【数据结构与算法基础】代码仓库:https://github.com/jinrunheng/datastructure-and-algorithm
一:二分搜索树基础
什么是树?
树(tree)是一种用来模拟具有树状结构性质的数据集合。它是由 n(n > 0)个有限节点组成的一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说,它是根朝上,而叶朝下的。
树这种数据结构具有以下的特点:
- 每个节点都只有有限个字节点或无子节点
- 没有父节点的节点称为根节点
- 每一个非根节点有且只有一个父节点
- 除了根节点外,每个子节点可以分为多个不相交的子树
- 树里面有没环路(cycle)
树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 非终端节点或分支节点:度不为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第 1 层,根的子节点为第 2 层,以此类推;
- 深度:对于任意节点 n,n 的深度为从根到 n 的唯一路径长,根的深度为 0;
- 高度:对于任意节点 n,n 的高度为从 n 到一片树叶的最长路径长,所有树叶的高度为 0;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由 m( m >= 0)棵互不相交的树的集合称为森林;
二分搜索树(Binary Search Tree)
在了解什么是二分搜索树之前,我们先要了解一下,什么是二叉树(Binary Tree)。
二叉树是树形结构的一个重要类型,其特点为每个节点最多只能有两个子节点,分别称为左孩子与右孩子。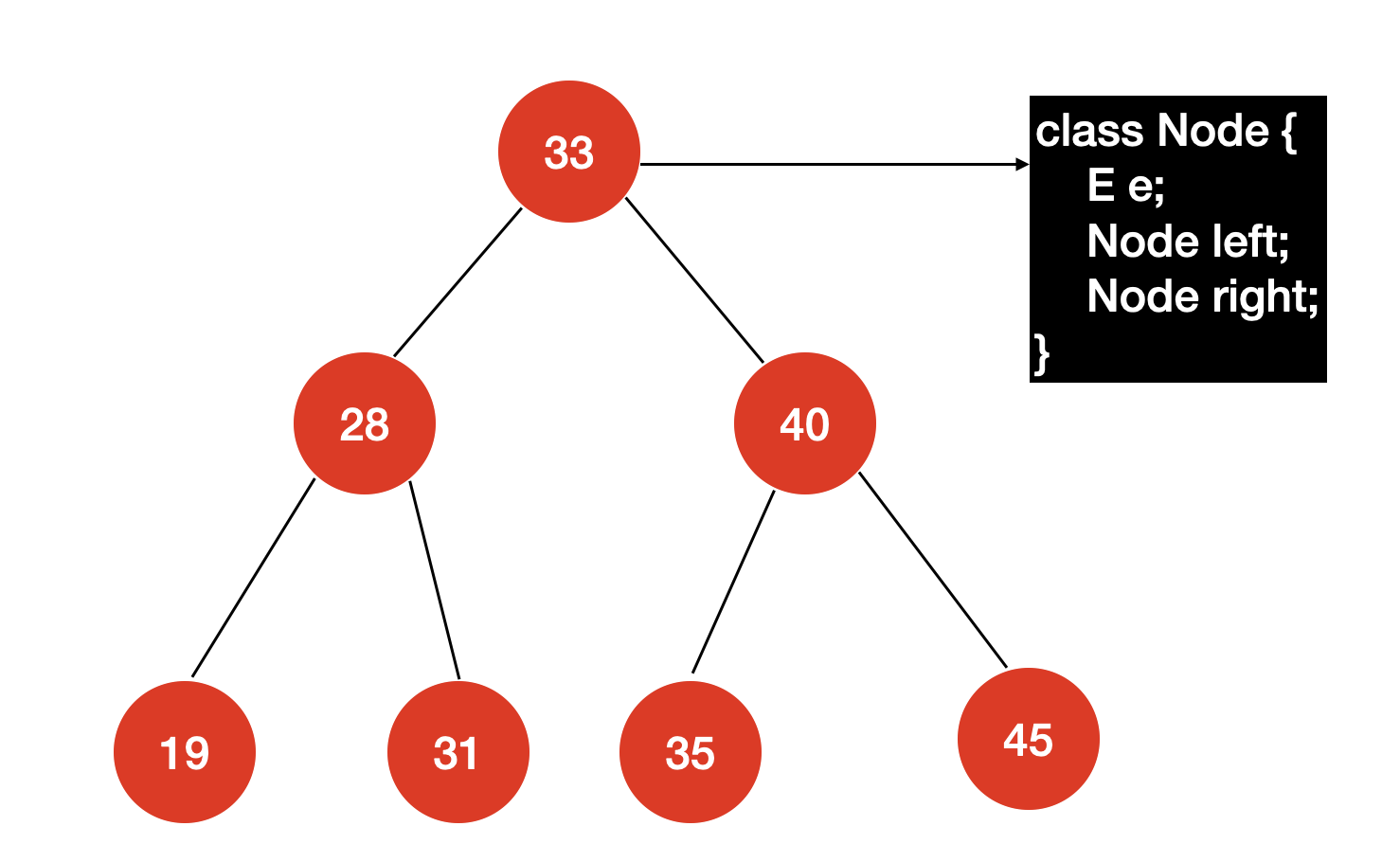
那么什么是二分搜索树(Binary Search Tree)呢?
我们给出的示意图就是一棵二分搜索树:
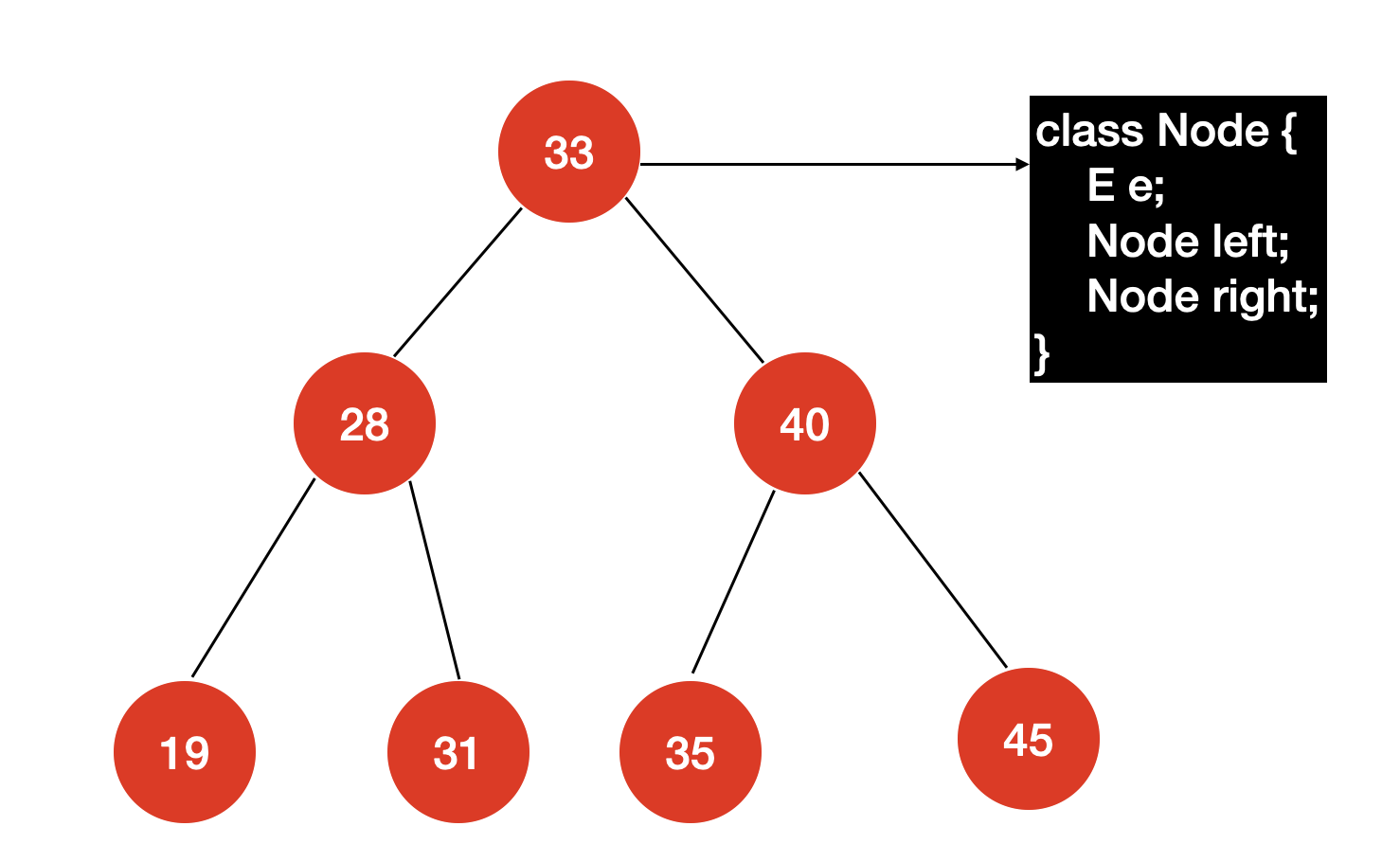
首先,二分搜索树是一棵二叉树,并且二分搜索树有一个特点:二分搜索树的每个节点的值都要大于其左子树的所有节点的值,且小于其右子树的所有节点的值。这也间接地说明,二叉搜索树的节点存储的元素必须具有可比较性。
因为树具有天然的递归性质,所以一棵二分搜索树的每一棵子树也是二分搜索树。
二:二分搜索树的基本操作
【注意⚠️:我们实现的二分搜索树不包含重复的节点(节点值相等即认为重复)】
向二分搜索树中添加元素
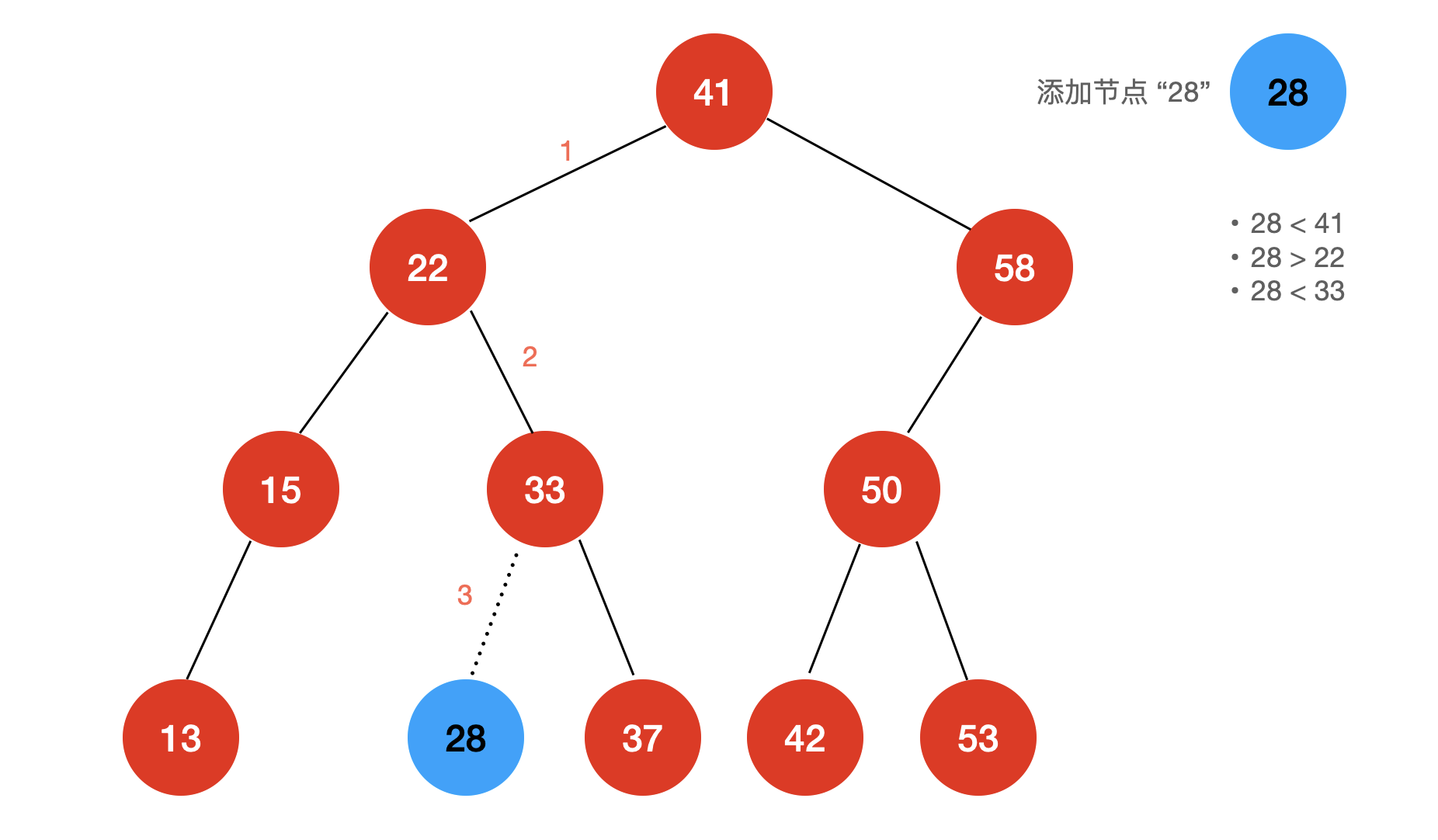
如果当前二分搜索树的根节点为空,新插入的节点就会成为根节点。
如果当前二分搜索树的根节点不为空,就让根作为当前比较的节点:新插入的节点与当前节点进行比较;如果值比当前节点小就要“向左走”,如果值比当前节点大就要“向右走”,然后让下一层的节点作为当前比较的节点,直至走到应该插入的位置,我们的逻辑实际上就是递归的逻辑。
下图为在当前的二分搜索树中添加节点“28”的流程:
向二分搜索树中查询一个元素是否存在
向二分搜索树中查询和修改元素的逻辑和添加元素实际上是一样,我们还是从根出发,根作为当前比较的节点:如果值和当前的节点相等,那么就说明我们找到了该元素;否则,如果值比当前节点小就要“向左走”,如果值比当前节点大就要“向右走”,递归我们的算法。
如果我们走到了叶子节点,仍然没有找到该元素,那么就说明当前的二叉搜索树中没有该元素。
向二分搜索树中删除元素
删除二分搜索树的最大元素和最小元素
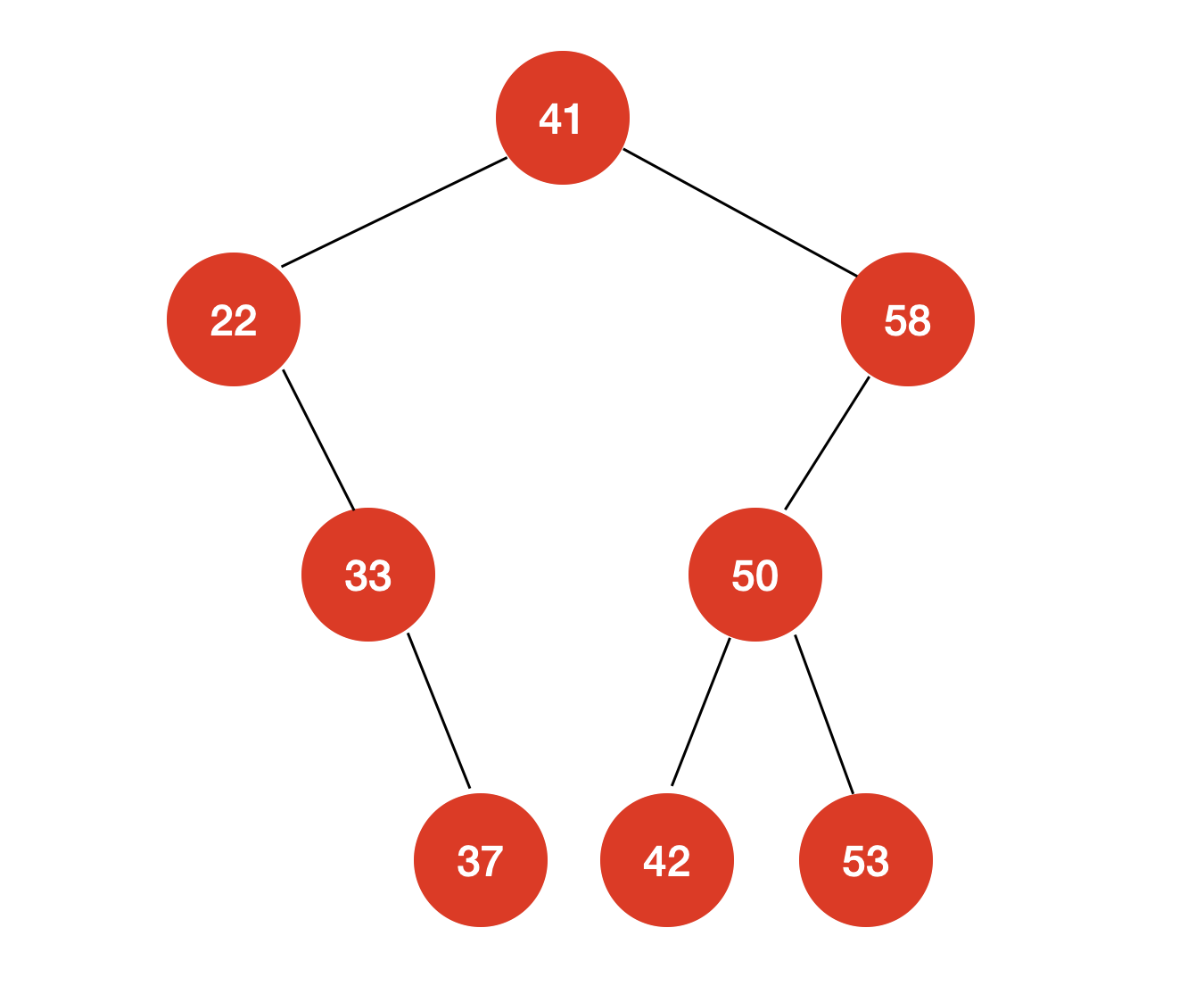
二分搜索树最小的元素代表的节点就是沿着根“向左走”,“最左”的那个节点;二分搜索树最大的元素代表的节点就是沿着根“向右走”,“最右”的那个节点。
对于上图所示的二分搜索树,最小元素为 “22”,最大元素为 “58”。
如果“最左的节点”没有右子树,那么我们只需要删除这个节点即可,无需对整棵二分搜索树做任何调整;如果“最左的节点”有右子树,那么我们就将“最左的节点”的右孩子取代这个节点的位置:
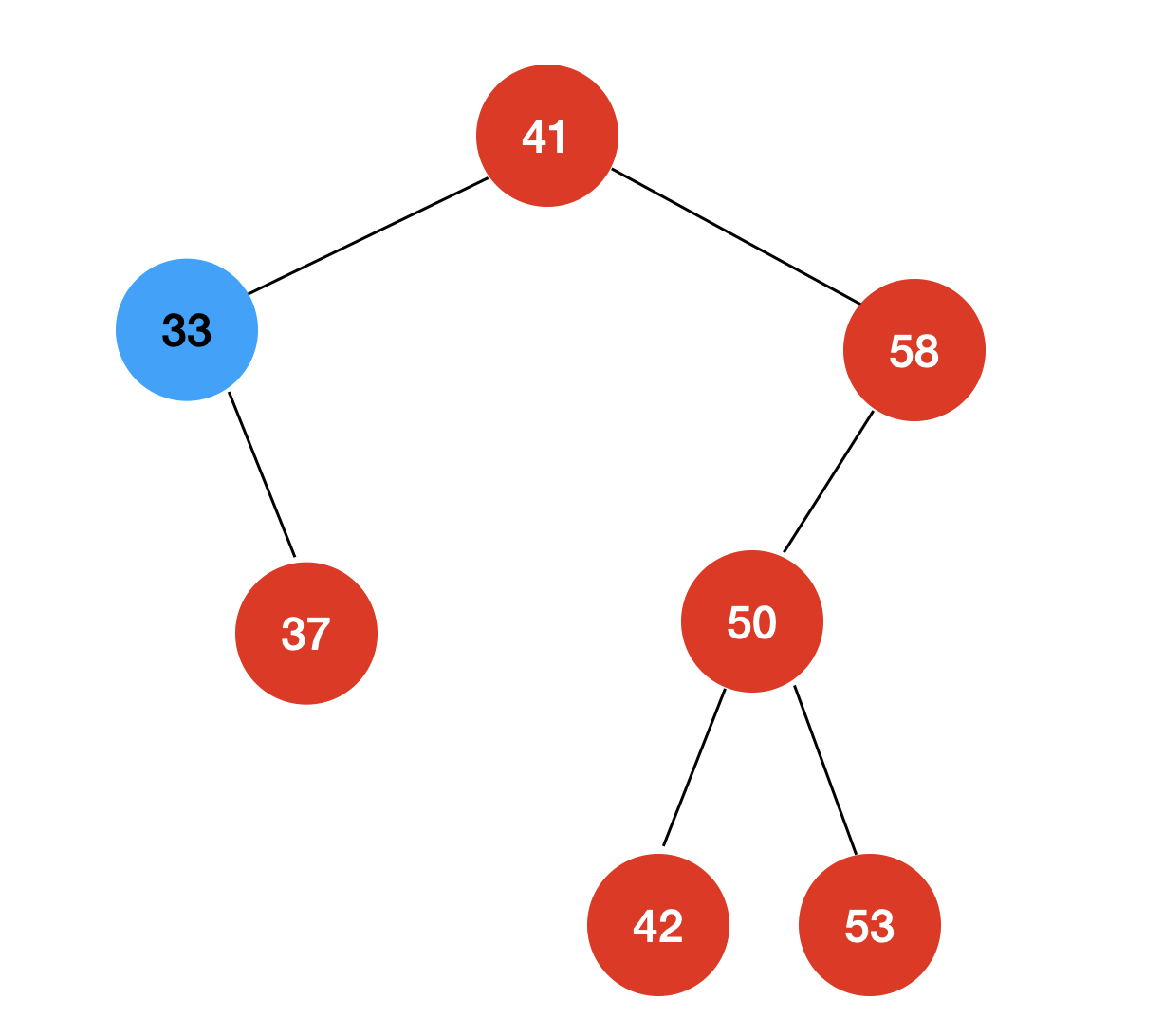
相同的,如果“最右的节点”没有左子树,那么我们只需要删除这个节点即可,无需对整棵二分搜索树做任何调整;如果“最右的节点”有左子树,那么我们就将“最右的节点”的左孩子取代这个节点的位置:
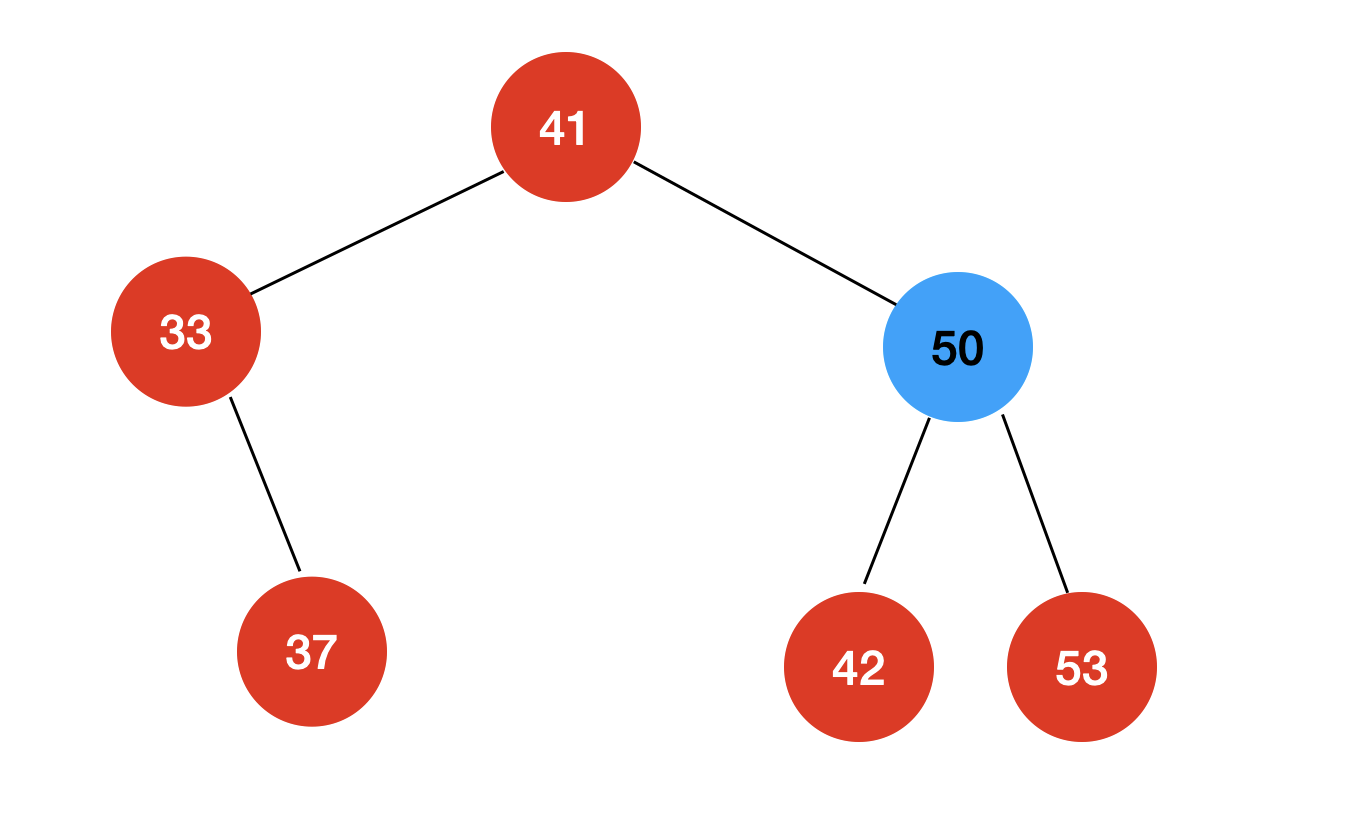
删除二分搜索树的任意元素
如果我们删除的节点只有左子树没有右子树
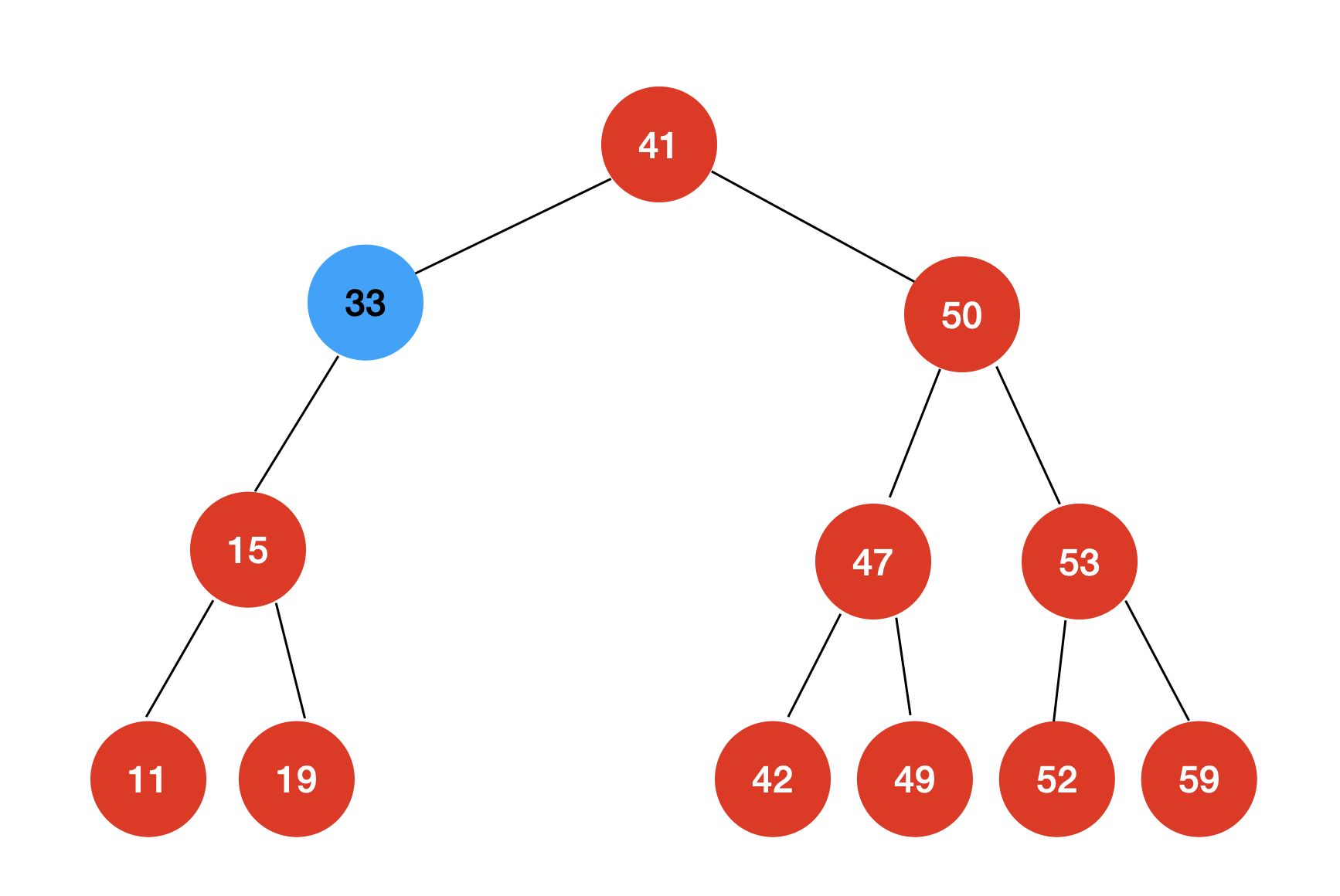
我们只需要让删除节点的左孩子取代删除节点的位置即可。
如果我们删除的节点只有右子树没有左子树
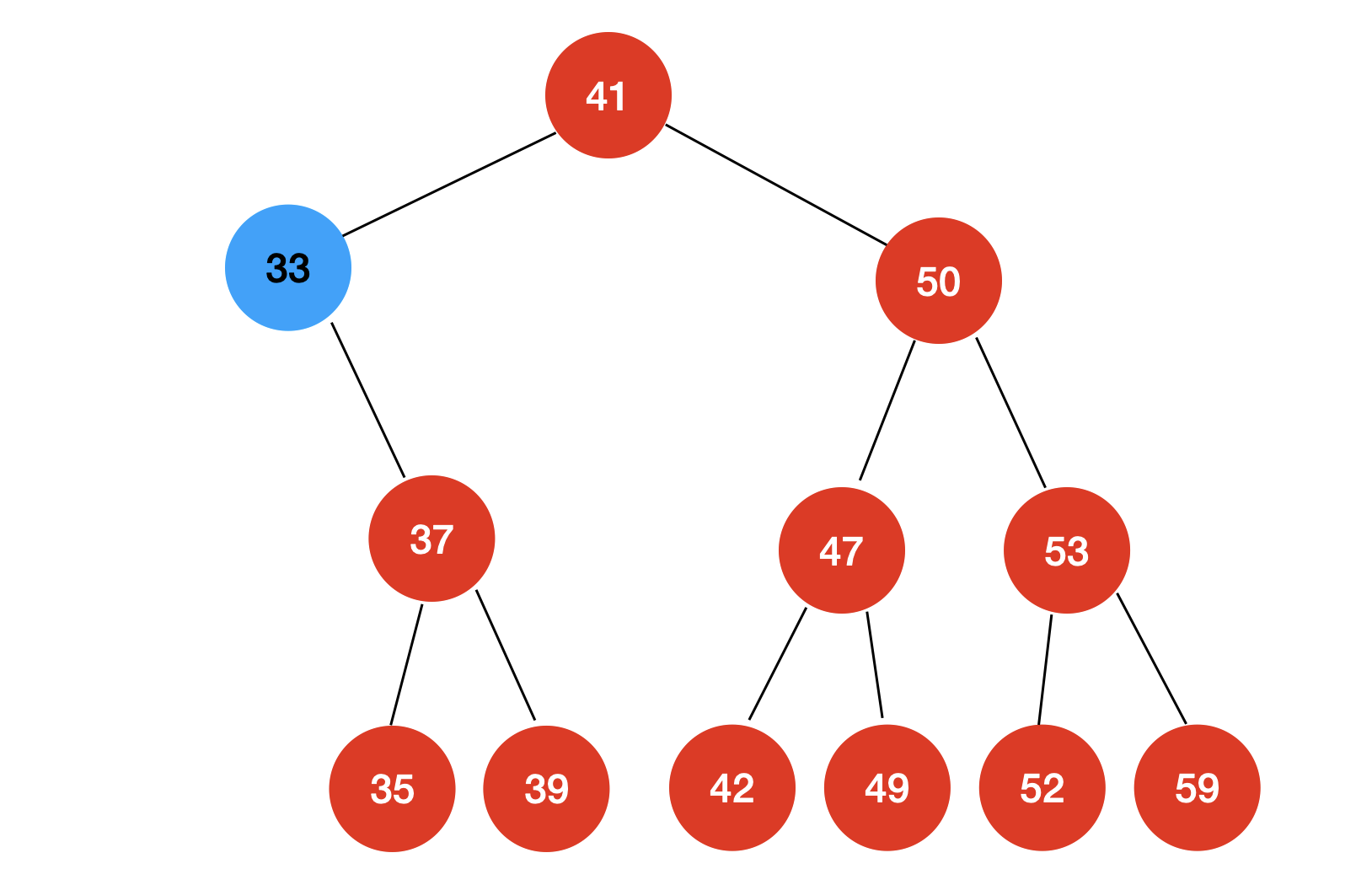
我们只需要让删除节点的右孩子取代删除节点的位置即可。
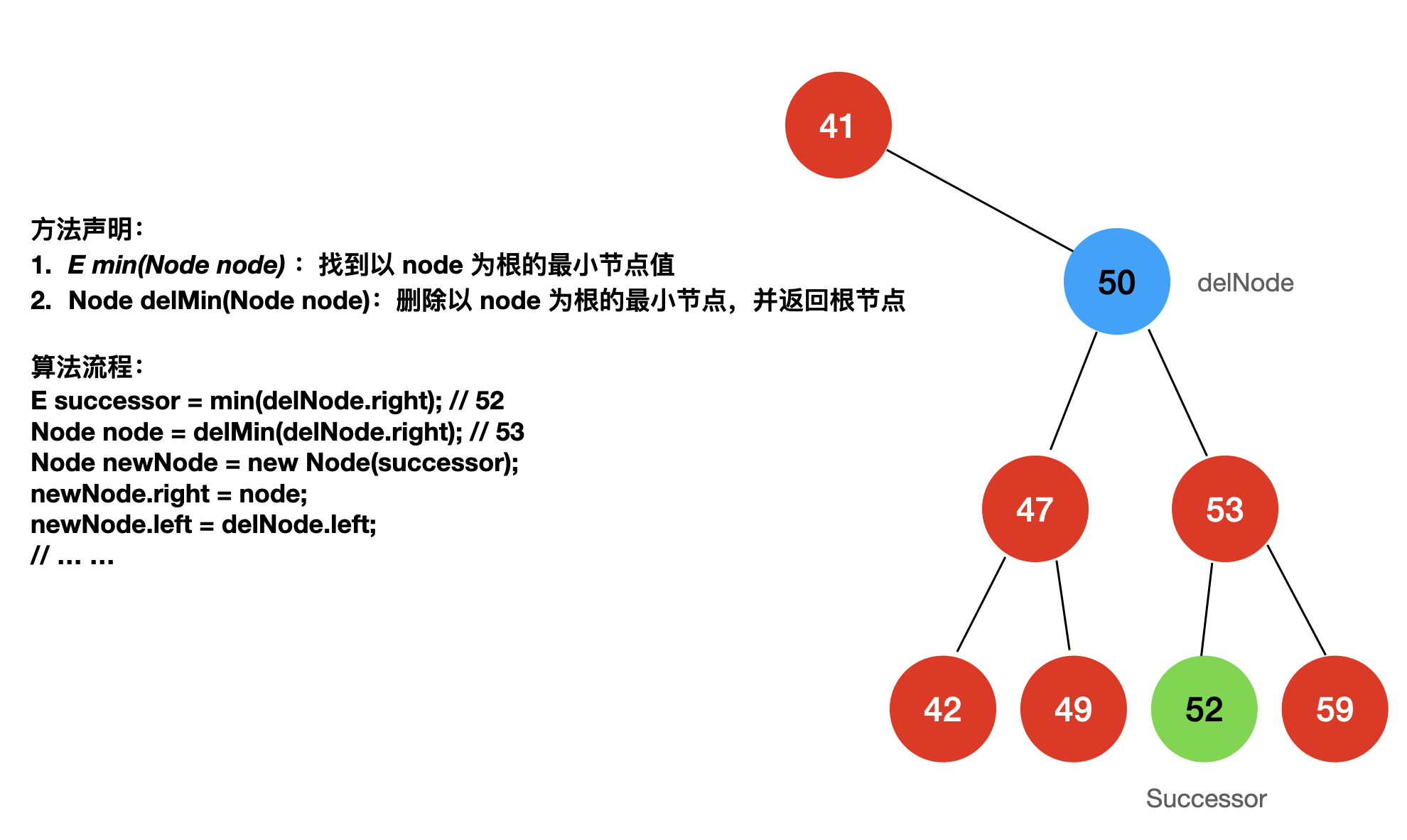
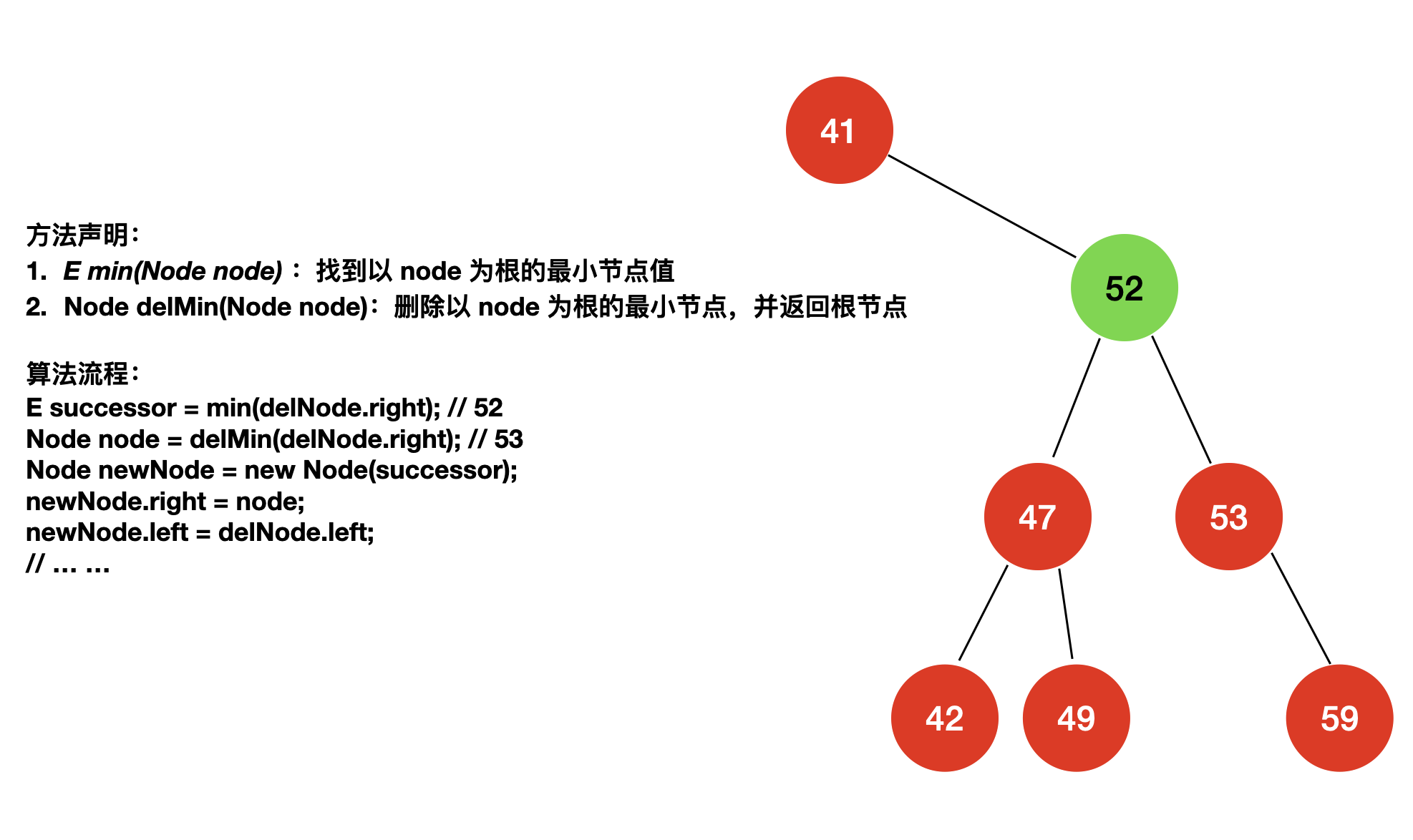
如果我们删除的元素既有左子树也有右子树
如果我们删除的节点既有左子树也有右子树该怎么办呢?
1962 年,一位计算机科学家 Hibbard 提出了一种算法,叫做 Hibbard Deletion,如果我们要删除一个既有左子树也有右子树的节点,首先需要找到待删除节点的后继节点(successor),对二叉树进行中序遍历,按照中序遍历的顺序寻找该节点的下一个节点即为该节点的后继节点。
对于二分搜索树而言,待删除节点的后继节点就是该节点右子树“最左的”那个节点,将后继节点替换待删除的节点就完成了删除操作。
除了寻找待删除节点的后继节点,我们还可以寻找待删除节点的前驱节点(precursor),对于二分搜索树而言,待删除节点的前驱节点就是该节点左子树“最右的”那个节点。将前驱节点替换待删除的节点同样是可行的,在这里我就使用后继节点的思路了。
三:二分搜索树的遍历
对于二叉树树的遍历,就是将树的所有节点都访问一遍;根据访问方式可以分为:
- 前序遍历
- 中序遍历
- 后序遍历
二叉树的前序遍历
前序遍历的访问顺序为:
- 先访问根节点
- 再访问左子树
- 最后访问右子树
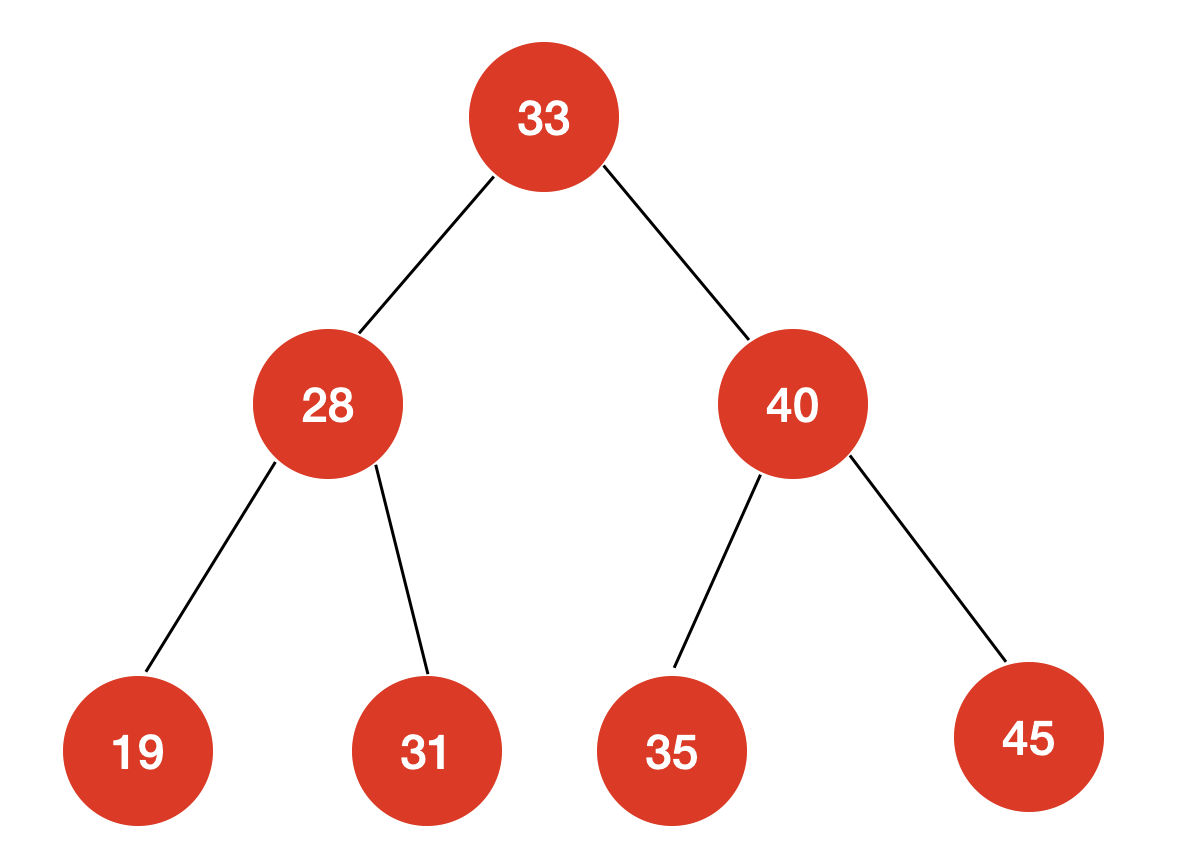
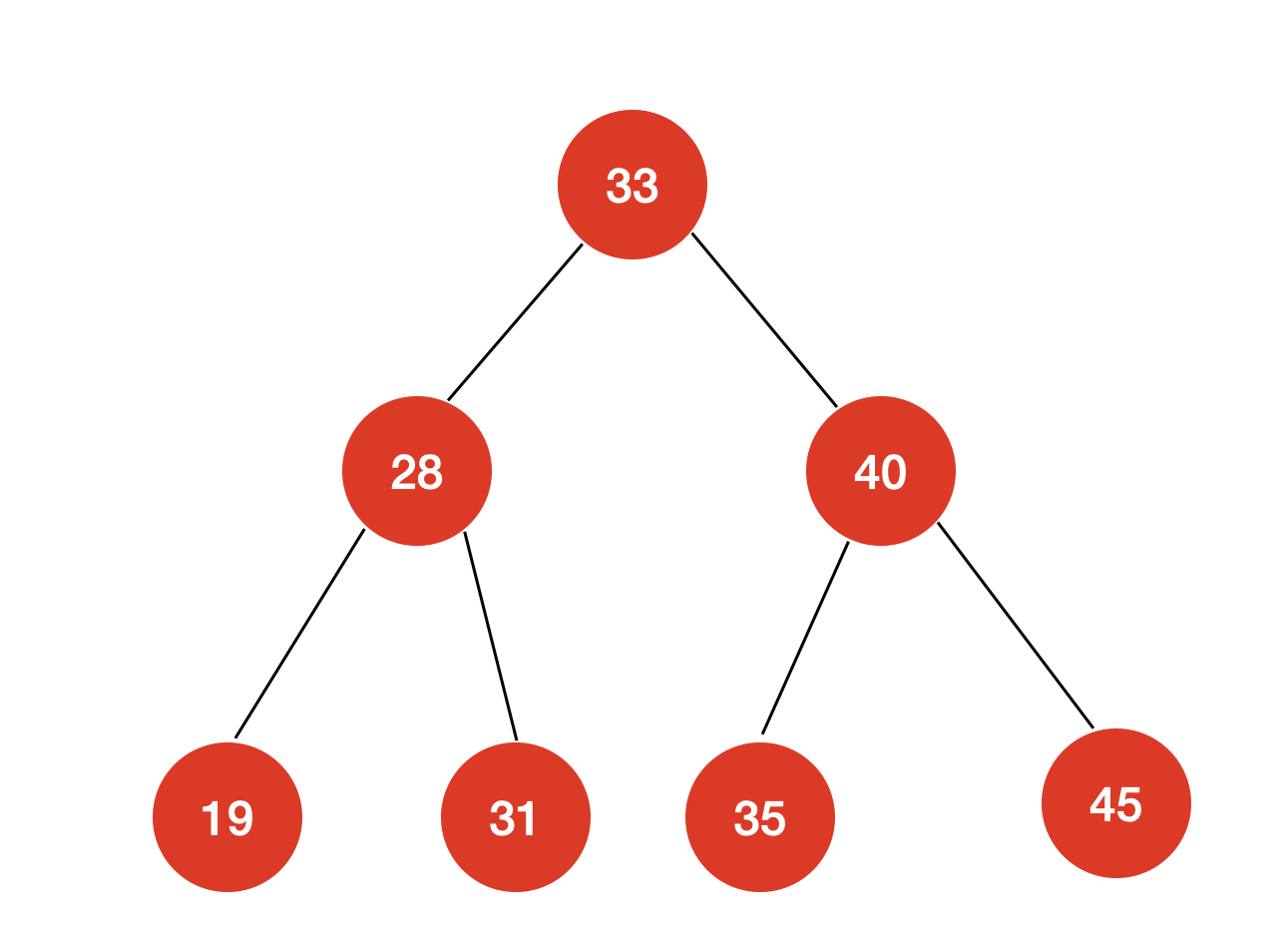
例如对这样一棵二叉树,前序遍历的结果为:
[33,28,19,31,40,35,45]
递归算法:
public void preOrder(Node node) {if (node == null) {return;}System.out.println(node.e);preOrder(node.left);preOrder(node.right);}
非递归算法:
public void preOrder(Node node){if(node != null){Stack<Node> stack = new Stack<>();stack.push(node);while(!stack.isEmpty()){node = stack.pop();System.out.println(node.e);if(node.right != null)stack.push(node.right);if(node.left != null)stack.push(node.left);}}}
二叉树的中序遍历
中序遍历的访问顺序为:
- 先访问左子树
- 再访问根节点
- 最后访问右子树
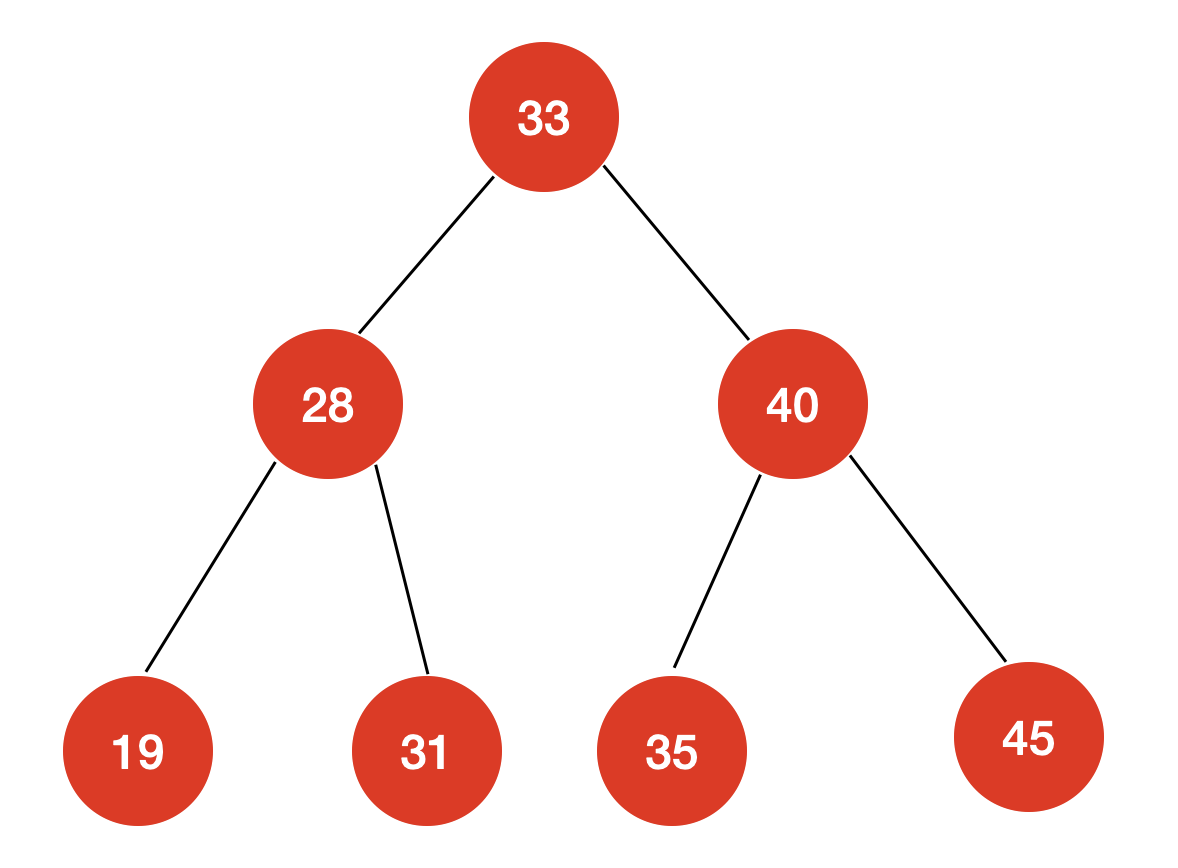
例如对这样一棵二叉树,中序遍历的结果为:
[19,28,31,33,35,40,45]
我们发现,对于一棵二分搜索树,它的中序遍历的结果就是对其所有节点排序后的结果
递归算法:
public void inOrder(Node node) {if (node == null) {return;}inOrder(node.left);System.out.println(node.e + " ");inOrder(node.right);}
非递归算法:
/*** @param node 中序遍历以 node 为根节点的二叉树*/public static void inOrder(Node node) {if (node != null) {Stack<Node> stack = new Stack<>();while (node != null || !stack.isEmpty()) {if (node != null) {stack.push(node);node = node.left;} else {node = stack.pop();System.out.println(node.e + " ");node = node.right;}}}}
二叉树的后序遍历
后序遍历的访问顺序为:
- 先访问左子树
- 再访问右子树
- 最后访问根节点
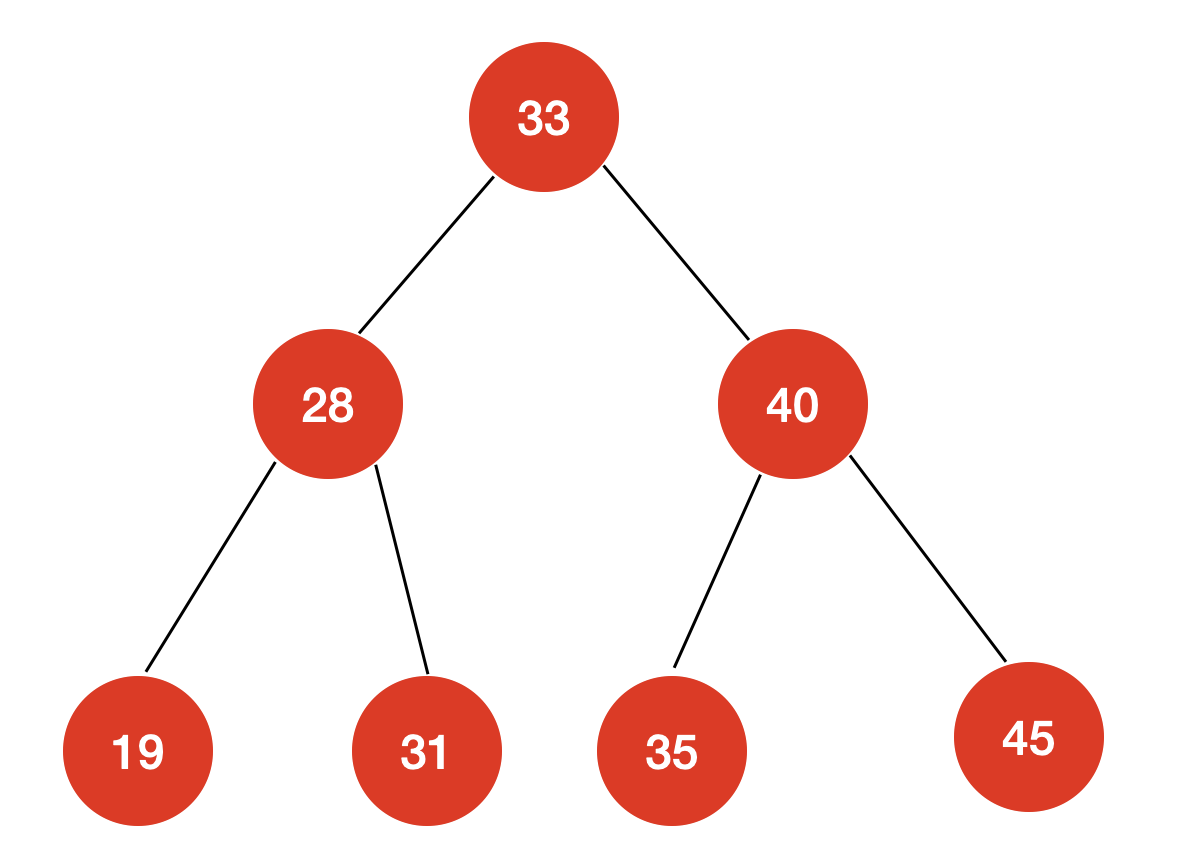
例如对这样一棵二叉树,后序遍历的结果为:
[19,31,28,35,45,40,33]
递归算法:
public void postOrder(Node node) {if (node == null) {return;}postOrder(node.left);postOrder(node.right);System.out.println(node.e + " ");}
非递归算法:
public static void postOrder(Node node) {if (node != null) {Stack<Node> stack1 = new Stack<>();Stack<Node> stack2 = new Stack<>();stack1.push(node);while (!stack1.isEmpty()) {node = stack1.pop();stack2.push(node);if (node.left != null)stack1.push(node.left);if (node.right != null)stack1.push(node.right);}while (!stack2.isEmpty()) {System.out.println(stack2.pop().e + " ");}}}
按层遍历二叉树
按层遍历二叉树就非常好理解了,从上到下,每一层从左到右遍历每一个节点即可。
代码如下:
public static void levelOrder(Node node) {if (node != null) {Queue<Node> queue = new LinkedList<>();queue.offer(node);while (!queue.isEmpty()) {node = queue.poll();System.out.println(node.e + " ");if (node.left != null)queue.offer(node.left);if (node.right != null)queue.offer(node.right);}}}

若有收获,就点个赞吧
0 人点赞
