【数据结构与算法基础】代码仓库:https://github.com/jinrunheng/datastructure-and-algorithm
一:队列
什么是队列
队列(Queue)与栈一样,也是一种运算受限的线性数据结构。栈的特性为 LIFO,队列的特性则是:FIFO(First In First Out)。
队列这种数据结构仅允许在一端(队尾)添加元素,在另一端(队首)删除元素,这种特性有点像排队一样。可以想象一下银行柜台处理业务时,所有人排成一队,队首的人先办理业务,后来的人排在队尾,等到他前面所有的人办理完毕后,才能轮到这个人办理相关的业务。
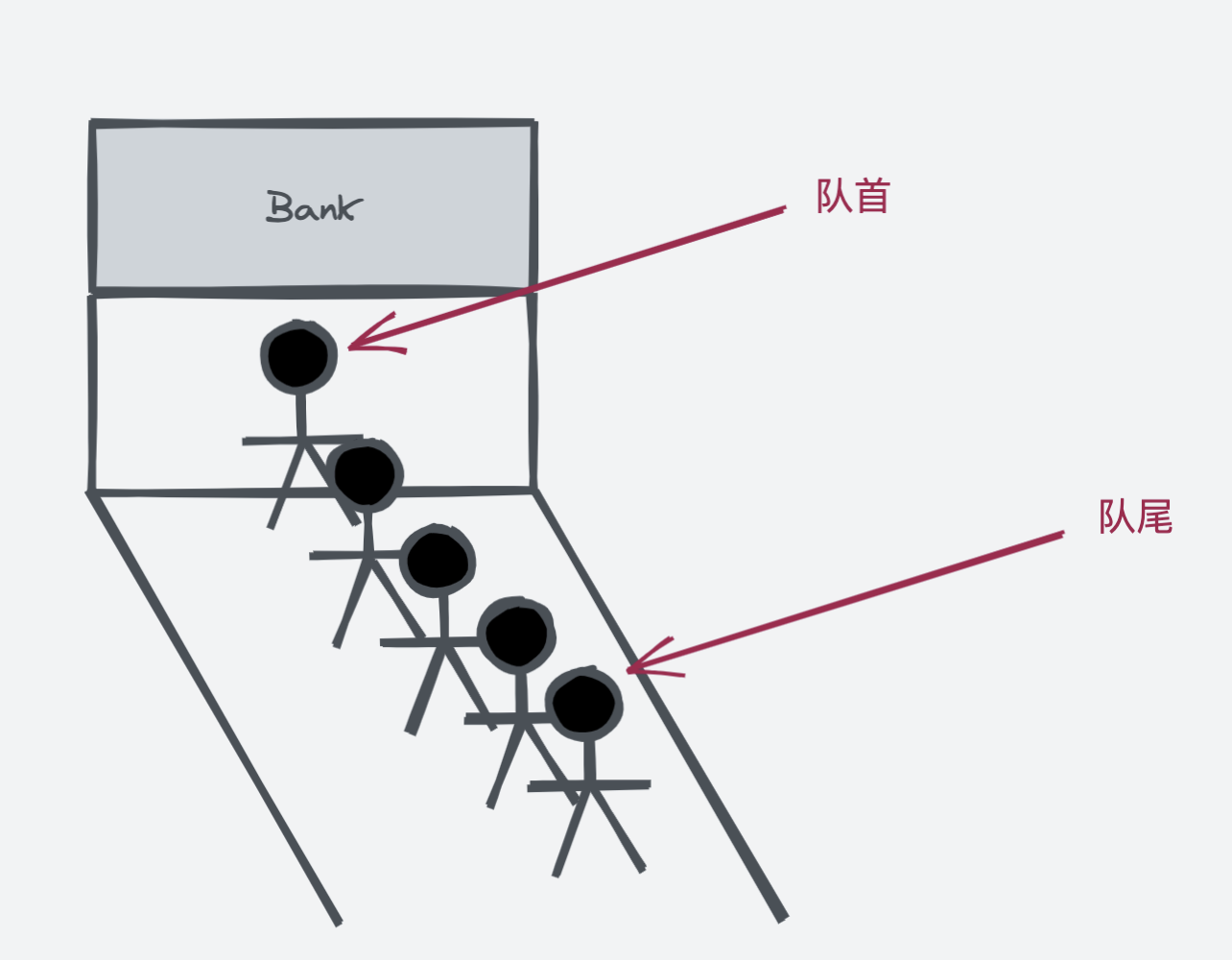
队列的实现
队列的设计上,只涉及到如下几个方法:
void enqueue(E)E dequeue()E getFront()int getSize()boolean isEmpty()
同栈类似,我们仍然选择使用我们自己实现的数据结构:动态数组 作为队列的底层实现。
队列的复杂度分析:
| enqueue | O(1) |
|---|---|
| dequeue | O(N) |
| getFront | O(1) |
| getSize | O(1) |
| isEmpty | O(1) |
除了 dequeue 方法,其他方法的复杂度均为 O(1);而 dequeue 操作相当于动态数组的 removeFirst 操作,如果删除数组头部元素,后面所有的元素都需要向前挪动一个位置,所以 dequeue 是一个时间复杂度为 O(N) 级别的操作。
二:循环队列
我们实现的队列中,dequeue 是一个复杂度为 O(N) 的操作。是否有可以优化 dequeue 操作的方法呢?
答案是可以的。
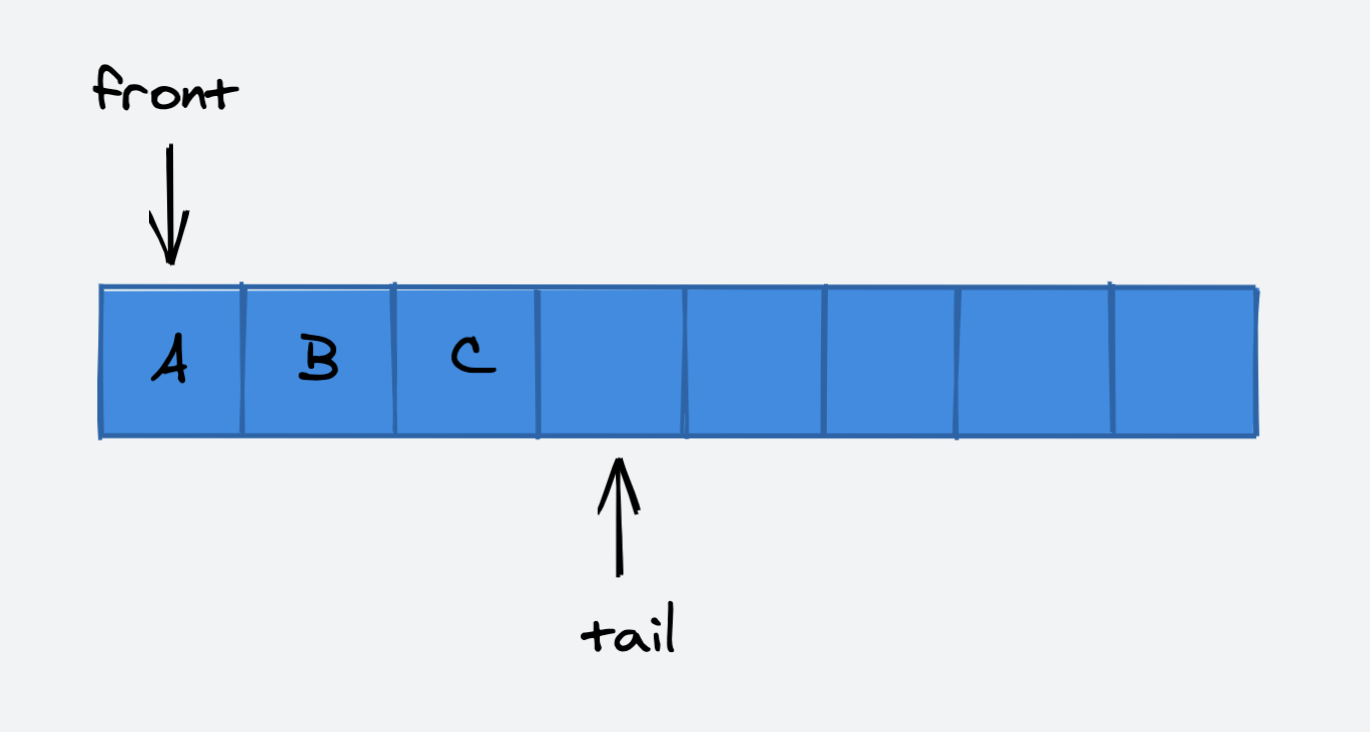
我们可以使用两个指针分别指向队列的队首和队尾,并使用循环指针的思想来节省空间与优化底层动态数组的扩容,如下图所示:
我们使用了两个指针,分别用来维护队列的对首和队尾,在队列为空时,两指针重合。

向队列中添加元素时,tail 指针移动:
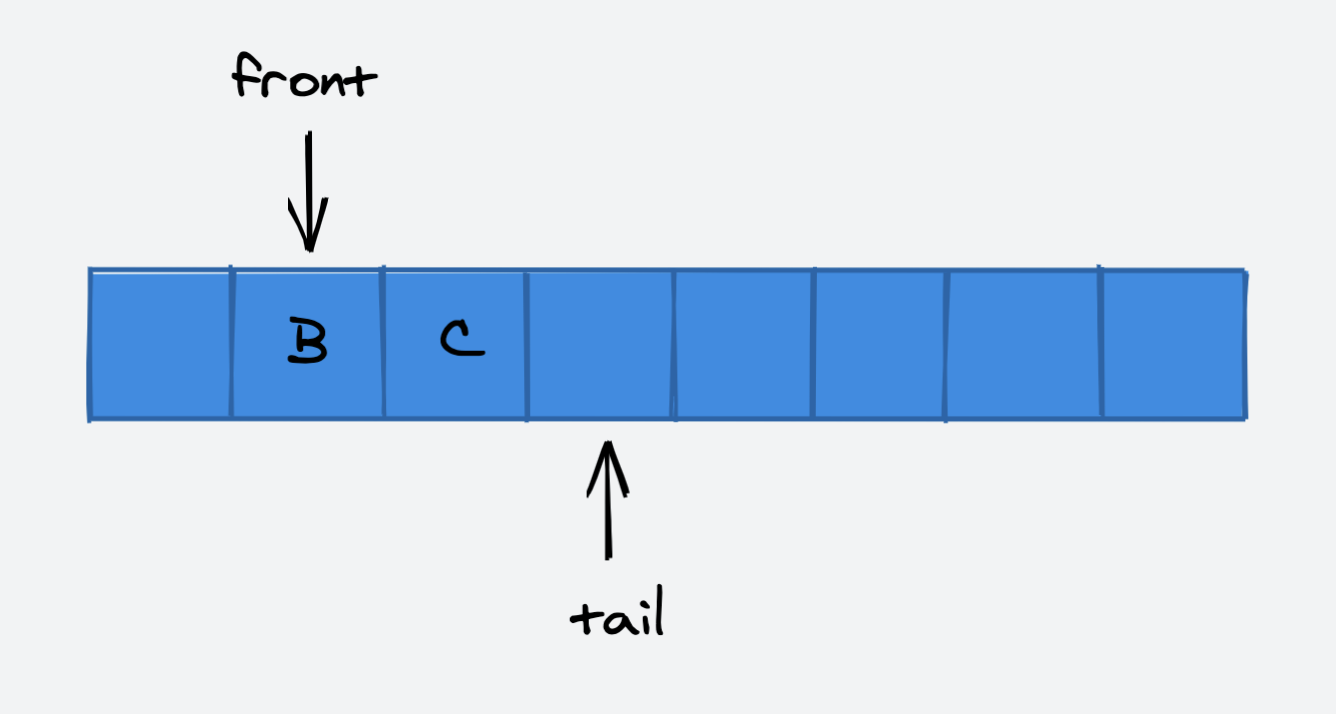
将队首元素出队时,front 指针移动:
我们很快就发现了一个问题:
因为我们队列的底层实现是动态数组,当 tail 指针指向了当前数组的最后一个空间时,再次向队列中添加一个元素会引发底层数组的扩容。但是很明显,我们的数组空间并没有完全利用上:
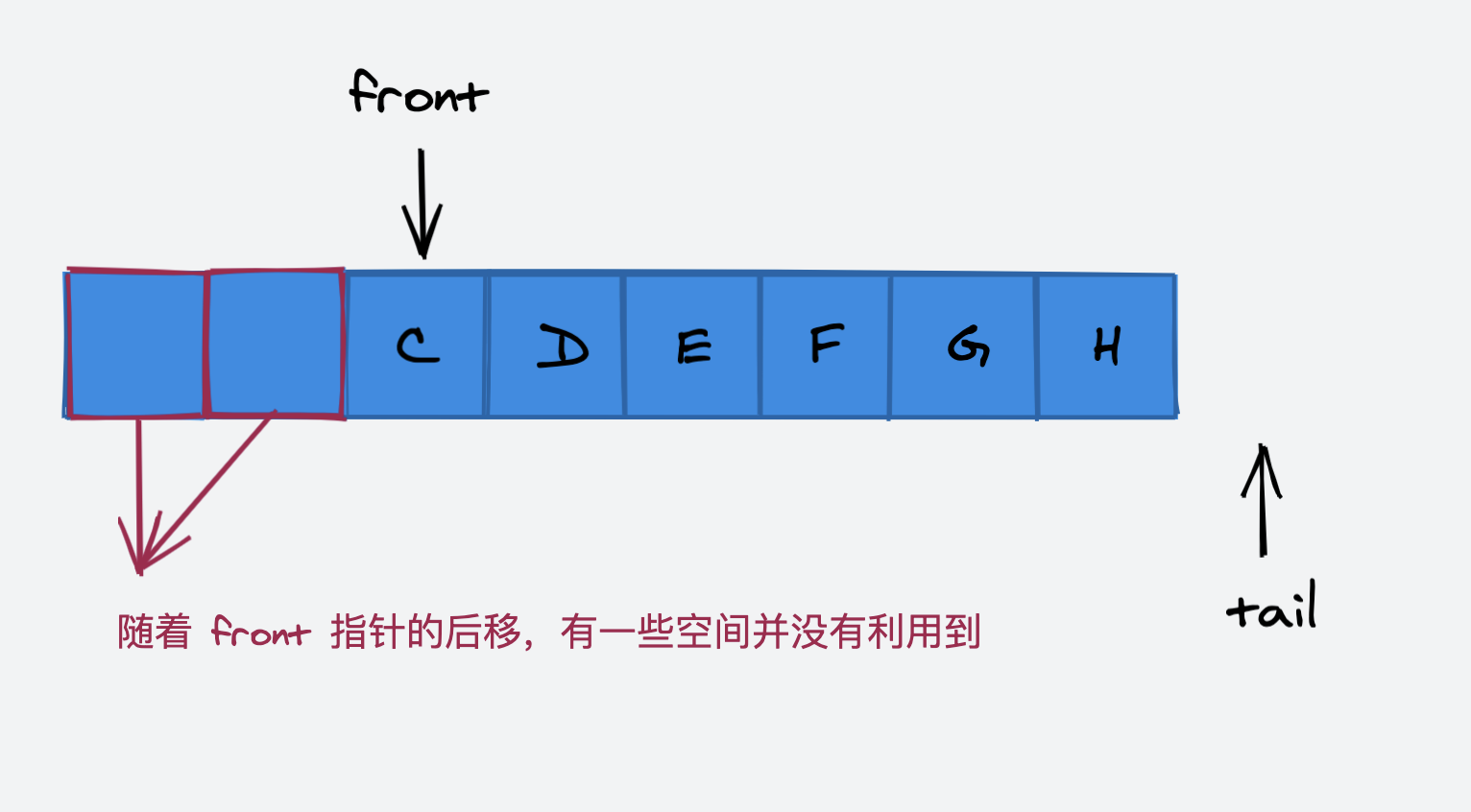
解决这个问题的方法就是使用循环指针。
因为我们已经用 **front == tail** 来表示队列为空,所以,我们刻意地浪费一个空间,用 **(tail + 1) % capacity == front**来表示当前队列为满。
我们再向当前队列中添加一个元素时,因为队列底层的数组仍然有多余的空间,所以不会引发扩容,而是将 tail 指针挪动到数组的头部:
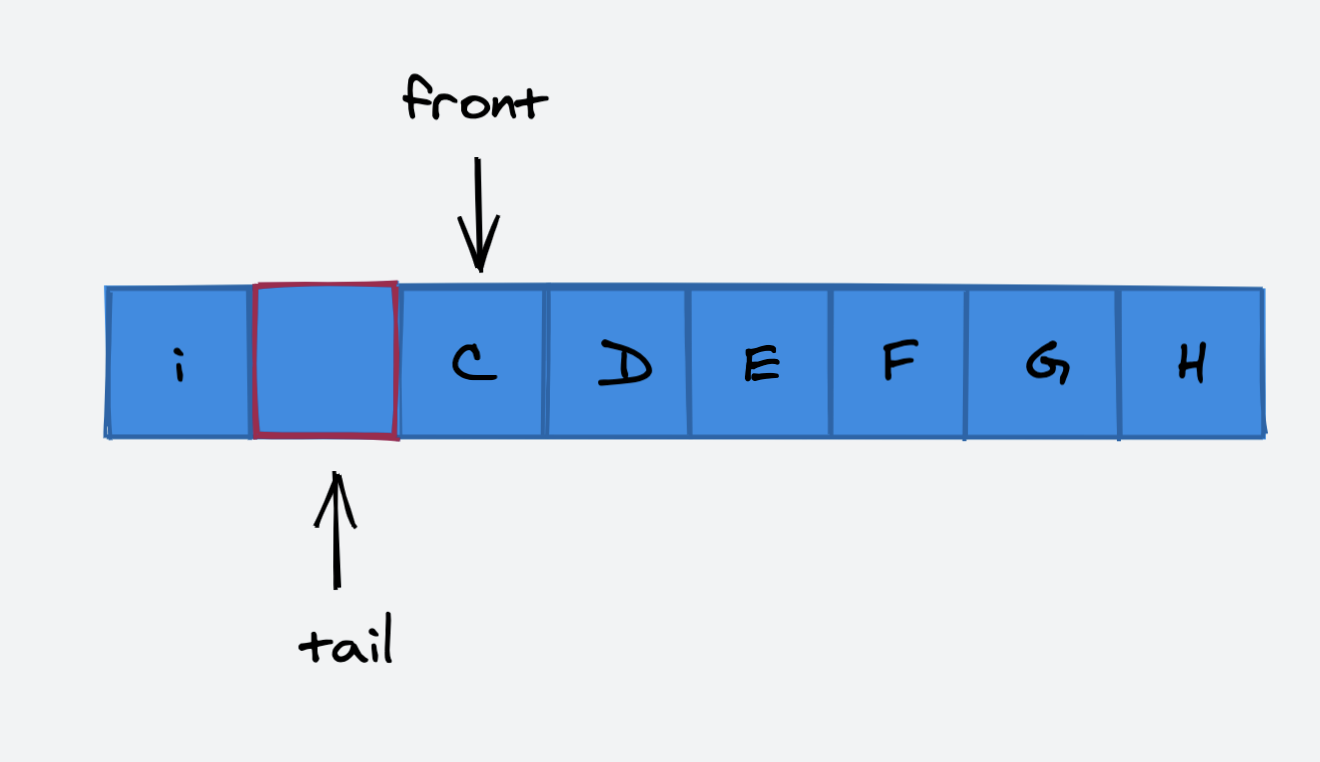
此时,队列为满。如果再向队列中添加元素,那么就要进行扩容了。扩容的实现也略微不同,我们需要保证维护队列的顺序,所以需要将 front 指针到 tail 指针之间的元素依次复制到新的数组中。
通过我们将数组队列升级为循环队列后,dequeue 也变成了一个时间复杂度为 O(1) 的操作。
三:队列与循环队列的比较
那么,没有经过优化的队列与循环队列的性能差异有多大呢?
我们来测试一下:
public class ArrayQueueAndLoopQueuePerformanceTest {/*** @param queue 测试的队列* @param opCount 测试数据的数量级* @return 运行 testQueue 方法所需要的时间*/private static double testQueue(Queue<Integer> queue, int opCount) {long startTime = System.nanoTime();Random random = new Random();for (int i = 0; i < opCount; i++) {queue.enqueue(random.nextInt(Integer.MAX_VALUE));}for (int i = 0; i < opCount; i++) {queue.dequeue();}long endTime = System.nanoTime();return (endTime - startTime) / 1000000000.0;}@Testvoid performanceTest() {int opCount = 100000;ArrayQueue<Integer> arrayQueue = new ArrayQueue<>();LoopQueue<Integer> loopQueue = new LoopQueue<>();double time1 = testQueue(arrayQueue, opCount);System.out.println("ArrayQueue time : " + time1 + " s");double time2 = testQueue(loopQueue, opCount);System.out.println("LoopQueue time : " + time2 + " s");}}
运行 performanceTest 测试方法,程序输出的结果如下:
ArrayQueue time : 3.001555033 sLoopQueue time : 0.010435612 s
在 JDK 1.8 的测试环境下,我们将十万条数据依次进队,然后全部出队,ArrayQueue 需要 3 秒多的时间,而 LoopQueue 仅仅需要 0.01 秒就可以完成,二者的性能差异是显而易见的,如果数据的量级达到百万,千万,这种差异会变得更加明显。
而造成这种性能差异的主要原因就在于,ArrayQueue 的 dequeue 是一个 O(N) 级别的操作,而 LoopQueue 的 dequeue 则是一个 O(1) 级别的操作。通过这个测试案例,我们也可以体会到,时间复杂度从 O(N) 到 O(1) 会带来巨大的性能提升。

若有收获,就点个赞吧
0 人点赞
