示例环境:Mysql 8.0(默认)、PostgreSQL 13,二者在操作上会存在些许差异,文中会分别说明。
一、查
SELECT 查询语句
SELECT DISTINCT <select_list>FROM <left_table><join_type> JOIN <right_table>ON <join_condition>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>ORDER BY <order_by_condition>LIMIT <limit_number>
- from:需要从哪个数据表检索数据
- where:过滤表中数据的条件
- group by:如何将上面过滤出的数据分组
- having:对上面已经分组的数据进行过滤的条件 (对分组后的数据进行统计)
- select:查看结果集中的哪个列,或列的计算结果
-
SQL执行顺序
from——where——group by——having——select——order by

简单查询
-- 合并列查询
SELECT CONCAT(SId,'-',Sname) FROM student
-- 左截取
SELECT LEFT(Sname,1) FROM student
-- 右截取
SELECT RIGHT(Sname,2) FROM student
-- 截取,分别得到 李 2021
SELECT SUBSTRING_INDEX('李-2021','-',1),SUBSTRING_INDEX('李-2021','-',-1)
条件查询
-- 查询年龄小于12的学生
SELECT*FROM student WHERE age < 12;
-- 查询mysql成绩在80到90分之间的学生
SELECT *FROM student wHERE mysql BETWEEN 80 AND 90;
-- or可以无限连用
-- 查询—班或者年龄大于12或者id大于7的学生
SELECT * FROM student wHERE classes = '一班' oR age > 12 oR id > 7;
-- or和and可以涌合使用
-- 查询一班mysql成绩在85以上或者二班hadoop成绩在80分以上的学生
SELECT * FROM student wHERE classes = '一班'AND mysql > 85;
-- 查询班级不是null的,'空字符串也是字符串,不是null
SELECT*FROM student WHERE classes Is NOT NULL;
-- <>这个符合,也代表非,就是不是,并且自带not null
-- 查询name不是'空宁符串的数据
SELECT* FROM student WHERE name <> '';
-- 查询班级不是一班的学生
SELECT *FROM student WHERE classes <>'一班';I
-- 查询姓名以"三"宁结尾的学生
SELECT *FROM student WHERE name LIKE'%三';
-- 三的前面有0到多个字符,意思就是三字结尾
-- 查询姓张的学生,就是以张开头
SELECT *FROM student WHERE name LIKE'张%';
-- 查询姓张的学生,名字是三个字的
SELECT *FROMstudent WHERE name LIKE '张__';
-- 查询某个字段为空的
select * from tyz_isolate_nucleic_acid_site where (id is null or length(id) = 0)
转化查询
-- case 分类转化查询
SELECT (CASE sex
WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '未知' END CASE;
) FROM table_name;
-- Postgresql
SELECT "Sname",(CASE WHEN "Ssex"='男' THEN 1 WHEN "Ssex"= '女' THEN 2 END)
FROM student
-- if条件判断
SELECT name,if(sex <= 1,'正常性别','异常性别') FROM table_name;
-- 用elt
SELECT elt(level,'超级VIP客户','VIP客户','普通客户') AS '客户级别' table_name;
-- 包含中文字符
select * from 表名 where 列名 like '%[吖-座]%'
-- 包含英文字符
select * from 表名 where 列名 like '%[a-z]%'
-- 包含纯数字
select * from 表名 where 列名 like '%[0-9]%'
-- 按条件计数
SELECT DATE_FORMAT(regist_time,'%Y-%m-%d') AS checktime,
count(CASE WHEN person_type = 1 THEN 1 ELSE null END),
count(DISTINCT id_card) FROM zhrc.checkpoint_tourist_info
WHERE regist_time >= '2022-05-15' GROUP BY checktime
mysql 字符串大小写转化函数有两对: lower(), upper() 和 lcase(), ucase():
- 列转行
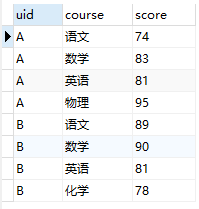
SELECT uid,
sum(if(course='语文', score, NULL)) as `语文`,
sum(if(course='数学', score, NULL)) as `数学`,
sum(if(course='英语', score, NULL)) as `英语`,
sum(if(course='物理', score, NULL)) as `物理`,
sum(if(course='化学', score, NULL)) as `化学`
FROM scoreLong
GROUP BY uid
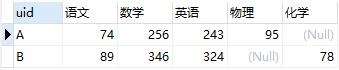
- 行转列 ```sql
SELECT uid, ‘语文’ as course, 语文 as score
FROM scoreWide
WHERE 语文 IS NOT NULL
UNION
SELECT uid, ‘数学’ as course, 数学 as score
FROM scoreWide
WHERE 数学 IS NOT NULL
UNION
SELECT uid, ‘英语’ as course, 英语 as score
FROM scoreWide
WHERE 英语 IS NOT NULL
UNION
SELECT uid, ‘物理’ as course, 物理 as score
FROM scoreWide
WHERE 物理 IS NOT NULL
UNION
SELECT uid, ‘化学’ as course, 化学 as score
FROM scoreWide
WHERE 化学 IS NOT NULL
<a name="Wdrgs"></a>
#### 聚合查询
```sql
-- 计算学生中二班的mysql的分数的总和
SELECT sum (mysql)FROM student WHERE classes = '二班';
-- 一班学生的hadoop的平均成绩
SELECT avg (hadoop)FROM student wHERE classes = '一班';
-- 一班学生的hadoop的第一名
SELECT max(hadoop)FROM student WHERE classes = '一班';
排序查询
| ORDER BY 字段 | 正序(默认) |
|---|---|
| ORDER BY 字段 ASC | 正序 |
| ORDER BY 字段 DESC | 倒序 |
-- 以年龄倒序排列
SELECT *FROM student ORDER BY age DESC;
-- 以年龄正序排列,年龄相同的以mysql的成绩正序排序
SELECT * FROM student ORDER BY age , mysql;
-- 例如,以年龄正序排列,年龄相同的以mysql的成绩倒序排序
SELECT* FROM student WHERE age IS NOT NULL ORDER BY age,mysql DESC;
分页查询
-- 偏移量 = 起始行的行号-第一行行号
SELECT * FROM student LIMIT 3,6;
SELECT * FROM student LIMIT 6,3;
-- 在查询的过程中,可能要使用where条件, limit要放在where条件后面
SELECT *FROM student WHERE age Is NOT NULL LIMIT 6,6;
-- 如果查询中有where,还有排序,先where,然后排序,然后limit
SELECT* FROM student wHERE age Is NOT NULL ORDER BY age LIMIT 6,6;
-- 特殊的limit,如果你是从第一行开始分页,偏移量就是0,如果偏移量=0时,偏移量可以省略#
SELECT*FROM student LIMIT 0,6;SELECT *FROM student LIMIT 6;
分组查询
group by字段[筛选条件having]
-- 查询学生中男女的人数,实际上就是要根据性别分组,在对性别字段去做count聚合查询
SELECT sex, count (sex) FROM student GROUP BY sex;
SELECT sex, count(sex)FROM student WHERE sex is not null GROUP BY sex;
-- 筛选出mysql的最高分在90分以上.的班级
SELECT classes '班级' , count(classes)'学生人数' , max(mysql) 'mysql的最好成绩'FROM student
WHERE classes <> '' GROUP BY classes HAVINGmax(mysql) > 90;
连接查询
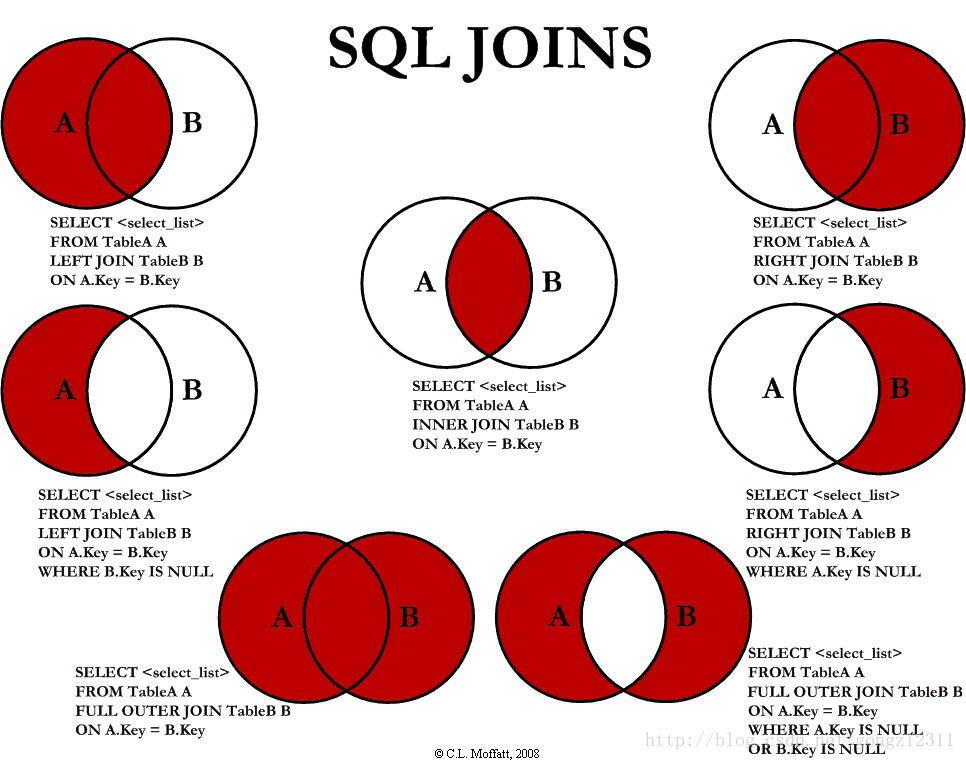
Mysql好像不支持全连接
左连接
SELECT * FROM
(
(SELECT DATE_FORMAT(submit_time,'%Y-%m-%d')AS ymd, count(*) AS 'skbs' from skbs_risk_entry WHERE remark LIKE '%陕西%' GROUP BY ymd ORDER BY ymd) AS t1
FULL JOIN
(SELECT DATE_FORMAT(submit_time,'%Y-%m-%d')AS ymd, count(*) AS 'zdqy' from zdqy_risk_entry WHERE remark LIKE '%陕西%' GROUP BY ymd ORDER BY ymd) AS t2 ON t1.ymd = t2.ymd
)
-- 同一个表多个字段对应
SELECT t1.id,t2.name,t3.name,t4.name,t1.name,t1.number,t1.site
FROM zhrc.`isolate_nucleic_acid_site` as t1
left join zhrc.blade_region t2
on t1.city_code = t2.code
left join zhrc.blade_region t3
on t1.districts_code = t3.code
left join zhrc.blade_region t4
on t1.street_code = t4.code
WHERE 1 = 1 AND t1.sampling_sit_type = 1 AND t1.is_deleted = 0
一张表多字段关联
-- 匹配出多个行政区划信息
SELECT
t1.id,
t2.name AS city,
t3.name AS county,
t4.name AS street,
t1.name,
t1.number,
t1.site
FROM
zhrc.`isolate_nucleic_acid_site` AS t1
LEFT JOIN zhrc.blade_region t2 ON t1.city_code = t2.
CODE LEFT JOIN zhrc.blade_region t3 ON t1.districts_code = t3.
CODE LEFT JOIN zhrc.blade_region t4 ON t1.street_code = t4.CODE
WHERE
AND t1.sampling_sit_type = 1
AND t1.is_deleted = 0
子查询
子查询就是嵌套查询,实际工作中往往会使用多层嵌套来实际需求。
-- 查询员工表顺带查询员工所在的部门
SELECT e.e_name,e.d_id,(SELECT d.d _name FROM dept d WHERE d.id = e.d_id) '部门’FROM
emp e WHERE e.id = l;
二、SQL常用关键字
SELECT 语句
DISTINCT
LIMIT
OFFSET
GROUP BY
ORDER BY
三、增
新建数据库
-- Mysql数据库,设置编码格式为utf-8
CREATE DATABASE `database` CHARACTER SET 'utf8mb4';
-- PostgreSQL数据库,设置编码格式为utf-8
CREATE DATABASE "database"
WITH
OWNER = "postgres"
TEMPLATE = "data_center"
ENCODING = 'UTF8'
;
COMMENT ON DATABASE "database" IS '数据库注释';
新建表
- Mysql
``sql -- Mysql 设置id为自增主键,create_time根据当前时间更新 CREATE TABLEtable_name(idint NOT NULL AUTO_INCREMENT,id_namevarchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '姓名',borth_datedate NULL DEFAULT NULL COMMENT '出生日期',create_timetimestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建日期', PRIMARY KEY (id`) USING BTREE )
DROP TABLE IF EXISTS mytest;
CREATE TABLE mytest (
text varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT ‘’ COMMENT ‘内容’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间’,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间’
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
- PostgreSQL(自增列)
新增表并指定数据类型及字段名注释,`SERIAL`是伪类型,再新增时使用可实现自增id的目的。在查看时该字段类型为Int型。
```sql
-- ----------------------------
-- Table structure for dwd_lawyer_info
-- ----------------------------
DROP TABLE IF EXISTS "public"."dwd_lawyer_info";
CREATE TABLE "public"."dwd_lawyer_info" (
"id" SERIAL PRIMARY KEY,
"id_name" varchar(255) COLLATE "pg_catalog"."default",
"sex" int2,
"status" int2,
"license_num" varchar(50) COLLATE "pg_catalog"."default",
"creat_time" timestamp(6),
"created_by" varchar(20) COLLATE "pg_catalog"."default",
"perform_type" varchar(255) COLLATE "pg_catalog"."default",
"perform_org" varchar(255) COLLATE "pg_catalog"."default",
"pubdate" date
)
;
COMMENT ON COLUMN "public"."dwd_lawyer_info"."id_name" IS '姓名';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."sex" IS '性别';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."status" IS '状态';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."license_num" IS '执业证号';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."creat_time" IS '创建时间';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."created_by" IS '创建人';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."perform_type" IS '执业类别';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."perform_org" IS '执业机构';
COMMENT ON COLUMN "public"."dwd_lawyer_info"."pubdate" IS '执业证颁发时间';
-- 添加表注释
COMMENT ON TABLE "public"."dwd_lawyer_info" IS '律师基本信息';
-- 自增id
-- 创建一个序列
CREATE SEQUENCE 'table_name_id_seq START 10;
-- 字段默认值里设
nextval('table_name_id_seq'::regclass)
在PostgreSQL当中,修改表id字段为主键自增,
1、实现ID自增首先创建一个关联序列,以下sql语句是创建一个序列:
-- 序列名称是dim_org_type_id_seq,起始数为
CREATE SEQUENCE dim_org_type_id_seq START 1;
2、然后在字段默认值里设 nextval('tablename_id_seq'::regclass) 即可。
3、保存字段属性变更。
ALTER TABLE public.menu ALTER COLUMN id SET DEFAULT nextval('tablename_id_seq'::regclass);
把当前最大的id做为当前的id自增起始数
select setval('gtablename_id_seq',(select max(id) from gx_history))
然后在字段默认值里设 nextval(‘dim_org_type_id_seq’::regclass) 即可。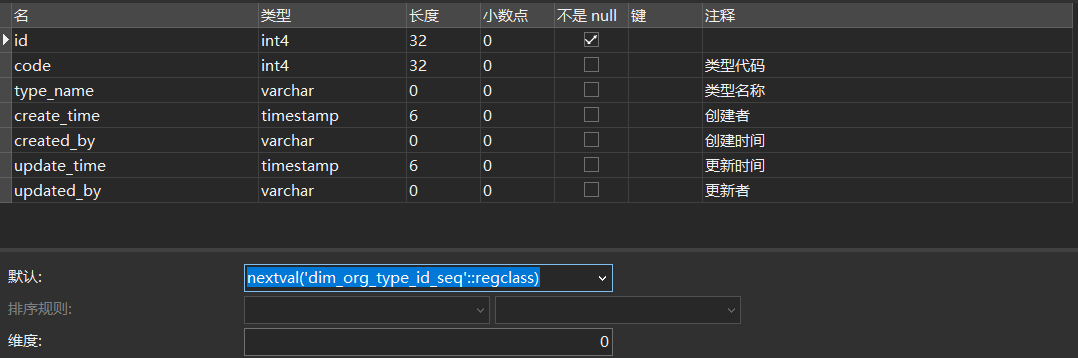
新增列
-- 添加地址列(Mysql 8.0)
ALTER TABLE `data_center`.`org_basic_infor`
ADD COLUMN `province` varchar(30) NULL COMMENT '省/自治区' AFTER `updated_by`,
ADD COLUMN `city` varchar(50) NULL COMMENT '市/自治州' AFTER `province`,
ADD COLUMN `county` varchar(50) NULL COMMENT '县/区' AFTER `city`,
ADD COLUMN `adcode` varchar(20) NULL COMMENT '行政区划代码' AFTER `county`;
-- 表必备字段(Mysql 8.0)
ALTER TABLE `data_center`.`org_basic_infor`
ADD COLUMN `create_time` datetime NULL COMMENT '创建时间' AFTER `tel`,
ADD COLUMN `created_by` varchar(30) NULL COMMENT '创建者' AFTER `create_time`,
ADD COLUMN `update_time` datetime NULL COMMENT '更新时间' AFTER `created_by`,
ADD COLUMN `updated_by` varchar(30) NULL COMMENT '更新者' AFTER `update_time`;
-- 表必备字段(PostgreSQL)
ALTER TABLE "public"."dwd_org_shareholder"
ADD COLUMN "create_time" timestamp(8),
ADD COLUMN "created_by" varchar(20),
ADD COLUMN "update_time" timestamp(8),
ADD COLUMN "updated_by" varchar(20);
COMMENT ON COLUMN "public"."dwd_org_shareholder"."create_time" IS '创建时间';
COMMENT ON COLUMN "public"."dwd_org_shareholder"."created_by" IS '创建人';
COMMENT ON COLUMN "public"."dwd_org_shareholder"."update_time" IS '更新时间';
COMMENT ON COLUMN "public"."dwd_org_shareholder"."updated_by" IS '更新者';
新增/插入数据
INSERT INTO `table_name` VALUES (1, 'addis', '2021-06-19', '2021-06-19 13:37:40');
-- 指定字段插入
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
四、删
删除数据库
DROP DATABASE <数据库名>;
删除表
DROP TABLE table_name ;
清空表(包括自增)且保留结构
-- 当表没有其他关系时
TRUNCATE TABLE table_name;
-- 并且将所有的外键全部删除。清除之后,再次执行保存操作,自增长编号从1开始了。
TRUNCATE table_name RESTART IDENTITY;
-- 当表中有外键时,要用级联方式删所有关联的数据
TRUNCATE TABLE tablename CASCADE;
删除记录
-- 从 MySQL 数据表中删除数据的通用语法
DELETE FROM table_name [WHERE Clause]
五、改
修改表
-- 更改表名
ALTER TABLE dict_organization_type RENAME TO dict_org_type;
-- 更改字段名
ALTER TABLE dict_org_type_classifi RENAME COLUMN classification_first TO classifi_first;
修改字段
-- 更改字段类型(PostgreSQL)
ALTER TABLE dbo.titemtype
ALTER COLUMN ID TYPE INTEGER USING to_number( ID, '9' );
-- 更改字段类型(PostgreSQL)
ALTER TABLE "public"."dict_industry_category"
ALTER COLUMN "category_first" TYPE varchar(20) USING "category_first"::varchar(16),
-- 修改表字段名注释(PostgreSQL)
COMMENT ON COLUMN "public"."gs_nsxydj"."audit_name" IS '审核人';
CURRENT_TIMESTAMP
-- 修改字段顺序(Mysql8.0)
ALTER TABLE `data_center`.`org_basic_infor`
MODIFY COLUMN `adcode` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '行政区划代码' AFTER `reg_status`,
MODIFY COLUMN `province` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '省/自治区' AFTER `adcode`,
MODIFY COLUMN `city` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '市/自治州' AFTER `province`,
MODIFY COLUMN `county` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '县/区' AFTER `city`,
MODIFY COLUMN `address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '住所' AFTER `county`;
修改数据
-- UPDATE 命令修改 MySQL 数据表数据的通用 SQL 语法
UPDATE table_name SET field1=new-value1, field2=new-value2
[WHERE Clause]
-- 去掉指定字段的字符
UPDATE da.成都市域高速公路新冠疫情风险人员信息统计表 SET 现场处置措施 = REPLACE(现场处置措施,'。','')
WHERE 登记日期 = '20220507' AND 现场处置措施 LIKE '%。'
-- 复制字段数据
update isolate_nucleic_acid_site set longitude = lon where longitude is null;
UPDATE dim_hsjc_jigou_code SET is_deleted = IF( is_deleted = 1, 0, 1 );
Table 12.12 String Functions and Operators
| Name | Description |
|---|---|
| ASCII() | Return numeric value of left-most character |
| BIN() | Return a string containing binary representation of a number |
| BIT_LENGTH() | Return length of argument in bits |
| CHAR() | Return the character for each integer passed |
| CHAR_LENGTH() | Return number of characters in argument |
| CHARACTER_LENGTH() | Synonym for CHAR_LENGTH() |
| CONCAT() | Return concatenated string |
| CONCAT_WS() | Return concatenate with separator |
| ELT() | Return string at index number |
| EXPORT_SET() | Return a string such that for every bit set in the value bits, you get an on string and for every unset bit, you get an off string |
| FIELD() | Index (position) of first argument in subsequent arguments |
| FIND_IN_SET() | Index (position) of first argument within second argument |
| FORMAT() | Return a number formatted to specified number of decimal places |
| FROM_BASE64() | Decode base64 encoded string and return result |
| HEX() | Hexadecimal representation of decimal or string value |
| INSERT() | Insert substring at specified position up to specified number of characters |
| INSTR() | Return the index of the first occurrence of substring |
| LCASE() | Synonym for LOWER() |
| LEFT() | Return the leftmost number of characters as specified |
| LENGTH() | Return the length of a string in bytes |
| LIKE | Simple pattern matching |
| LOAD_FILE() | Load the named file |
| LOCATE() | Return the position of the first occurrence of substring |
| LOWER() | Return the argument in lowercase |
| LPAD() | Return the string argument, left-padded with the specified string |
| LTRIM() | Remove leading spaces |
| MAKE_SET() | Return a set of comma-separated strings that have the corresponding bit in bits set |
| MATCH | Perform full-text search |
| MID() | Return a substring starting from the specified position |
| NOT LIKE | Negation of simple pattern matching |
| NOT REGEXP | Negation of REGEXP |
| OCT() | Return a string containing octal representation of a number |
| OCTET_LENGTH() | Synonym for LENGTH() |
| ORD() | Return character code for leftmost character of the argument |
| POSITION() | Synonym for LOCATE() |
| QUOTE() | Escape the argument for use in an SQL statement |
| REGEXP | Whether string matches regular expression |
| REGEXP_INSTR() | Starting index of substring matching regular expression |
| REGEXP_LIKE() | Whether string matches regular expression |
| REGEXP_REPLACE() | Replace substrings matching regular expression |
| REGEXP_SUBSTR() | Return substring matching regular expression |
| REPEAT() | Repeat a string the specified number of times |
| REPLACE() | Replace occurrences of a specified string |
| REVERSE() | Reverse the characters in a string |
| RIGHT() | Return the specified rightmost number of characters |
| RLIKE | Whether string matches regular expression |
| RPAD() | Append string the specified number of times |
| RTRIM() | Remove trailing spaces |
| SOUNDEX() | Return a soundex string |
| SOUNDS LIKE | Compare sounds |
| SPACE() | Return a string of the specified number of spaces |
| STRCMP() | Compare two strings |
| SUBSTR() | Return the substring as specified |
| SUBSTRING() | Return the substring as specified |
| SUBSTRING_INDEX() | Return a substring from a string before the specified number of occurrences of the delimiter |
| TO_BASE64() | Return the argument converted to a base-64 string |
| TRIM() | Remove leading and trailing spaces |
| UCASE() | Synonym for UPPER() |
| UNHEX() | Return a string containing hex representation of a number |
| UPPER() | Convert to uppercase |
| WEIGHT_STRING() | Return the weight string for a string |

若有收获,就点个赞吧
0 人点赞
