概览
目前已知的最佳实践中,最适用的方案有以下两种:
- logstash
- elasticsearch-dump
| 迁移方案 | 适用场景 | 使用限制 |
|---|---|---|
| Logstash | + 迁移全量数据的场景。 + 迁移满足某些查询需求的场景。 + 跨账号、跨地域的阿里云Elasticsearch间数据迁移的场景。 |
+ 源Elasticsearch、Logstash和目标Elasticsearch实例版本需满足兼容性要求 |
| elasticsearch-dump工具 | 数据量较小,索引数量不多的迁移场景。 | 源Elasticsearch集群、目标Elasticsearch集群、安装elasticsearch-dump工具的服务器的网络要互通。 |
场景一 Logstash
迁移性能
迁移数据读取采用query+sort,使用scroll导出数据;写入时使用_bulk API批量导入。性能数据受限于网络带宽、原集群读取数据速度、目标集群导入能力和Logstash的处理能力。如果用户需要快速导入可以水平扩展Logstash的数量,增加并发量。但是会使原集群承担较大查询压力,有影响业务正常的使用风险。工作原理
Logstash分为三个部分input 、filter、ouput
- input处理接收数据,数据可以来源ES,日志文件,kafka等通道.
- filter对数据进行过滤,清洗。
- ouput输出数据到目标设备,可以输出到ES,kafka,文件等。
迁移流程
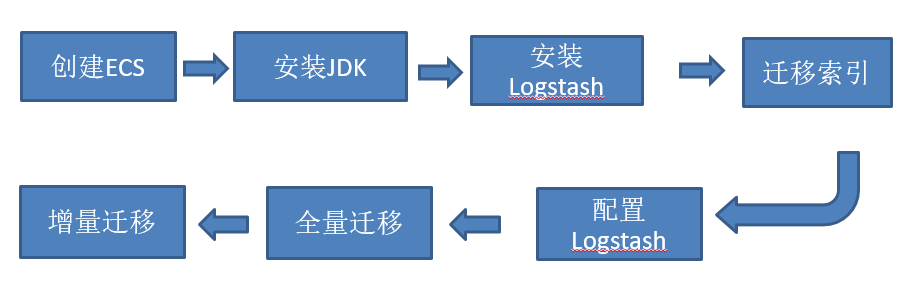
迁移方案
创建阿里云logstash实例:
创建并运行管道任务
等到创建的Logstash实例状态变为正常后,您可以创建并运行管道任务同步数据。
input {elasticsearch {hosts => ["http://es-cn-0pp1f1y5g000h****.elasticsearch.aliyuncs.com:9200"]user => "elastic"password => "your_password"index => "*,-.monitoring*,-.security*,-.kibana*"docinfo => true}}filter {}output {elasticsearch {hosts => ["http://es-cn-mp91cbxsm000c****.elasticsearch.aliyuncs.com:9200"]user => "elastic"password => "your_password"index => "%{[@metadata][_index]}"document_type => "%{[@metadata][_type]}"document_id => "%{[@metadata][_id]}"}file_extend {path => "/ssd/1/ls-cn-v0h1kzca****/logstash/logs/debug/test"}}
| 参数 | 说明 |
|---|---|
| hosts | 阿里云Elasticsearch服务的访问地址。input中为http://<源实例ID>.elasticsearch.aliyuncs.com:9200;output中为http://<目标实例ID>.elasticsearch.aliyuncs.com:9200。 |
| user | 访问阿里云Elasticsearch服务的用户名,默认为elastic。 |
| password | 对应用户的密码。elastic用户的密码在创建实例时设定 。 |
| ndex | 指定同步索引名。设置为,-.monitoring,-.security,-.kibana,表示同步除了.开头的系统索引外的所有索引。%{[@metadata][_index]},表示匹配元数据中的index,即同步后索引的名称和源索引名称相同。 |
| docinfo | 设置为true,将会提取Elasticsearch文档的元信息,例如index、type和id。 |
| document_type | 指定同步后索引的类型。设置为%{[@metadata][_type]},表示匹配元数据中的type,即同步后索引的类型和源索引类型相同。 |
| document_id | 指定同步后文档的ID。设置为%{[@metadata][_id]},表示匹配元数据中的id,即同步后文档的ID和源文档ID相同。 |
| file_extend | 日志的输出路径。建议您配置该参数,配置后,可直接在控制台上查看输出结果。如果未配置,需要去目标端确认输出结果,再返回控制台修改,这样会耗费大量的时间和人力。 |
查看数据同步结果
登录Kibana控制台。点击Dev Tools。在Console中,执行如下命令查看数据同步结果
GET /my_index/_search{"query": {"match_all": {}}}
预期结果如下

场景二 elasticsearch-dump
原理
elasticsearch-dump是一个开源的Elasticsearch数据迁移工具。详情见官网https://github.com/elasticsearch-dump/elasticsearch-dump ### 适用场景 elasticsearch-dump工具适用于数据量较小,索引数量不多的迁移场景。安装
elasticsearch-dump 使用 node.js 开发,可使用 npm 包管理工具直接安装:主要参数说明
npm install elasticdump -g
--input: 源地址,可为 ES 集群 URL、文件或 stdin,可指定索引,格式为:{protocol}://{host}:{port}/{index}--input-index: 源 ES 集群中的索引--output: 目标地址,可为 ES 集群地址 URL、文件或 stdout,可指定索引,格式为:{protocol}://{host}:{port}/{index}--output-index: 目标 ES 集群的索引--type: 迁移类型,默认为 data,表明只迁移数据,可选 settings, analyzer, data, mapping, alias
添加reindex鉴权:
elasticsearch-dump --input=http://192.168.1.2:9200/my_index --output=http://user:password@192.168.1.2:9200/my_index --type=data
迁移单个索引
#第一条命令先将索引的 settings 先迁移,如果直接迁移 mapping 或者 data 将失去原有集群中索引的配置信息如分片数量和副本数量等,当然也可以直接在目标集群中将索引创建完毕后再同步 mapping 与 data。elasticdump --input=http://172.16.0.39:9200/companydatabase --output=http://172.16.0.20:9200/companydatabase --type=settingselasticdump --input=http://172.16.0.39:9200/companydatabase --output=http://172.16.0.20:9200/companydatabase --type=mappingelasticdump --input=http://172.16.0.39:9200/companydatabase --output=http://172.16.0.20:9200/companydatabase --type=data
迁移所有索引
#此操作并不能迁移索引的配置,例如分片数量和副本数量,必须对每个索引单独进行配置的迁移,或者直接在目标集群中将索引创建完毕后再迁移数据。elasticdump --input=http://172.16.0.39:9200 --output=http://172.16.0.20:9200
总结
- elasticsearch-dump 和 logstash 做跨集群数据迁移时,都要求用于执行迁移任务的机器可以同时访问到两个集群,因为网络无法连通的情况下就无法实现迁移。而使用 snapshot 的方式则没有这个限制,因为 snapshot 方式是完全离线的。因此 elasticsearch-dump 和 logstash 迁移方式更适合于源 ES 集群和目标 ES 集群处于同一网络的情况下进行迁移。而需要跨云厂商的迁移,可以选择使用 snapshot 的方式进行迁移,例如从阿里云 ES 集群迁移至腾讯云 ES 集群,也可以通过打通网络实现集群互通,但是成本较高。
- elasticsearch-dump 工具和 MySQL 数据库用于做数据备份的工具 mysqldump 类似,都是逻辑备份,需要将数据一条一条导出后再执行导入,所以适合数据量小的场景下进行迁移。
- snapshot 的方式适合数据量大的场景下进行迁移。

若有收获,就点个赞吧
0 人点赞
