数据结构
1、列表
- 常用操作
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']# 返回列表中元素 x 出现的次数。fruits.count('apple')# 在列表末尾添加一个元素,相当于 a[len(a):] = [x]list.append(x)# 用可迭代对象的元素扩展列表。相当于 a[len(a):] = iterablelist.extend(iterable)# 在指定位置插入元素。第一个参数是插入元素的索引,因此,a.insert(0, x) 在列表开头插入元素, a.insert(len(a), x) 等同于 a.append(x)list.insert(i, x)# 从列表中删除第一个值为 x 的元素。未找到指定元素时,触发 ValueError 异常。list.remove(x)# 删除列表中指定位置的元素,并返回被删除的元素。未指定位置时,a.pop() 删除并返回列表的最后一个元素。list.pop([i])# 删除列表里的所有元素,相当于 del a[:]list.clear()# 返回列表中第一个值为 x 的元素的零基索引。未找到指定元素时,触发 ValueError 异常。list.index(x[, start[, end]])# 就地排序列表中的元素list.sort(*, key=None, reverse=False)# sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。# reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。sorted(iterable, key=None, reverse=False)# 反转列表中的元素list.reverse()# 返回列表的浅拷贝,相当于 a[:]list.copy()
insert、remove、sort 等方法只修改列表,不输出返回值——返回的默认值为 None 。
del 语句按索引,而不是值从列表中移除元素。与返回值的 pop() 方法不同, del 语句也可以从列表中移除切片,或清空整个列表(之前是将空列表赋值给切片)。 例如:
a = [-1, 1, 66.25, 333, 333, 1234.5]
# 删除第一个元素
del a[0]
[1, 66.25, 333, 333, 1234.5]
# 删除索引为2、3的元素
del a[2:4]
# 清空列表
del a[:]
# 删除整个变量
del a
- 列表实现堆栈
使用列表方法实现堆栈非常容易,最后插入的最先取出(“后进先出”)。把元素添加到堆栈的顶端,使用 append() 。从堆栈顶部取出元素,使用 pop() ,不用指定索引。例如:
stack = [3, 4, 5]
# 在末尾处插入新元素
stack.append(6)
stack.append(7)
# 删除末尾元素
stack.pop()
- 列表实现队列
最先加入的元素,最先取出(“先进先出”);然而,列表作为队列的效率很低。因为,在列表末尾添加和删除元素非常快,但在列表开头插入或移除元素却很慢(因为所有其他元素都必须移动一位)。
实现队列最好用 collections.deque,可以快速从两端添加或删除元素。例如:
from collections import deque
queue = deque(["Eric", "John", "Michael"])
# 后进
queue.append("Terry")
# 先进先出
queue.popleft()
- 列表推导式
常用于对序列或可迭代对象中的每个元素应用某种操作,用生成的结果创建新的列表;或用满足特定条件的元素创建子序列。
squares = []
for x in range(10):
squares.append(x**2)
squares
# 输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 更好的方式无副作用
squares = list(map(lambda x: x**2, range(10)))
# 等价于
squares = [x**2 for x in range(10)]
列表推导式的方括号内包含以下内容:一个表达式,后面为一个 for 子句,然后,是零个或多个 for 或 if 子句。结果是由表达式依据 for 和 if 子句求值计算而得出一个新列表。 举例来说,以下列表推导式将两个列表中不相等的元素组合起来:
[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
# 等价于
combs = []
for x in [1,2,3]:
for y in [3,1,4]:
if x != y:
combs.append((x, y))
# 结果:[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
列表推导式可以使用复杂的表达式和嵌套函数:
from math import pi
[str(round(pi, i)) for i in range(1, 6)]
# 输出结果:['3.1', '3.14', '3.142', '3.1416', '3.14159']
嵌套的列表推导式
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 下面的列表推导式可以转置行列:
[[row[i] for row in matrix] for i in range(4)]
# 造价于
transposed = []
for i in range(4):
transposed.append([row[i] for row in matrix])
# 实际应用中,最好用内置函数替代复杂的流程语句。此时,zip() 函数更好用:
# zip:创建一个聚合了来自每个可迭代对象中的元素的迭代器。
list(zip(*matrix))
一般来说,在循环中修改列表的内容时,创建新列表比较简单,且安全:
import math
raw_data = [56.2, float('NaN'), 51.7, 55.3, 52.5, float('NaN'), 47.8]
filtered_data = []
for value in raw_data:
if not math.isnan(value):
filtered_data.append(value)
2、元组和序列
- 输入时,圆括号可有可无,不过经常是必须的。
- 输出时,元组都要由圆括号标注,这样才能正确地解释嵌套元组。
- 不允许为元组中的单个元素赋值。
- 元组是 immutable (不可变的),一般可包含异质元素序列。
- 列表是 mutable (可变的),列表元素一般为同质类型,可迭代访问。
在序列中循环时,用 enumerate() 函数可以同时取出位置索引和对应的值:# 元组打包 t = 12345, 54321, 'hello!' # 第一个元素 12345 t[0] # 输出元组 t u = t,(1, 2, 3, 4, 5) # 嵌套后的元组如下: ((12345, 54321, 'hello!'), (1, 2, 3, 4, 5)) # 元组逆操作,序列解包 x, y, z = t
同时循环两个或多个序列时,用 zip() 函数可以将其内的元素一一匹配:for i, v in enumerate(['tic', 'tac', 'toe']): print(i, v)
逆向循环序列时,先正向定位序列,然后调用 reversed() 函数:questions = ['name', 'quest', 'favorite color'] answers = ['lancelot', 'the holy grail', 'blue'] for q, a in zip(questions, answers): print('What is your {0}? It is {1}.'.format(q, a))
按指定顺序循环序列,可以用 sorted() 函数,在不改动原序列的基础上,返回一个重新的序列:for i in reversed(range(1, 10, 2)): print(i)
使用 set() 去除序列中的重复元素。使用 sorted() 加 set() 则按排序后的顺序,循环遍历序列中的唯一元素:basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana'] for i in sorted(basket): print(i)basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana'] for f in sorted(set(basket)): print(f)3、集合
集合是由不重复元素组成的无序容器。基本用法包括成员检测、消除重复元素。集合对象支持合集、交集、差集、对称差分等数学运算。创建集合用花括号或 set() 函数。注意,创建空集合只能用 set(),不能用 {},{} 创建的是空字典
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket)
'orange' in basket
a = set('abracadabra')
b = set('alacazam')
# a结果为:{'a', 'r', 'b', 'c', 'd'}
a - b # 在a但不在b里
# 结果为 {'r', 'd', 'b'}
# 或的关系,并集
a | b
# and的关系,同时存在a和b
a & b
# 分别在a和b单独存在
a ^ b
集合也支持推导式:
a = {x for x in 'abracadabra' if x not in 'abc'}
4、字典
与以连续整数为索引的序列不同,字典以 关键字 为索引,关键字通常是字符串或数字,也可以是其他任意不可变类型。只包含字符串、数字、元组的元组,也可以用作关键字。但如果元组直接或间接地包含了可变对象,就不能用作关键字。列表不能当关键字,因为列表可以用索引、切片、append() 、extend() 等方法修改。
把字典理解为 键值对 的集合,但字典的键必须是唯一的。花括号 {} 用于创建空字典。
字典的主要用途是通过关键字存储、提取值。用 del 可以删除键值对。用已存在的关键字存储值,与该关键字关联的旧值会被取代。通过不存在的键提取值,则会报错。
对字典执行 list(d) 操作,返回该字典中所有键的列表,按插入次序排列(如需排序,请使用 sorted(d))。检查字典里是否存在某个键,使用关键字 in。
tel = {'jack': 4098, 'sape': 4139}
# 插入键值对
tel['guido'] = 4127
# 删除键值对
del tel['sape']
# 返回字典所有键
list(tel)
# 存在
'guido' in tel
# 不存在
'jack' not in tel
其他创建字典的方法
dict() 构造函数可以直接用键值对序列创建字典:
dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
# 输出结果:{'sape': 4139, 'guido': 4127, 'jack': 4098}
# 字典推导式可以用任意键值表达式创建字典:
{x: x**2 for x in (2, 4, 6)}
# 关键字是比较简单的字符串时,直接用关键字参数指定键值对更便捷:
dict(sape=4139, guido=4127, jack=4098)
在字典中循环时,用 items() 方法可同时取出键和对应的值:
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)
数据格式处理
json
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
| json.dump | 主要用来将python对象写入json文件 |
| json.load | 加载json格式文件,返回python对象 |
- dumps(obj, , skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, *kw)- loads(s, , cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, *kw)
import json
json_str = json.dumps(data) # 编码
# 将数组编码为 JSON 格式数据
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data1 = json.dumps(data) # 编码
print(data1)
#使用参数让 JSON 数据格式化输出
data2 = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))
print(data2)
data = json.loads(json_str) # 解码
# 解码 JSON 对象
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
- dump(obj, fp, , skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, *kw)- load(fp, , cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, *kw)
# json.dump主要用来将python对象写入json文件
with open('demo.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False)
# json.load加载json格式文件,返回python对象
with open('demo.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data, type(data))
正则表达式
1、常用功能
# findall 查找所有. 返回list
lst = re.findall("m", "mai le fo len, mai ni
mei!")
print(lst) # ['m', 'm', 'm']
lst = re.findall(r"\d+", "5点之前. 你要给我5000
万")
print(lst) # ['5', '5000']
# search 会进⾏匹配. 但是如果匹配到了第⼀个结果. 就会返回这个结果. 如果匹配不上search返回的则是None
ret = re.search(r'\d', '5点之前. 你要给我5000万').group()
print(ret) # 5
# match 只能从字符串的开头进⾏匹配
ret = re.match('a', 'abc').group()
print(ret) # a
# finditer, 和findall差不多. 只不过这时返回的是迭代器(重点)
it = re.finditer("m", "mai le fo len, mai nimei!")
for el in it:
print(el.group()) # 依然需要分组
# compile() 可以将⼀个⻓⻓的正则进⾏预加载. ⽅便后⾯的使⽤
obj = re.compile(r'\d{3}') # 将正则表达式编译成为⼀个正则表达式对象, 规则要匹配的是3个数字
ret = obj.search('abc123eeee') # 正则表达式对象调⽤search, 参数为待匹配的字符串
print(ret.group()) # 结果: 123
2、实战案例
s = '姓名:张三;性别:男;电话:138123456789'
m = re.search('姓名[::](\w+).*?电话[::](\d{11})', s) # (?P<name>exp)
if m:
name = m.group(1)
phone = m.group(2)
print(f'name:{name}, phone:{phone}')
# 结果:name:张三, phone:13812345678
s = '''
<name>张三</name>
<age>30</age>
<phone>138123456789</phone>
'''
pattern = r'<(?P<name>.*?)>(.*?)</(?P=name)>'
It = re.findall(pattern, s)
print(It)
# 结果:[('name', '张三'), ('age', '30'), ('phone', '138123456789')]
s = """
<div class='⻄游记'><span id='10010'>中国联通</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>\w+)</span>", re.S)
result = obj.search(s)
print(result.group()) # 结果: <spanid='10010'>中国联通</span>
print(result.group("id")) # 结果: 10010 # 获取id组的内容
print(result.group("name")) # 结果: 中国联通 获取name组的内容
3、常用字符
| . | 匹配除换行符以外的任意字符 |
|---|---|
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开始 |
| & | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| […] | 匹配字符组中的字符 |
| [^…] | 匹配除了字符组中字符的所有字符 |
| * | 重复零或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| .* | 贪婪匹配 |
| .*? | 惰性匹配 |
字符串格式化
"""
% 格式化
str.format()格式化
f-string格式化
format()
"""
# f-string格式化
name = "Addis"
age = 25
print("{} is {}".format(name, age))
print(f"{name} is {age}")
# % 格式化
info = "the name is %s \nthe age is %s" % (name, age)
print(info)
print("我是%s,今年%d岁" % ("王暖暖", 18))
print("我叫%(name)s, 今年%(age)d岁。" % {"name": "Addis", "age": 18})
# str.format()格式化
info_1 = "the name is {name_} \nthe age is {age_}".format(name_=name, age_=age)
print(info_1)
info_2 = "the name is {0} \nthe age is {1}".format(name, age)
print(info_2)
info_3 = "the name is {} \nthe age is {}".format(name, age)
print(info_3)
info_4 = """the name is {name_} \nthe age is {age_}""".format(name_=name, age_=age)
print(info_4)
# 序列号
# format(x, formatter) x为需要格式化的数据,formatter为格式化表达式,不需要指定{}。
nums = [1, 2, 3]
serial_nums = [format(x, "0>8") for x in nums]
print(serial_nums)
print(",千位分隔符:{0:,}".format(31453453541.82))
函数
定义 函数使用关键字 def,后跟函数名与括号内的形参列表。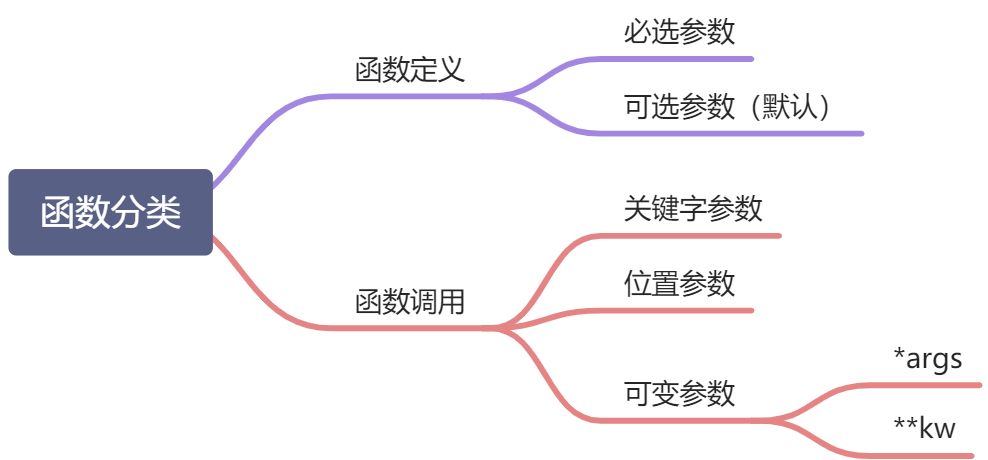
注意事项:
1、在定义时,必选参数一定要在可选参数的前面,不然运行时会报错。
2、在定义时,可变位置参数一定要在可变关键字参数前面,不然运行时也会报错。
3、可变位置参数可以放在必选参数前面,但是在调用时,必选参数必须要指定参数名来传入,否则会报错。
4、可变关键字参数一定得放在最后。
5、函数参数传递的是实际对象的内存地址。如果参数是引用类型的数据类型(列表、字典等),在函数内部修改后,就算没有把修改后的值返回回去,外面的值其实也已经发生了变化。
# 必选参数 a
def demo_func(a):
print(a)
demo_func(10)
# b 是可选参数(默认参数),可以指定也可以不指定,不指定的话,默认为10
def demo_func(b=10):
print(b)
demo_func(20)
# name 和 age 都是必选参数,在调用指定参数时,如果不使用关键字参数方式传参,需要注意顺序
def profile(name, age):
return f"我的名字叫{name},今年{age}岁了"
print(profile("iswbm", 27))
# 使用关键字参数方式传参
print(profile(age=27, name="iswbm"))
# args前面有一个 *,这就表明了它是一个可变参数,可以接收任意个数的不指定参数名的参数。
def demo_func(*args):
print(args)
demo_func(10, 20, 30)
# kw 参数和上面的 *args 还多了一个 * ,总共两个 ** ,这个意思是 kw 是一个可变关键字参数,可以接收任意个数的带参数名的参数。
def demo_func(**kw):
print(kw)
demo_func(a=10, b=20, c=30) # {'a': 10, 'b': 20, 'c': 30}
# 必选参数,可选参数,不指定参数名的参数,可变关键字参数
def demo_func(arg1, arg2=10, *args, **kw):
print("arg1: ", arg1)
print("arg2: ", arg2)
print("args: ", args)
print("kw: ", kw)
demo_func(1,12, 100, 200, d=1000, e=2000)
Lambda表达式
lambda 关键字用于创建小巧的匿名函数。lambda a, b: a+b 函数返回两个参数的和。Lambda 函数可用于任何需要函数对象的地方。
def make_incrementor(n):
return lambda x: x + n
f = make_incrementor(42)
f(0) # 42
f(1) # 41
x = lambda a : a + 10
print(x(5)) # 17
用例
def return_sum(func, lst):
result = 0
for i in lst:
# if val satisfies func
if func(i):
result = result + i
return result
lst = [11, 14, 21, 56, 78, 45, 29, 28]
x = lambda a: a % 2 == 0
y = lambda a: a % 2 != 0
z = lambda a: a % 3 == 0
print(return_sum(x, lst))
print(return_sum(y, lst))
print(return_sum(z, lst))
# 将数组元素进行平方运算
arr = [2, 4, 6, 8]
arr = list(map(lambda x: x * x, arr))
print(arr)
# 有一个包含名称、地址等详细信息的字典列表,目标是生成一个包含所有名称的新列表。
students = [
{"name": "John Doe",
"father name": "Robert Doe",
"Address": "123 Hall street"
},
{
"name": "Rahul Garg",
"father name": "Kamal Garg",
"Address": "3-Upper-Street corner"
},
{
"name": "Angela Steven",
"father name": "Jabob steven",
"Address": "Unknown"
}
]
print(list(map(lambda student: student['name'], students)))
# Filter函数,在函数中设定过滤条件,迭代元素,保留返回值为True 的元素。Map 函数对每个元素进行操作,而 filter 函数仅输出满足特定要求的元素。
fruits = ['mango', 'apple', 'orange', 'cherry', 'grapes']
print(list(filter(lambda fruit: 'g' in fruit, fruits)))
print(" ======= 列表推导式 ========")
arr = [2, 4, 6, 8]
arr = [i ** 2 for i in arr]
print(arr)
fruit_result = [fruit for fruit in fruits if 'g' in fruit]
print(fruit_result)
print(" ======= 字典推导式 ========")
lst = [2, 4, 6, 8]
D1 = {item: item ** 2 for item in lst}
print(D1)
# 创建一个只包含奇数元素的字典
arr = [1, 2, 3, 4, 5, 6, 7, 8]
D2 = {item: item ** 2 for item in arr if item % 2 != 0}
print(D2)
dl = [{1: 'life', 2: 'is'},
{1: 'short', 3: 'i'},
{1: 'use', 4: 'python'}]
[k for k in dl[0] if all(map(lambda d: k in d, dl[1:]))]

若有收获,就点个赞吧
0 人点赞
