· 批量删除
# 传入这个参数后将只丢弃全为缺失值的那些行data.dropna(how = 'all')# 传入这个参数后将只丢弃全为缺失值的那些行df.dropna()# 丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征)data.dropna(axis=1)# 丢弃行全为缺失值的那些列data.dropna(axis=1,how="all")# 删除列全为NaN的rowdf.dropna(how='all')# 删除表中含有任何NaN的列df.dropna(axis=1, how='any')# 删除表中含有任何NaN的行df.dropna(axis=0, how='any')# 丢弃‘Age’和‘Sex’这两列中有缺失值的行data.dropna(axis=0,subset = ["Age", "Sex"])
· 删除具体列
df.drop('成交数量',axis=1)df1 = df.drop(['a'], axis = 1) # 不会直接在原数据上更改del df['a'] # 会直接在原数据上更改
· 删除具体行
df.drop('2018-2-3')df = Df.drop([1], axis=0)
· 删除特定数值的行(删除成交金额小于10000)
df[ df['成交金额'] > 10000]
· 删除某列以特定字符/字符串开头的行
import pandas as pddf = pd.read_csv('data.csv')# 删除collectionName列以元宇宙开头的记录df = df[~df['collectionName'].astype(str).str.startswith('元宇宙')]
· 删除某列包含特殊字符的行
df[ ~ df['证券名称'].str.contains('联通') ]
· 如果想取包含某些字符的记录,去掉~即可
df[ df['证券名称'].str.contains('联通') ]
· 根据行号删除记录
比如删除第三行:
df.drop(df.index[3])
这个办法其实不是按照行号删除,而是按照索引删除。如果index为3,则会将前4条记录都删除。这个方法支持一个范围,以及用负数表示从末尾删除。
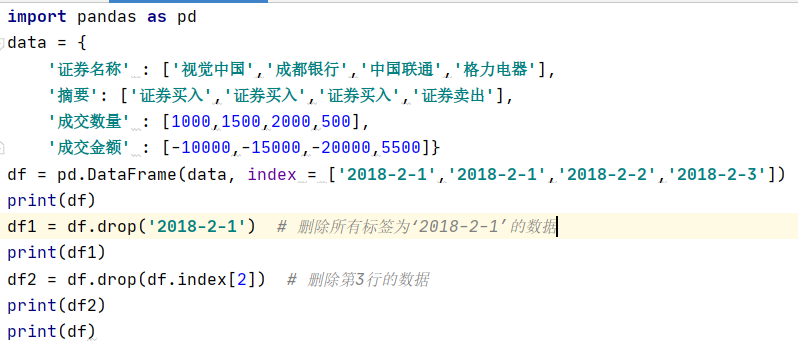
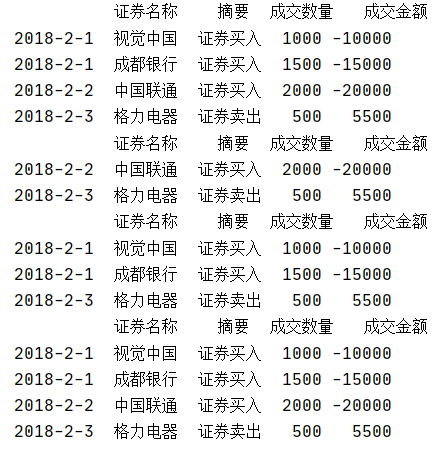
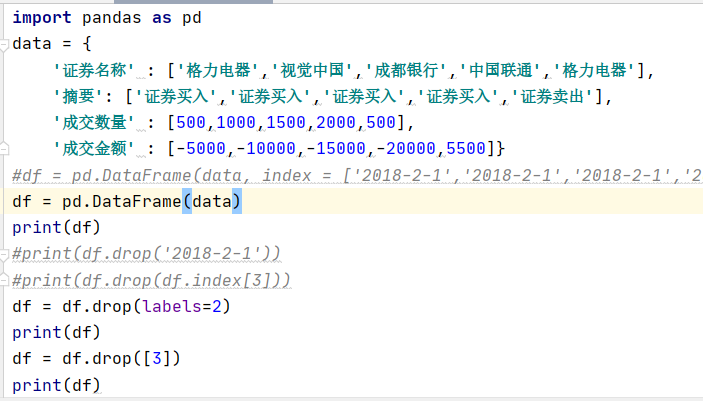
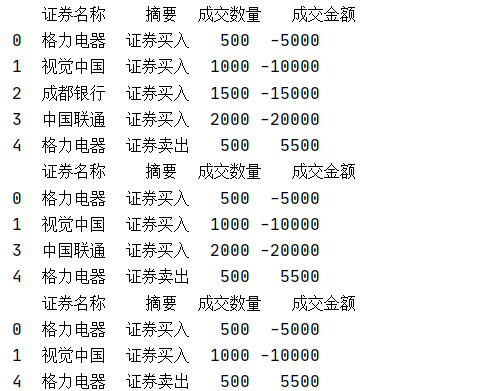
· 预设index的情况下删除特定index的数据
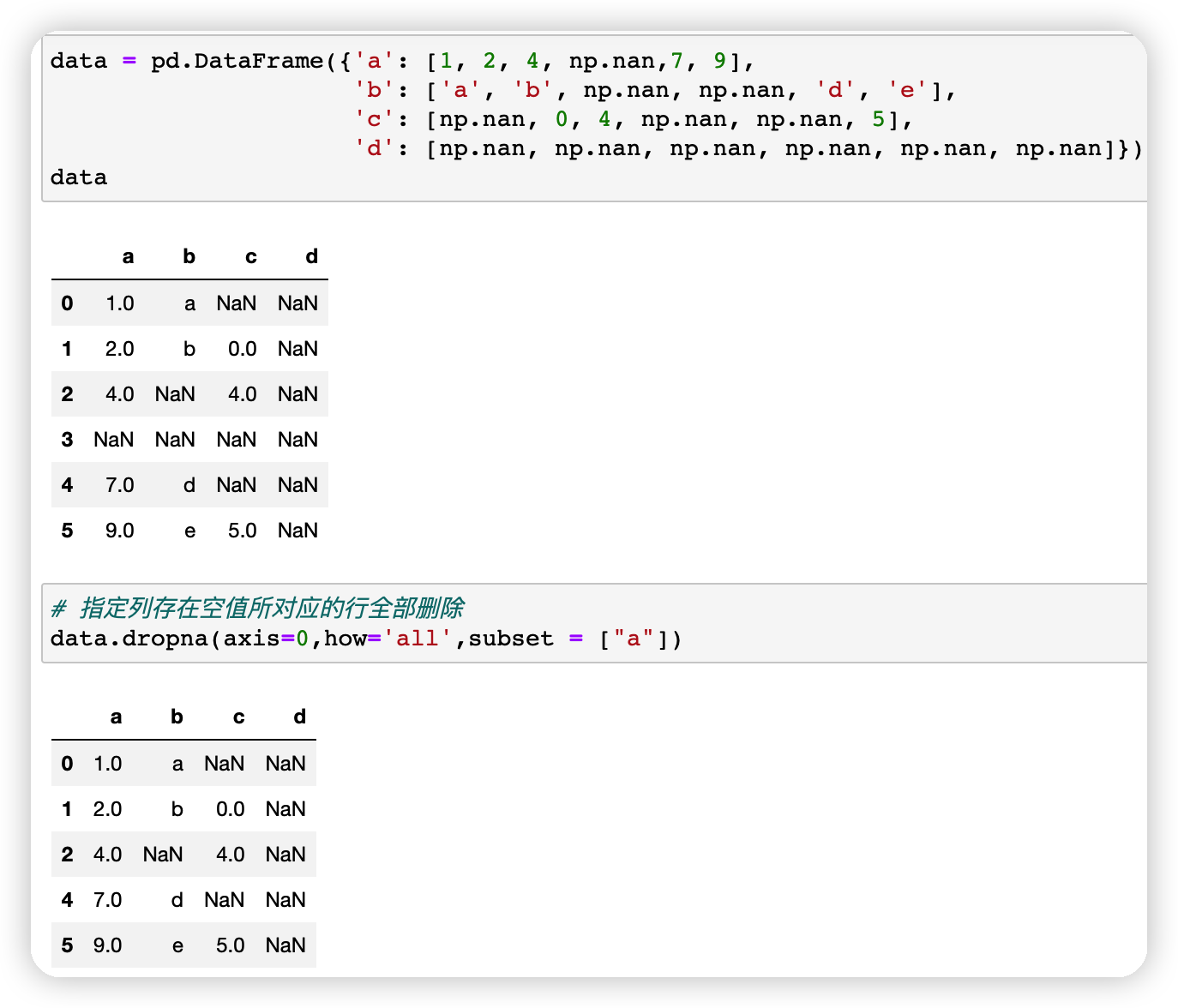
· 指定列存在空值所对应的行全部删除
data = pd.DataFrame({'a': [1, 2, 4, np.nan,7, 9],'b': ['a', 'b', np.nan, np.nan, 'd', 'e'],'c': [np.nan, 0, 4, np.nan, np.nan, 5],'d': [np.nan, np.nan, np.nan, np.nan, np.nan, np.nan]})# 指定列存在空值所对应的行全部删除data.dropna(axis=0,how='all',subset = ["a"])

若有收获,就点个赞吧
0 人点赞
