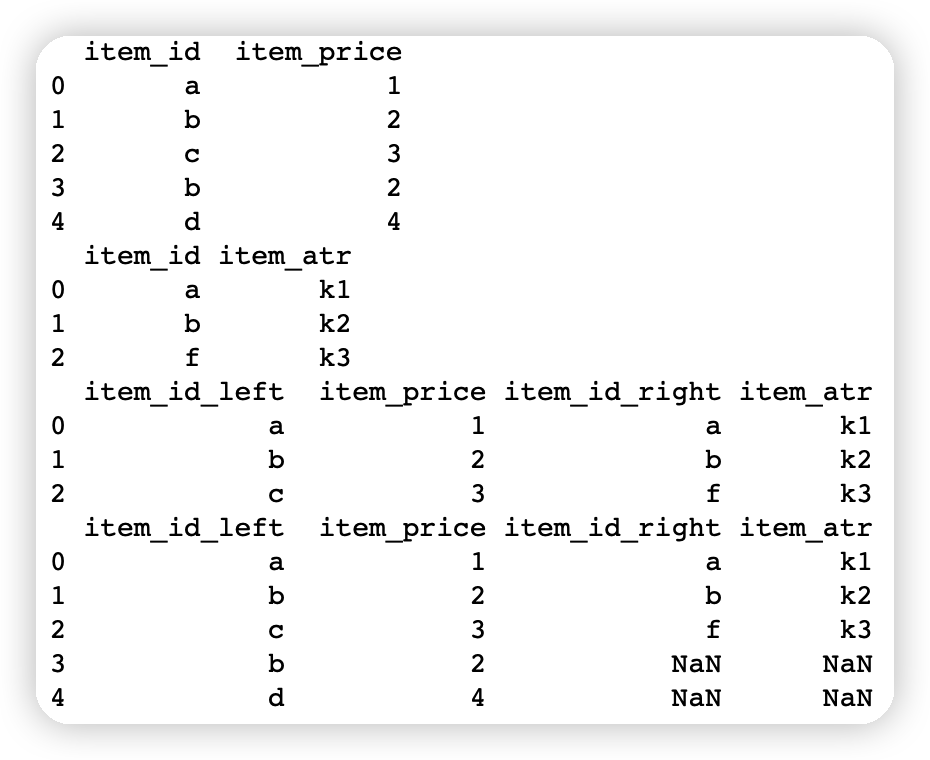
内外连接
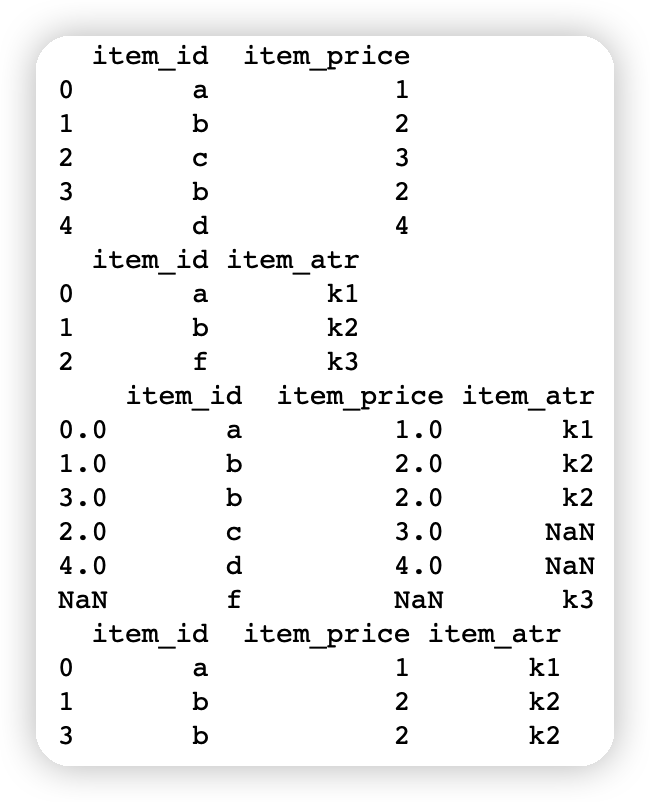
import pandas as pdfirst=pd.DataFrame({'item_id':['a','b','c','b','d'],'item_price':[1,2,3,2,4]})other=pd.DataFrame({'item_id':['a','b','f'],'item_atr':['k1','k2','k3']})print(first)print(other)# 外连接print(first.join(other.set_index('item_id'),on='item_id',how='outer'))# 内连接print(first.join(other.set_index('item_id'),on='item_id',how='inner'))
————————————————————————————
作者:绵掌骞魁2021
链接:https://wenku.baidu.com/view/036f0802a6e9856a561252d380eb6294dd882224.html
来源:百度文库
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
