【数据结构与算法基础】代码仓库:https://github.com/jinrunheng/datastructure-and-algorithm
一:什么是跳表
跳表(Skip List)是由 William Pugh 发明的一种动态数据结构,支持对数据的快速查找,插入和删除。并且跳表的各方面性能都十分优秀,甚至可以媲美红黑树。
跳表本身是对有序链表的改进,我们先来回顾一下链表这种数据结构:
上图是我们维护的一个有序链表,在链表中查找,插入和删除一个元素的时间复杂度均为 O(N)。
为了提升效率,跳表在有序链表的基础上,引入了“索引”的概念,每两个节点提取一个节点到上一级,我们将抽出来的那一级叫做索引层: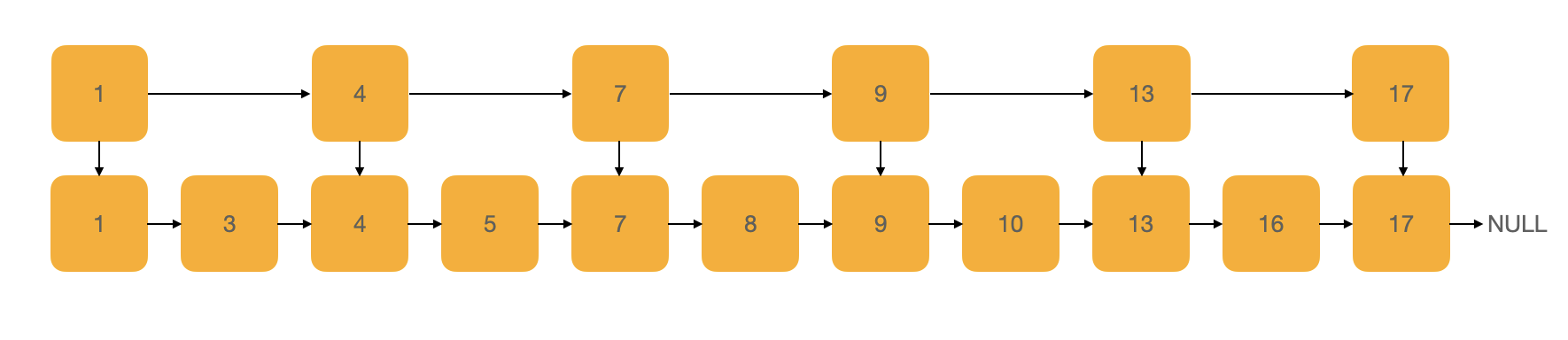
如果我们现在要查找某个节点,比如“16”,我们可以先在索引层遍历,当遍历到索引层“13”这个节点时,我们发现下一个节点是“17”,那么要查找的节点“16”肯定就在这两个节点之间。我们通过索引层节点的“down”指针下降到原始链表这一层继续遍历,现在,我们只需要再遍历 2 个节点就可以找到“16”这个节点了。原本我们需要遍历10 个节点才能找到“16”,通过添加索引层之后,我们只需要遍历 7 个节点。
我们增加了一个索引层后,查找效率有了提升,那么如果再添加更多的索引层呢?效率是否会提升更多?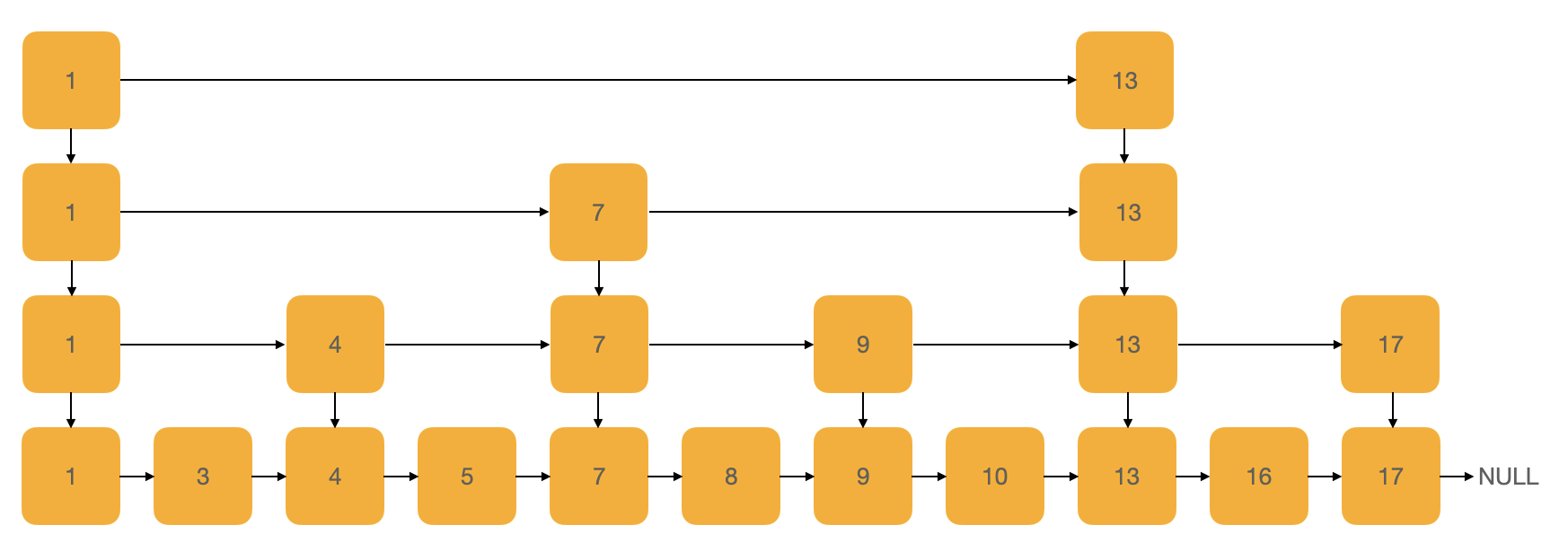
我们在原始的链表基础之上建立了三个“索引层”,依然是查找“16”这个节点,现在只需要遍历 6 次,遍历的过程,使用红线与编号标出,见下图: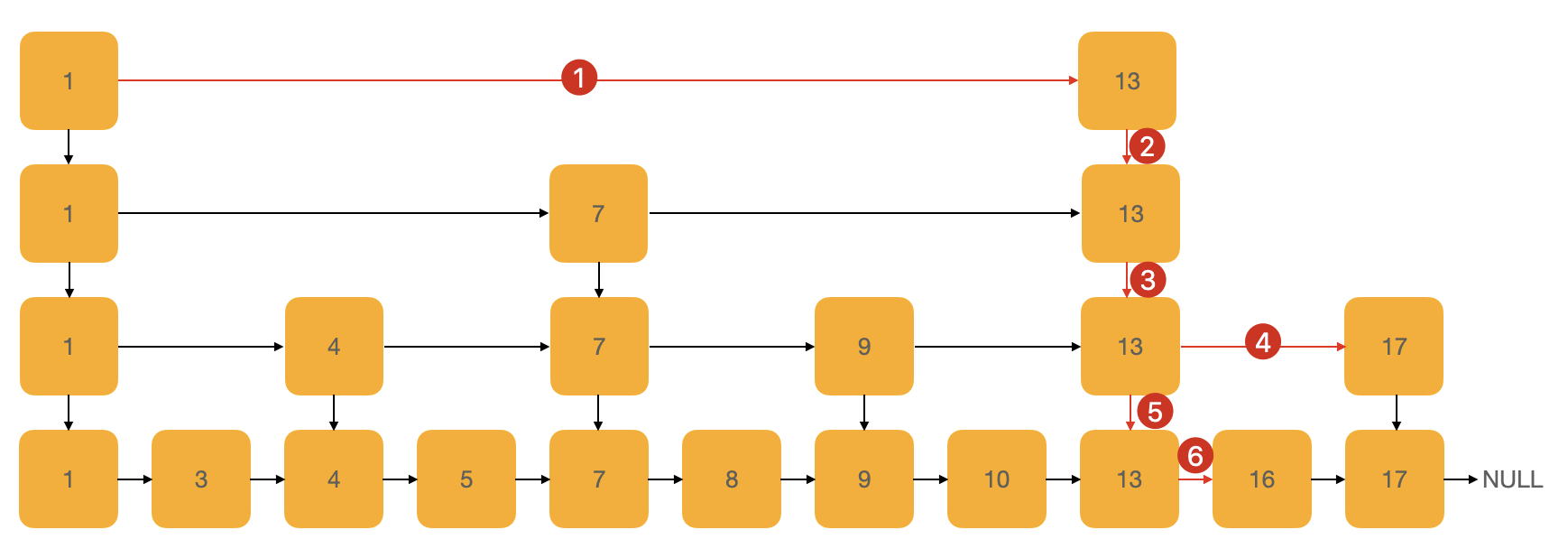
因为我们图示的链表数据量并不大,所以效率的提升并不是很明显。不过,我们可以想象一下,当数据规模很大时,我们的查找效率将会有巨大的提升。
而像上面我们描述的,这种链表加上多级索引的数据结构,就是跳表。
为了方便大家理解跳表这种数据结构,以及跳表的查找为什么效率很高,我展示了跳表的抽象;不过跳表真实的样子更像是这样的:
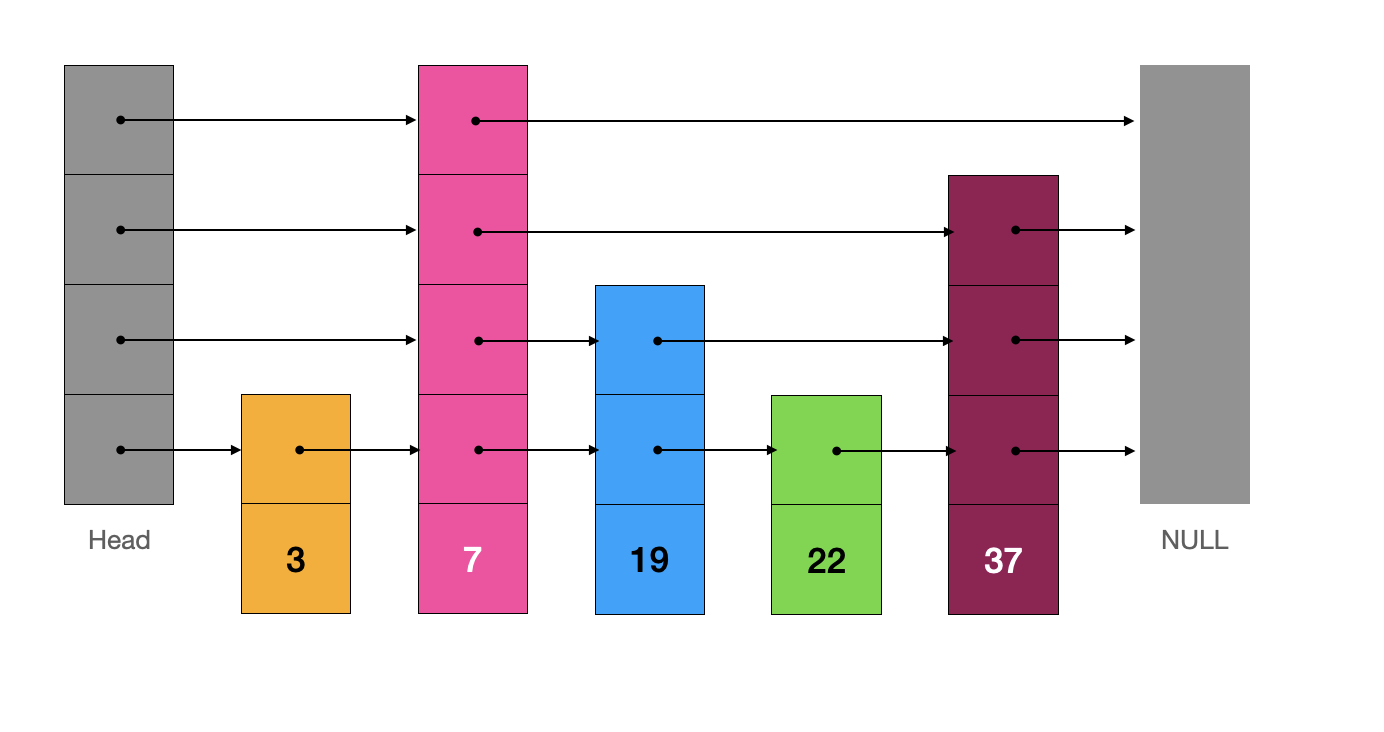
跳表中的节点 Node 除了存储元素值 e 以外,还要存储一个数组 Node[] next 来保存索引信息。
在“真实的”跳表中,我们发现,每个节点的“索引”在“索引层”的分布并不是均衡的,各个节点的“索引高度”也是参差不齐(索引高度就是 next.length)。
其实,我们认真思考也不难想到,想要维护一个像我们最开始模拟的跳表一样,层与层之间,从下层的每两个节点抽取出一个放在上层的完美结构几乎是不可能的。即便我们维持了那样的结构,提升了查找元素的效率,现在要向跳表中添加或删除一个元素,索引层就要重新调整,这个过程的开销将会是巨大的。
那么,我们该如何定义一个节点的“索引高度”呢?
我们既要保证跳表索引大小与数据大小的平衡性,如果每个节点的“索引高度”过低,跳表的性能就会严重退化;也要保证跳表各个节点的“索引高度”的平衡性,如果每个节点的“索引高度”几乎一致,那么性能也会严重退化。
为了解决这样的问题,跳表使用了随机数发生器(random number generator)来生成“索引高度”。
private int generateRandomLevel() {int level = 1;for (int i = 1; i < MAX_LEVEL; i++) {if (random.nextInt() % 2 == 1) {level++;}}return level;}
函数中,MAX_LEVEL 表示我定义的索引的最大高度,该函数会生成一个 1 ~ MAX_LEVEL 的随机高度,从概率上来讲,能够保证跳表的索引大小和数据大小的平衡性,以及各个节点的“索引高度”的平衡性。
二:查询元素
代码链接🔗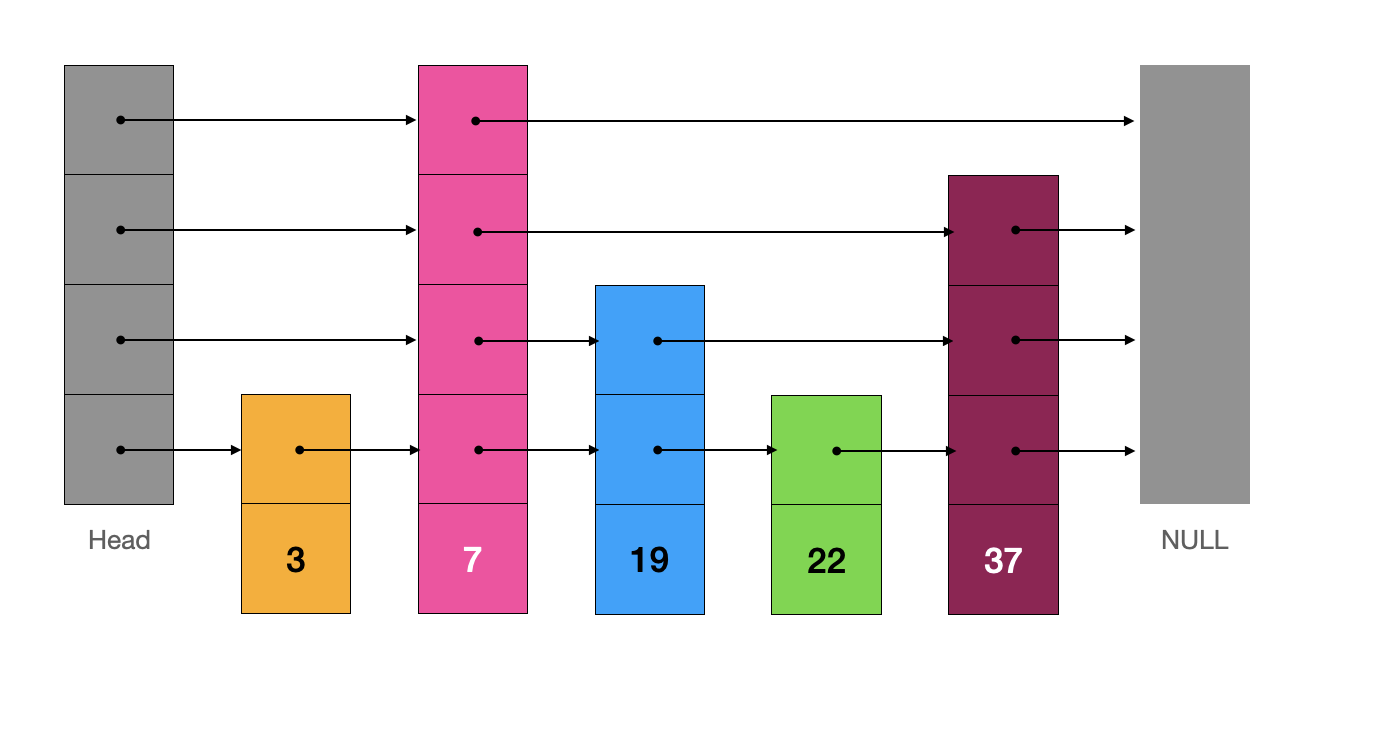
例如,从当前跳表查找元素“19”
我们从虚拟头节点“Head”出发,如果当前节点的索引指向的下一个节点不为空且值比我们寻找的目标值小,就“向右移动”指针,否则就“向下移动”指针,直至我们找到该元素返回 true 或找不到该元素返回 false。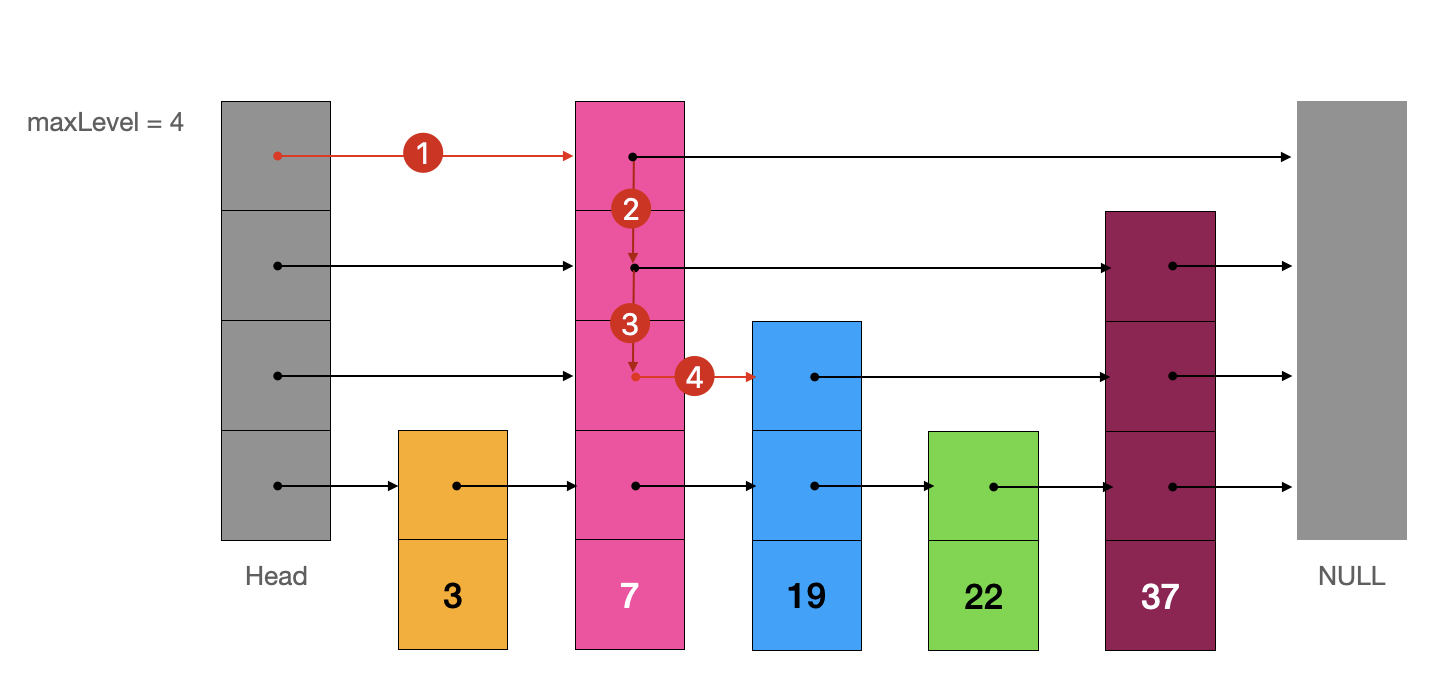
代码如下:
public boolean contains(E e) {Node cur = head;for (int i = maxLevel - 1; i >= 0; i--) {while (cur.next[i] != null && cur.next[i].e.compareTo(e) < 0) {cur = cur.next[i];}if (cur.next[i] != null && cur.next[i].e.equals(e)) {return true;}}return false;}
三:动态插入与删除元素
代码链接🔗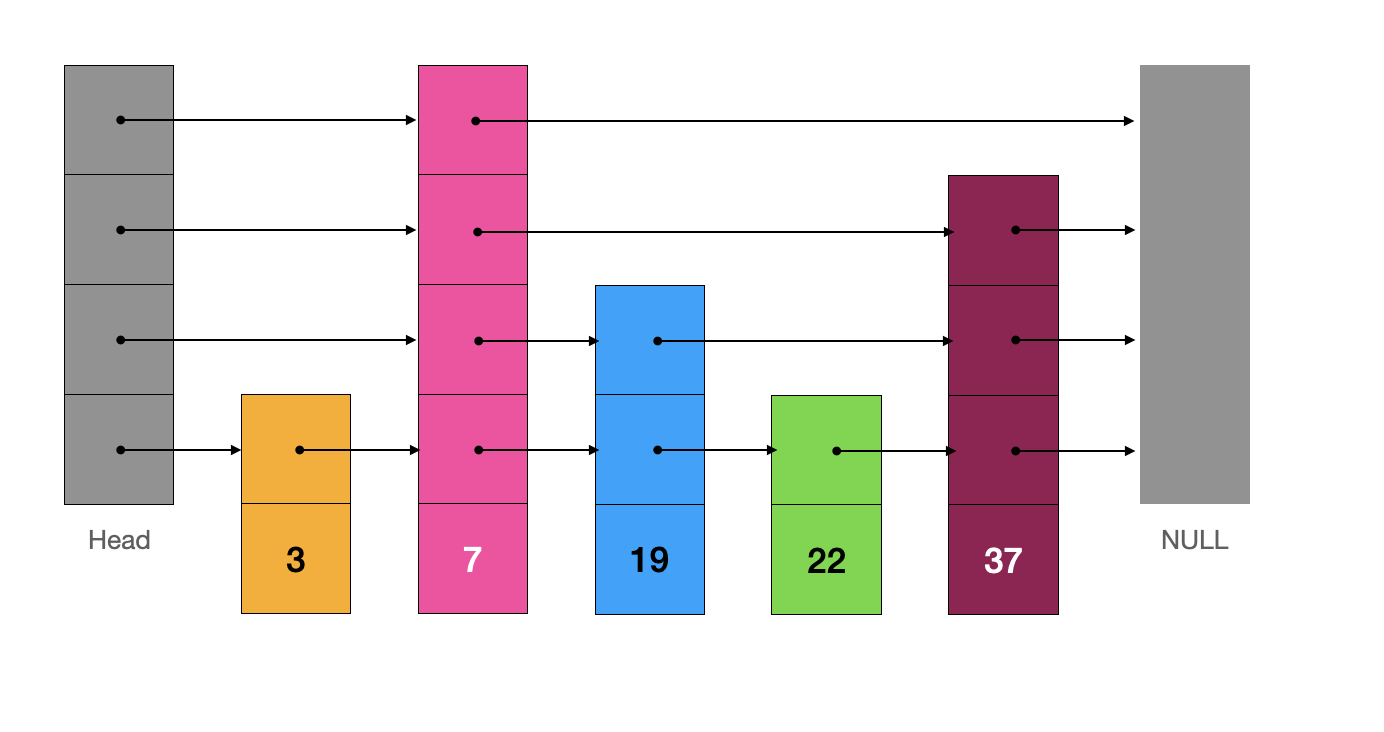
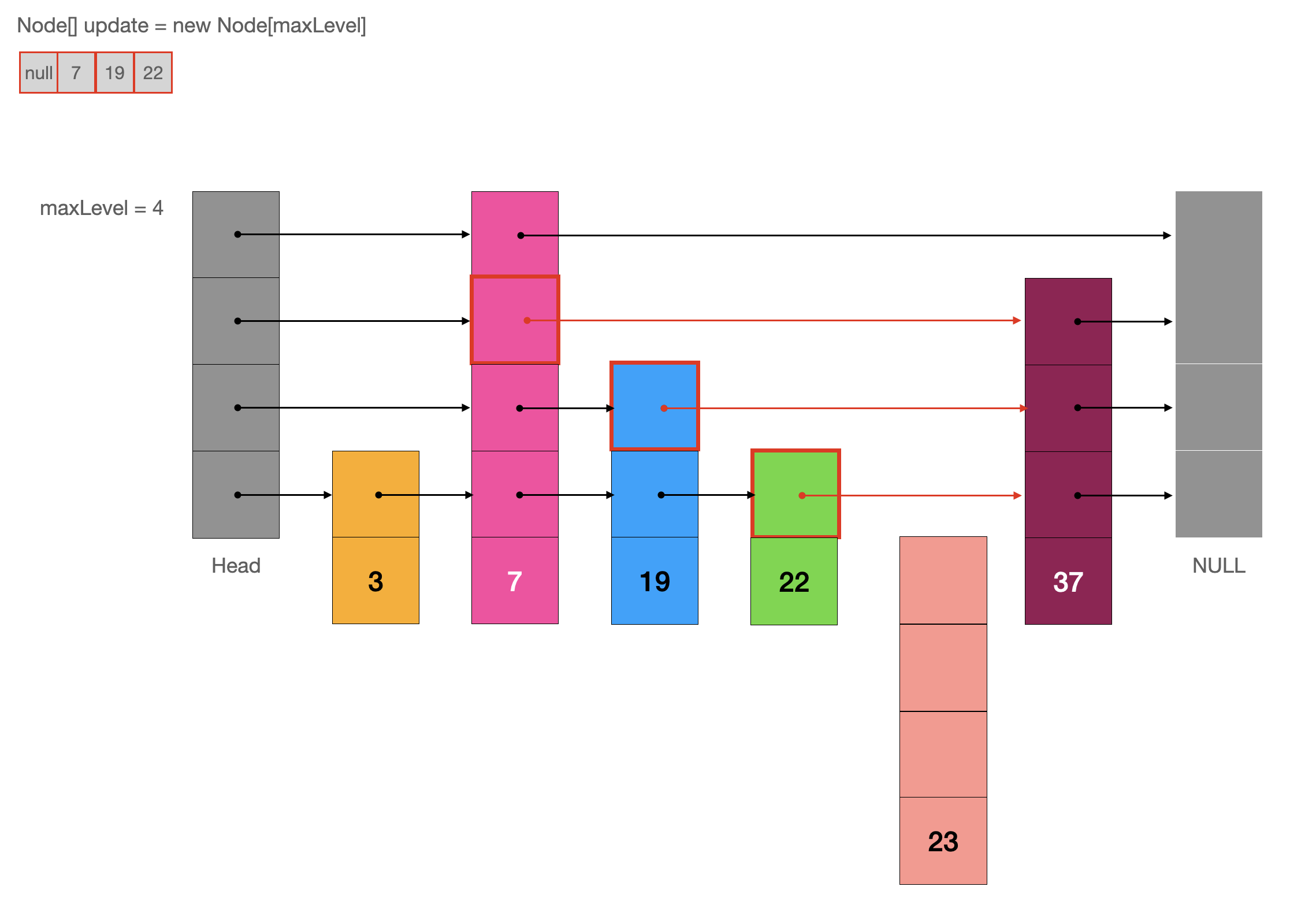
例如,向当前跳表中插入元素 “23”。
首先,生成待插入节点“23”的索引的随机层数,如果随机层数超过了 maxLevel 则需要更新 maxLevel 的值。
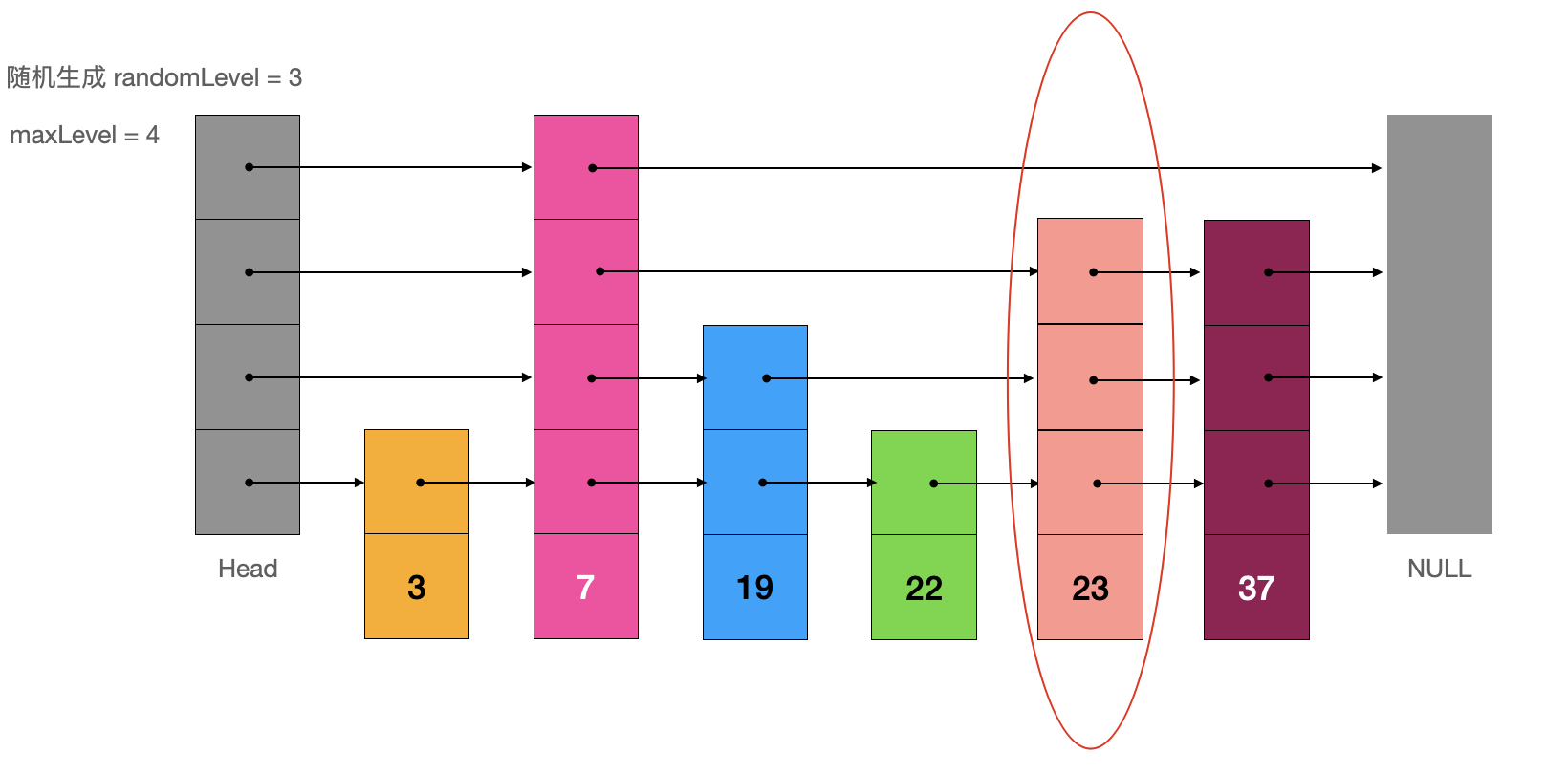
整体的流程实际上和查询节点的流程差不多,详细代码请参考链接,这里就不再赘述了。
如果我们要删除跳表元素 “23”,则需要找到每一个指向 “23” 的索引,我们可以使用一个数组来保存每一个指向 “23” 的索引,然后再遍历这个数组,完成删除节点的操作。
四:跳表的复杂度分析
跳表的复杂度分析证明比较困难,大家可以参考这篇文章:Skip Lists: A Probabilistic Alternative to Balanced Trees。
在这里,我们换一种思路来证明跳表的查询,添加,删除元素的复杂度。
假设我们的跳表是“绝对完美的”:
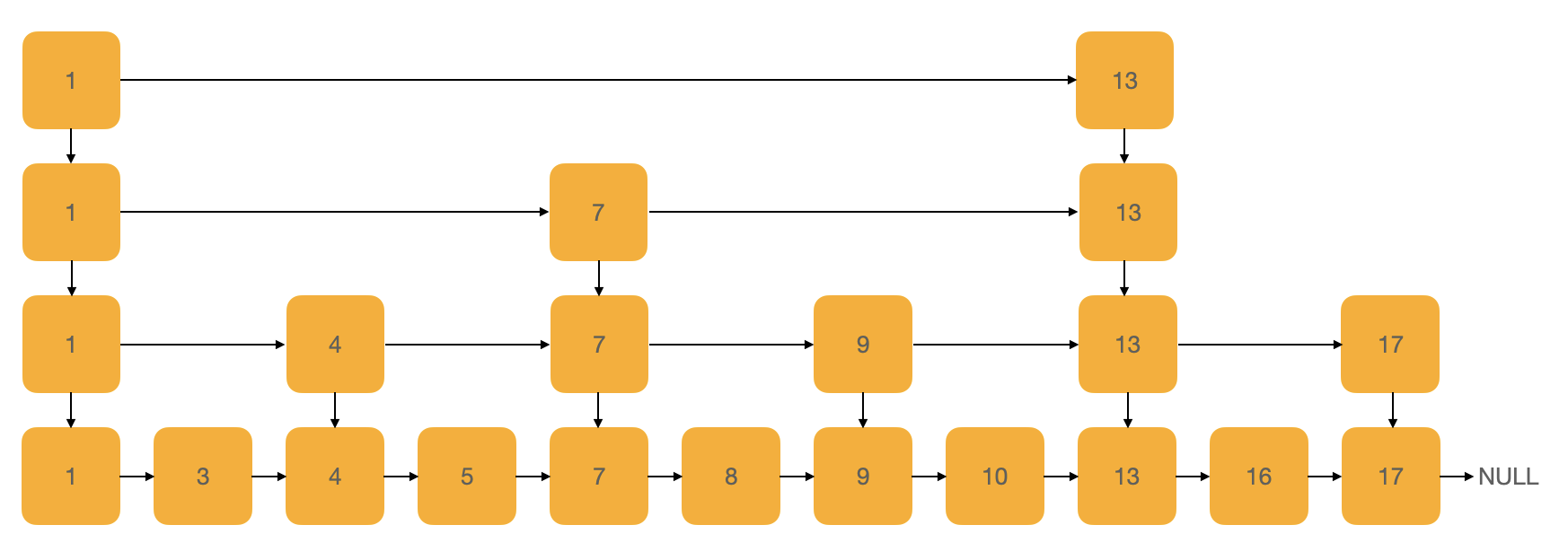
一个具有“绝对完美“的多级索引的跳表,查询某个数据的时间复杂度是多少呢?
假设跳表有 n 个节点,我们将每两个节点抽出一个节点作为上一级索引的节点,那么第一级索引的节点个数大约就是 n/2,第二级索引的节点个数大约就是n/4,第三级索引的节点个数大约就是n/8。
以此类推,第k级索引节点的个数就是: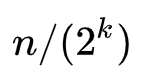
假设索引有 h 级,最高级的索引有 2 个节点。通过上面的公式,我们可以得到: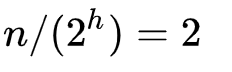
从而求得: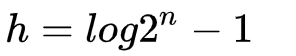
我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
那么这个 m 值是多少呢?
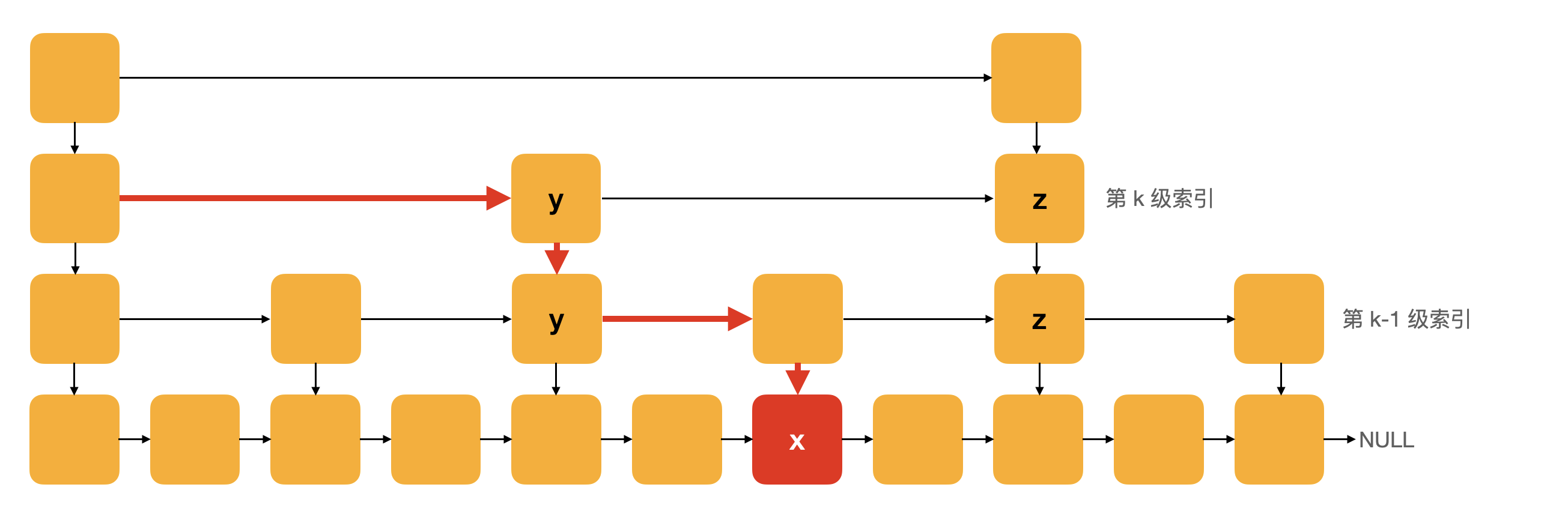
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 节点之后,发现 x 大于 y,小于后面的节点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个节点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个节点,依次类推,每一级索引都最多只需要遍历 3 个节点。所以,m = 3。
所以,通过上面的分析,从一个具有“绝对完美“的多级索引的跳表中查询数据的时间复杂度为 O(logN),这个查找的时间复杂度和二分查找的原理是一样的。同理,添加,删除一个元素的时间复杂度也是 O(logN)。
如果跳表使用随机数发生器来生成一个节点的“索引高度”,那么通过求解数学期望,得到的结论是,在跳表中查询,添加,删除一个节点的复杂度为 O(logN)。在这里,我们就不给出详细的证明了,大家可以查看我给出的资料自行研究。
究竟我们的跳表性能如何,在这里我使用了十万这个量级的数据对 SkipList 和 LinkedList 的 contains 方法进行了测试:
private static Array<Integer> generateRandomArray() {Array<Integer> array = new Array<>();Random random = new Random();for (int i = 0; i < 100000; i++) {array.addLast(random.nextInt(100000));}return array;}private static double testSkipList(SkipList<Integer> skipList, Array<Integer> array) {long startTime = System.nanoTime();for (int i = 0; i < 100000; i++) {skipList.contains(array.get(i));}long endTime = System.nanoTime();return (endTime - startTime) / 1000000000.0;}private static double testLinkedList(LinkedList<Integer> linkedList, Array<Integer> array) {long startTime = System.nanoTime();for (int i = 0; i < 100000; i++) {linkedList.contains(array.get(i));}long endTime = System.nanoTime();return (endTime - startTime) / 1000000000.0;}@Testvoid SkipListPerformanceTest() {SkipList<Integer> skipList = new SkipList<>();LinkedList<Integer> linkedList = new LinkedList<>();for (int i = 0; i < 10000; i++) {skipList.add(i);linkedList.addLast(i);}Array<Integer> array = generateRandomArray();double time1 = testSkipList(skipList,array);double time2 = testLinkedList(linkedList,array);System.out.println("SkipList contains : " + time1 + " s");System.out.println("LinkedList contains : " + time2 + " s");}
在我的电脑上,该测试的输出结果为:
SkipList contains : 0.057014315 sLinkedList contains : 22.497140002 s
我们可以看到,二者的性能差异是巨大的,我们的跳表查询效率比链表要高很多。
五:为什么 Redis 要用跳表来实现有序集合,而不是红黑树
Redis 中有序集合就是通过跳表 + 散列表来实现的。Redis 中有序集合支持的核心操作主要有下面几个:
- 插入一个数据
- 删除一个数据
- 查找一个数据
- 按照区间查找数据(比如查找值在 [100,356] 之间的数据)
- 迭代输出有序序列
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
当然,Redis 之所以用跳表来实现有序集合,还有其他原因,比如,跳表比起红黑树的实现简直是容易多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
六:参考资料

若有收获,就点个赞吧
0 人点赞
