需求分析
用户数据是后期营销的很重要的数据 , 电商用户一般门槛较低,注册网站即可加入
有些电商平台的高级用户具有时效性,需要购买 VIP用户卡或一年内消费额达到多少才能成为高级用户
计算指标:
- 新增用户:每日新增用户数
- 活跃用户:每日,每周,每月的活跃用户数
- 用户留存:1日,2日,3日用户留存数、1日,2日,3日用户留存率
指标口径业务逻辑:
- 用户:以设备为判断标准,每个独立设备认为是一个用户。Android系统通常根据IMEI号,IOS系统通常根据OpenUDID 来标识一个独立用户,每部移动设备是一个用户
- 活跃用户:打开应用的用户即为活跃用户,暂不考虑用户的实际使用情况。一台设备每天多次打开计算为一个活跃用户。在自然周内启动过应用的用户为周活跃用户,同理还有月活跃用户
- 用户活跃率:一天内活跃用户数与总用户数的比率是日活跃率;还有周活跃率(自然周)、月活跃率(自然月)
- 新增用户:第一次使用应用的用户,定义为新增用户;卸载再次安装的设备,不会被算作一次新增。新增用户包括日新增用户、周(自然周)新增用户、月(自然月)新增用户
- 留存用户与留存率:某段时间的新增用户,经过一段时间后,仍继续使用应用
- 留存用户;这部分用户占当时新增用户的比例为留存率
已知条件:
- 明确了需求
- 输入:启动日志(OK)、事件日志
- 输出:新增用户、活跃用户、留存用户
- 日志文件、ODS、DWD、DWS、ADS(输出)
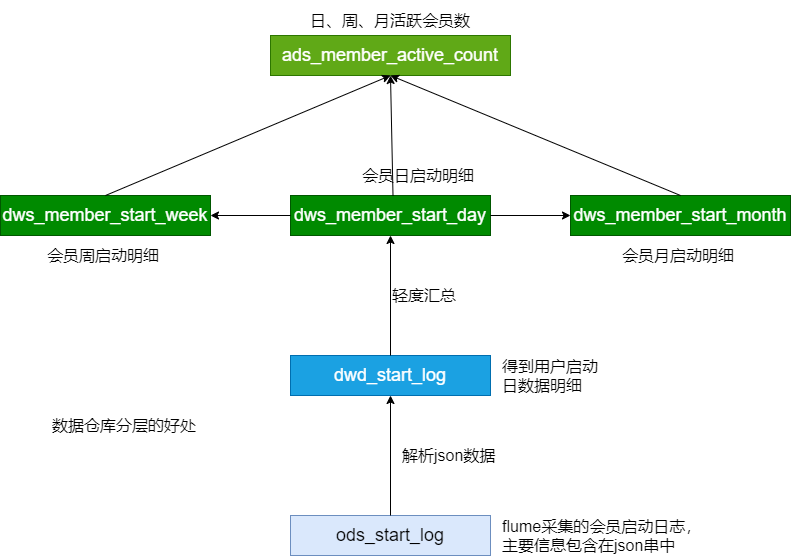
ODS建表和数据加载
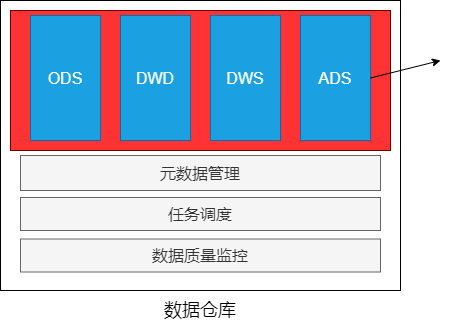
ODS层的数据与源数据的格式基本相同
创建ODS层表
-- 删除用户启动日志drop table if exists ods_start_log;-- 创建用户启动日志表create external table ods_start_log(`str` string comment 'json 数据') comment '用户启动日志信息'partitioned by (`dt` string)location '/user/yx_test/data/logs/start';
加载数据的功能
-- 加载数据
alter table ods_start_log
add partition (dt = '2020-07-21');
删除 : alter table ods.ods_start_log drop partition(dt=’2020-07-21’);
select str,
dt
from ods_start_log
where dt = '2020-07-21';
加载启动日志脚本
vim script/member_active/ods_load_log.sh
#!/bin/bash
APP=yx_mall
hive=/app/hadoop/hive-3.1.2/bin/hive
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的SQL
sql="alter table "$APP".ods_start_log add partition(dt='$do_date');"
$hive -e "$sql"
json 数据处理
数据文件中每行必须是一个完整的 json 串,一个 json串 不能跨越多行
Hive 处理 json 数据总体来说有三个办法:
- 使用内建的函数
get_json_object、json_tuple - 使用自定义的 UDF
- 第三方的 SerDe
内建函数处理
函数介绍
/*
* 返回值:String
* 说明:解析json字符串json_string,返回 path 指定的内容;如输入的json字符串无效,就返回 NUll;函数每次只能返回一个数据项
*/
get_json_object(string json_string, string path)
/*
* 返回值:所有的输入参数、输出参数都是 String
* 说明:参数为一组键k1,k2,和json字符串,返回值的元组。该方法比 get_json_object 高效,所以一次调用中输入多个键
*/
json_tuple(jsonStr, k1, k2, ...)
# 使用 explod 将Hive一行中复杂的 array 或 map 结构拆分成多行
explode
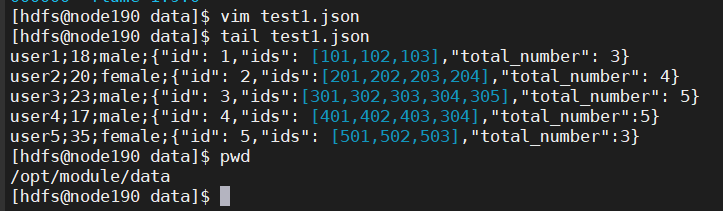
测试数据
vim test1.json
user1;18;male;{"id": 1,"ids": [101,102,103],"total_number": 3}
user2;20;female;{"id": 2,"ids":[201,202,203,204],"total_number": 4}
user3;23;male;{"id": 3,"ids":[301,302,303,304,305],"total_number": 5}
user4;17;male;{"id": 4,"ids": [401,402,403,304],"total_number":5}
user5;35;female;{"id": 5,"ids": [501,502,503],"total_number":3}
创建目录
hdfs dfs -mkdir -p /origin_data/cpucode/test/
存放数据
hdfs dfs -put test1.json /origin_data/cpucode/test/

建表加载数据
建表
create table if not exists jsont1
(
`username` string,
`age` int,
`sex` string,
`json` string
) row format delimited fields terminated by ';';
装载数据
load data inpath '/origin_data/cpucode/test/test1.json'
overwrite into table jsont1;
select username,
age,
sex,
json
from jsont1;
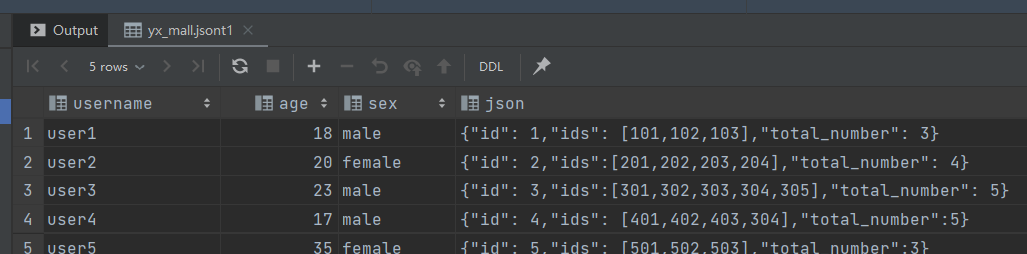
json的处理
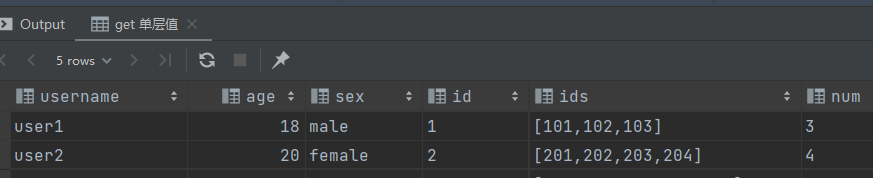
获取单层值
-- get 单层值
select username,
age,
sex,
get_json_object(json, '$.id') id,
get_json_object(json, '$.ids') ids,
get_json_object(json, '$.total_number') num
from jsont1;
获取数组值
-- 获取数组值
select username,
age,
sex,
get_json_object(json, "$.id") id,
get_json_object(json, "$.ids[0]") ids0,
get_json_object(json, "$.ids[1]") ids1,
get_json_object(json, "$.ids[2]") ids2,
get_json_object(json, "$.ids[3]") ids3,
get_json_object(json, '$.total_number') num
from jsont1;

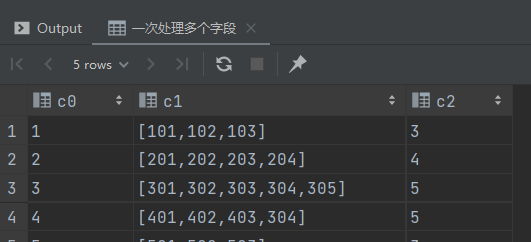
使用 json_tuple 一次处理多个字段
-- 一次处理多个字段
select json_tuple(json, 'id', 'ids', 'total_number')
from jsont1;
错误语法
-- 有语法错误
select username,
age,
sex,
json_tuple(json, 'id', 'ids', 'total_number')
from jsont1;
SemanticException:UDTF’s are not supported outside the SELECT clause, nor nested in expressions
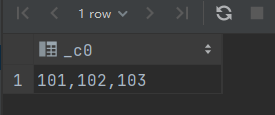
将字符串中的特定符号去掉
select regexp_replace("[101,102,103]", "\\[|\\]", "");
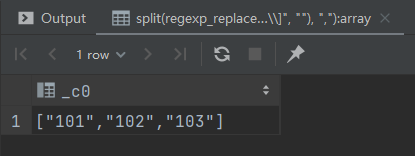
将字符串变为数组
select split(regexp_replace("[101,102,103]", "\\[|\\]", ""), ",");
把数据展开
select username,
age,
sex,
id,
ids,
num
from jsont1 lateral view json_tuple(json, 'id', 'ids', 'total_number') t1
as id, ids, num;

使用 explode + lateral view 将数据展开
with tmp as (
select username,
age,
sex,
id,
ids,
num
from jsont1 lateral view json_tuple(json, 'id', 'ids', 'total_number') t1
as id, ids, num
)
select username,
age,
sex,
id,
ids1,
num
from tmp lateral view explode(split(regexp_replace(ids, "\\[|\\]", ""), ",")) t1 as ids1;
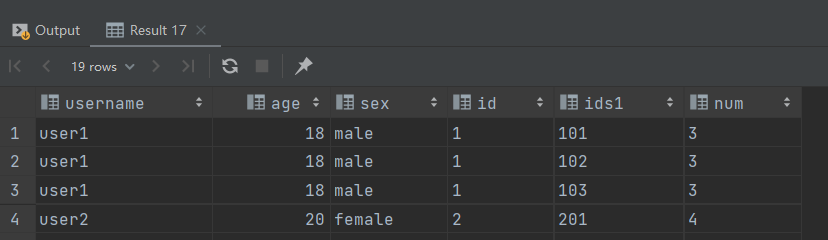
json_tuple 优点 : 一次可以解析多个 json 字段,对嵌套结果的解析操作复杂
UDF处理
自定义 UDF 处理 json 串中的数组
自定义 UDF 函数 :
- 输入:json 串、数组的 key
- 输出:字符串数组
Maven
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.7</version>
<scope>provided</scope>
</dependency>
Java
package com.cpucode.dw.hive.udf;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONException;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Strings;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.junit.Test;
import java.util.ArrayList;
public class ParseJsonArray extends UDF {
public ArrayList<String> evaluate(String jsonStr, String arrKey){
if (Strings.isNullOrEmpty(jsonStr)) {
return null;
}
try{
JSONObject object = JSON.parseObject(jsonStr);
JSONArray jsonArray = object.getJSONArray(arrKey);
ArrayList<String> result = new ArrayList<>();
for (Object o: jsonArray){
result.add(o.toString());
}
return result;
} catch (JSONException e){
return null;
}
}
@Test
public void JunitParseJsonArray(){
String str = "{\"id\": 1,\"ids\":[101,102,103],\"total_number\": 3}";
String key = "ids";
ArrayList<String> evaluate = evaluate(str, key);
System.out.println(JSON.toJSONString(evaluate));
}
}
使用自定义 UDF 函数:
-- 添加开发的jar包(在Hive命令行中)
add jar /opt/software/com.cpucode.dw-1.0-SNAPSHOT-jar-withdependencies.jar;
-- 创建临时函数。指定类名一定要完整的路径,即包名加类名
create temporary function lagou_json_array as "com.cpucode.dw.hive.udf.ParseJsonArray";
-- 执行查询
-- 解析json串中的数组
select username, age, sex, lagou_json_array(json, "ids") ids
from jsont1;
-- 解析json串中的数组,并展开
select username, age, sex, ids1
from jsont1 lateral view explode(lagou_json_array(json, "ids")) t1 as ids1;
-- 解析json串中的id、num
select username, age, sex, id, num
from jsont1
lateral view json_tuple(json, 'id', 'total_number') t1 as id, num;
-- 解析json串中的数组,并展开
select
username, age, sex, ids1, id, num
from jsont1
lateral view explode(lagou_json_array(json, "ids")) t1 as ids1
lateral view json_tuple(json, 'id', 'total_number') t1 as id, num;
SerDe处理
- 序列化 : 对象转换为字节序列的过程
- 反序列化 : 字节序列恢复为对象的过程
对象的序列化主要有两种用途:
- 对象的持久化,即把对象转换成字节序列后保存到文件中
- 对象数据的网络传送
SerDe 是Serializer 和 Deserializer 的简写形式。Hive 使用 Serde 进行行对象的序列与反序列化。最后实现把文件内容映射到 hive 表中的字段数据类型
SerDe 包括 Serialize/Deserilize 两个功能:
- Serialize 把 Hive 使用的 java object 转换成能写入 HDFS 字节序列,或者其他系统能识别的流文件
- Deserilize 把字符串或者二进制流转换成 Hive 能识别的 java object 对象
Read : HDFS files => InputFileFormat =>
Write : Row object => Seriallizer =>
常见:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
Hive 本身自带了几个内置的 SerDe,以及第三方的 SerDe 可供选择
create table t11
(
id string
)
stored as parquet;
create table t12
(
id string
)
stored as ORC;
查看序列化类型 :
desc formatted t11;

desc formatted t12;

- LazySimpleSerDe(默认的SerDe)
- ParquetHiveSerDe
- OrcSerde
对于纯 json 格式的数据,可以用 JsonSerDe 来处理
vim test2.json
{"id": 1,"ids": [101,102,103],"total_number": 3}
{"id": 2,"ids": [201,202,203,204],"total_number": 4}
{"id": 3,"ids": [301,302,303,304,305],"total_number": 5}
{"id": 4,"ids": [401,402,403,304],"total_number": 5}
{"id": 5,"ids": [501,502,503],"total_number": 3}
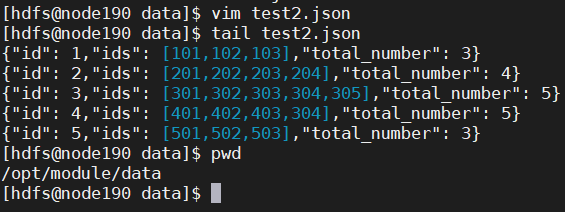
上次数据
hdfs dfs -put test2.json /origin_data/cpucode/test/

创建表
create table jsont2
(
id int,
ids array<string>,
total_number int
) row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
装载数据
load data inpath '/origin_data/cpucode/test/test2.json'
into table jsont2;
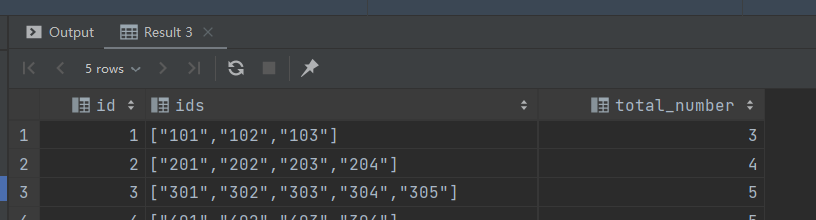
查询数据
select id,
ids,
total_number
from jsont2;
总结
- 简单格式的 json 数据,使用
get_json_object,json_tuple处理 - 对于嵌套数据类型,可以使用 UDF
- 纯 json 串可使用 JsonSerDe 处理更简单
DWD层建表和数据加载
2020-08-02 18:19:32.966 [main] INFO com.lagou.ecommerce.AppStart - {
"app_active": {
"name": "app_active",
"json": {
"entry": "1",
"action": "1",
"error_code": "0"
},
"time": 1596309585861
},
"attr": {
"area": "绍兴",
"uid": "2F10092A10",
"app_v": "1.1.16",
"event_type": "common",
"device_id": "1FB872-9A10010",
"os_type": "3.0",
"channel": "ML",
"language": "chinese",
"brand": "Huawei-2"
}
}
2020-08-02
主要任务:ODS(包含json串) => DWD
json 数据解析,丢弃无用数据(数据清洗),保留有效信息,并将数据展开,形成每日启动明细表
创建 DWD 层表
-- 删除启动日志明细表
drop table if exists dwd_start_log;
-- 创建启动日志明细表
create table dwd_start_log
(
`device_id` string comment '设备id',
`area` string comment '位置',
`uid` string comment '用户id',
`app_v` string,
`event_type` string,
`os_type` string comment '系统版本',
`channel` string comment '渠道',
`language` string comment '语言',
`brand` string comment '型号',
`entry` string,
`action` string,
`error_code` string comment '错误代码'
) comment '启动日志明细表'
partitioned by (`dt` string)
stored as parquet;
表的格式:parquet、分区表
-- 装载数据
set hive.execution.engine = spark;
with tmp as (
select split(str, ' ')[7] line
from ods_start_log
where dt = '2020-07-21'
)
insert
overwrite
table
dwd_start_log
partition
(
dt = '2020-07-21'
)
select get_json_object(line, '$.attr.device_id'),
get_json_object(line, '$.attr.area'),
get_json_object(line, '$.attr.uid'),
get_json_object(line, '$.attr.app_v'),
get_json_object(line, '$.attr.event_type'),
get_json_object(line, '$.attr.os_type'),
get_json_object(line, '$.attr.channel'),
get_json_object(line, '$.attr.language'),
get_json_object(line, '$.attr.brand'),
get_json_object(line, '$.app_active.json.entry'),
get_json_object(line, '$.app_active.json.action'),
get_json_object(line, '$.app_active.json.error_code')
from tmp;
-- 查询数据
select device_id,
area,
uid,
app_v,
event_type,
os_type,
channel,
`language,
brand,
entry,
action,
error_code,
dt
from dwd_start_log
where dt = '2020-07-21'
limit 100;
加载 DWD 层数据脚本
vim script/member_active/dwd_load_start.sh
#!/bin/bash
source /etc/profile
APP=yx_mall
ODS=yx_mall
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的SQL
sql="
with tmp as(
select split(str, ' ')[7] line
from $ODS.ods_start_log
where dt='$do_date'
)
insert overwrite table $APP.dwd_start_log partition(dt='$do_date')
select
get_json_object(line, '$.attr.device_id'),
get_json_object(line, '$.attr.area'),
get_json_object(line, '$.attr.uid'),
get_json_object(line, '$.attr.app_v'),
get_json_object(line, '$.attr.event_type'),
get_json_object(line, '$.attr.os_type'),
get_json_object(line, '$.attr.channel'),
get_json_object(line, '$.attr.language'),
get_json_object(line, '$.attr.brand'),
get_json_object(line, '$.app_active.json.entry'),
get_json_object(line, '$.app_active.json.action'),
get_json_object(line, '$.app_active.json.error_code')
from tmp;"
hive -e "$sql"
日志文件 =》 Flume =》 HDFS =》 ODS =》 DWD
ODS =》 DWD : json数据的解析 , 数据清洗
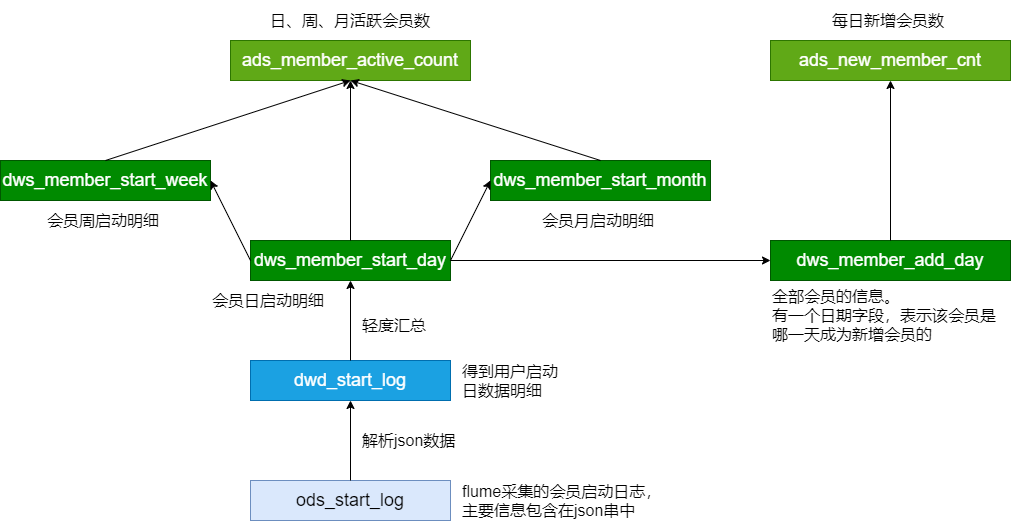
下一步:DWD(用户的每日启动信息明细) => DWS(如何建表,如何加载数据)
活跃用户 => 新增用户 => 用户留存
活跃用户
- 活跃用户:打开应用的用户
- 新增用户:第一次使用应用的用户
- 留存用户:某段时间的新增用户,经过一段时间后,仍继续使用应用
活跃用户指标需求:每日、每周、每月的活跃用户数
- DWD:用户的每日启动信息明细(用户都是活跃用户;某个用户可能会出现多次)
- DWS:每日活跃用户信息(关键)、每周活跃用户信息、每月活跃用户信息
ADS:每日、每周、每月活跃用户数(输出)
周、月 : 自然周、自然月
处理过程:
- 建表(每日、每周、每月活跃用户信息)
- 每日启动明细 => 每日活跃用户
- 每日活跃用户 => 每周活跃用户
- 每日活跃用户 => 每月活跃用户
- 汇总生成 ADS 层的数据
用户日启动 dws 汇总
-- 删除 用户日启动汇总
drop table if exists dws_member_start_day;
-- 创建 用户日启动汇总
create table dws_member_start_day
(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string
) comment '用户日启动汇总'
partitioned by (`dt` string)
stored as parquet;
加载每日活跃会员信息
-- 装载数据
set hive.execution.engine = spark;
insert overwrite table dws_member_start_day
partition (dt = '2020-07-21')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand))
from dwd_start_log
where dt = '2020-07-21'
group by device_id;
-- 查询数据
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
dt
from dws_member_start_day
where dt = '2020-07-21';
用户周启动 dws 汇总
-- 删除每周活跃会员
drop table if exists dws_member_start_week;
-- 创建每周活跃会员
create table dws_member_start_week
(
`device_id` string comment '设备id',
`uid` string comment '用户id',
`app_v` string comment 'app版本',
`os_type` string comment '系统版本',
`language` string comment '语言',
`channel` string comment '渠道',
`area` string comment '地址',
`brand` string comment '品牌',
`week` string comment '周份'
) comment '用户周启动汇总'
partitioned by (`dt` string)
stored as parquet;
装载数据
-- 装载每周活跃会员
set hive.execution.engine = spark;
insert overwrite table dws_member_start_week
partition (dt = '2020-07-21')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_add(next_day('2020-07-21', 'mo'), -7)
from dws_member_start_day
where dt >= date_add(next_day('2020-07-21', 'mo'), -7)
and dt <= '2020-07-21'
group by device_id;
查询数据
-- 查询数据
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
week,
dt
from dws_member_start_week
where dt = '2020-07-21';
用户月启动 dws 汇总
-- 删除 用户月启动汇总
drop table if exists dws_member_start_month;
-- 创建 用户月启动汇总
create table dws_member_start_month
(
`device_id` string comment '设备id',
`uid` string comment '用户id',
`app_v` string comment 'app版本',
`os_type` string comment '系统版本',
`language` string comment '语言',
`channel` string comment '渠道',
`area` string comment '地区',
`brand` string comment '品牌',
`month` string comment '月份'
) comment '用户月启动汇总'
partitioned by (`dt` string)
stored as parquet;
装载数据
-- 装载每月活跃会员
set hive.execution.engine = spark;
insert overwrite table dws_member_start_month
partition (dt = '2020-07-21')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_format('2020-07-21', 'yyyy-MM')
from dws_member_start_day
where dt >= date_format('2020-07-21', 'yyyy-MM-01')
and dt <= '2020-07-21'
group by device_id;
查询数据
-- 查询数据
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
month,
dt
from dws_member_start_month
where dt = '2020-07-21';
加载 DWS 层数据脚本
vim script/member_active/dws_load_member_start.sh
#!/bin/bash
source /etc/profile
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的SQL
# 汇总得到每日活跃用户信息;每日数据汇总得到每周、每月数据
sql="
insert overwrite table dws.dws_member_start_day
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand))
from dwd.dwd_start_log
where dt='$do_date'
group by device_id;
-- 汇总得到每周活跃用户
insert overwrite table dws.dws_member_start_week
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_add(next_day('$do_date', 'mo'), -7)
from dws.dws_member_start_day
where dt >= date_add(next_day('$do_date', 'mo'), -7)
and dt <= '$do_date'
group by device_id;
-- 汇总得到每月活跃用户
insert overwrite table dws.dws_member_start_month
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_format('$do_date', 'yyyy-MM')
from dws.dws_member_start_day
where dt >= date_format('$do_date', 'yyyy-MM-01')
and dt <= '$do_date'
group by device_id;
"
hive -e "$sql"
注意 shell 的
'和''引号ODS => DWD => DWS(每日、每周、每月活跃会员的汇总表)
创建ADS层表
计算当天、当周、当月活跃用户数量
drop table if exists ads_member_active_count;
create table ads_member_active_count(
`day_count` int comment '当日用户数量',
`week_count` int comment '当周用户数量',
`month_count` int comment '当月用户数量'
) comment '活跃用户数'
partitioned by(dt string)
row format delimited fields terminated by ',';
装载数据
union all 数据
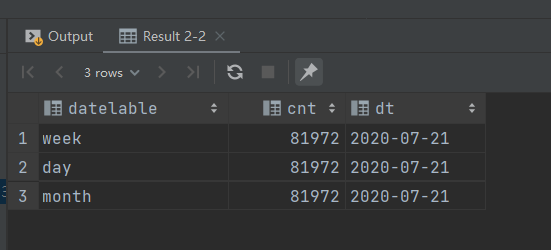
-- union all 连接数据
set hive.execution.engine = spark;
select 'day' datelable,
count(*) cnt,
dt
from dws_member_start_day
where dt = '2020-07-21'
group by dt
union all
select 'week' datelabel,
count(*) cnt,
dt
from dws_member_start_week
where dt = '2020-07-21'
group by dt
union all
select 'month' datelabel,
count(*) cnt,
dt
from dws_member_start_month
where dt = '2020-07-21'
group by dt;
-- 装载数据
set hive.execution.engine = spark;
with tmp as (
select 'day' datelabel,
count(*) cnt,
dt
from dws_member_start_day
where dt = '2020-07-21'
group by dt
union all
select 'week' datelabel,
count(*) cnt,
dt
from dws_member_start_week
where dt = '2020-07-21'
group by dt
union all
select 'month' datelabel,
count(*) cnt,
dt
from dws_member_start_month
where dt = '2020-07-21'
group by dt
)
insert
overwrite
table
ads_member_active_count
partition
(
dt = '2020-07-21'
)
select sum(case when datelabel = 'day' then cnt end) as day_count,
sum(case when datelabel = 'week' then cnt end) as
week_count,
sum(case when datelabel = 'month' then cnt end) as
month_count
from tmp
group by dt;
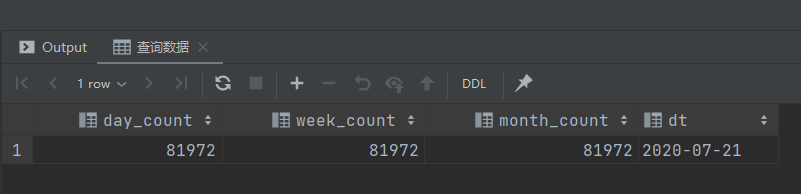
查询数据
-- 查询数据
select day_count,
week_count,
month_count,
dt
from ads_member_active_count
where dt = '2020-07-21';
装载数据
另外一种方法
-- 连接数据
set hive.execution.engine = spark;
select *
from (select dt,
count(*) daycnt
from dws_member_start_day
where dt = '2020-07-21'
group by dt) as `day`
join (
select dt,
count(*) weekcnt
from dws_member_start_week
where dt = '2020-07-21'
group by dt
) as `week`
on `day`.dt = `week`.dt
join(
select dt,
count(*) monthcnt
from dws_member_start_month
where dt = '2020-07-21'
group by dt
) as month
on day.dt = month.dt;

装载数据
-- 装载数据
set hive.execution.engine = spark;
insert overwrite table ads_member_active_count
partition (dt = '2020-07-21')
select daycnt,
weekcnt,
monthcnt
from (select dt,
count(*) daycnt
from dws_member_start_day
where dt = '2020-07-21'
group by dt) as `day`
join (
select dt,
count(*) weekcnt
from dws_member_start_week
where dt = '2020-07-21'
group by dt
) as `week`
on `day`.dt = `week`.dt
join(
select dt,
count(*) monthcnt
from dws_member_start_month
where dt = '2020-07-21'
group by dt
) as month
on day.dt = month.dt;
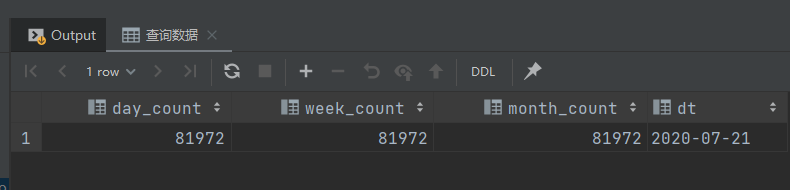
查询数据
-- 查询数据
select day_count,
week_count,
month_count,
dt
from ads_member_active_count
where dt = '2020-07-21';
加载 ADS 层数据脚本
vim script/member_active/ads_load_member_active.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with tmp as(
select 'day' datelabel, count(*) cnt, dt
from dws.dws_member_start_day
where dt='$do_date'
group by dt
union all
select 'week' datelabel, count(*) cnt, dt
from dws.dws_member_start_week
where dt='$do_date'
group by dt
union all
select 'month' datelabel, count(*) cnt, dt
from dws.dws_member_start_month
where dt='$do_date'
group by dt
)
insert overwrite table ads.ads_member_active_count
partition(dt='$do_date')
select sum(case when datelabel='day' then cnt end) as
day_count,
sum(case when datelabel='week' then cnt end) as
week_count,
sum(case when datelabel='month' then cnt end) as
month_count
from tmp
group by dt;
"
hive -e "$sql"
另一种方法 :
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_active_count
partition(dt='$do_date')
select daycnt, weekcnt, monthcnt
from (select dt, count(*) daycnt
from dws.dws_member_start_day
where dt='$do_date'
group by dt
) day join
(select dt, count(*) weekcnt
from dws.dws_member_start_week
where dt='$do_date'
group by dt
) week on day.dt=week.dt
join
(select dt, count(*) monthcnt
from dws.dws_member_start_month
where dt='$do_date'group by dt
) month on day.dt=month.dt;
"
hive -e "$sql"
总结
脚本执行次序 :
ods_load_startlog.sh
dwd_load_startlog.sh
dws_load_member_start.sh
ads_load_member_active.sh
新增用户
留存用户:某段时间的新增用户,经过一段时间后,仍继续使用应用
新增用户:第一次使用应用的用户;卸载再次安装的设备,不算为一次新增
新增用户先计算 => 计算用户留存
需求:每日新增用户数
08-02:
- DWD:会员每日启动明细(95-110);所有会员的信息(1-100)???
- 新增会员:101 - 110
- 新增会员数据 + 旧的所有会员的信息 = 新的所有会员的信息(1 - 110)
08-03:
- DWD:会员每日启动明细(100-120);所有会员的信息(1 - 110)
- 新增会员:111-120
- 新增会员数据 + 旧的所有会员的信息 = 新的所有会员的信息(1-120)
计算步骤:
- 计算新增会员
- 更新所有会员信息
改进后方法:
- 在所有会员信息中增加时间列,表示该会员是哪一天成为新增会员
- 只需要一张表:所有会员的信息(id,dt)
- 将新增会员 插入 所有会员表中
模拟计算新增会员
日启动表
vim t10.txt
4,2020-08-02
5,2020-08-02
6,2020-08-02
7,2020-08-02
8,2020-08-02
9,2020-08-02
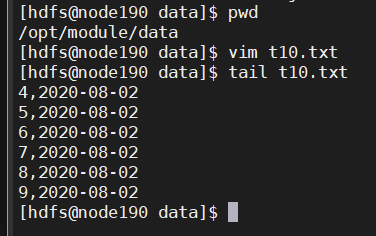
上传数据
hdfs dfs -put t10.txt /origin_data/cpucode/test/

创建表
-- 日启动表
drop table start_day_test;
-- 创建日启动表
create table start_day_test
(
id int,
dt string
)
row format delimited fields terminated by ',';
装载数据
-- 装载数据
load data inpath '/origin_data/cpucode/test/t10.txt'
into table start_day_test;
-- 查询数据
select id,
dt
from start_day_test;
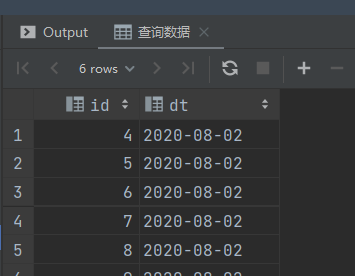
全量数据
vim test11.txt
1,2020-08-01
2,2020-08-01
3,2020-08-01
4,2020-08-01
5,2020-08-01
6,2020-08-01
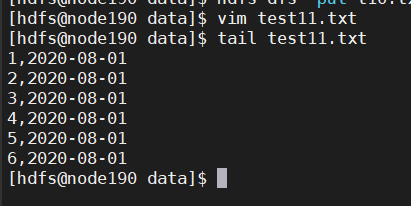
上传数据
hdfs dfs -put test11.txt /origin_data/cpucode/test/

创建表
-- 创建全量数据
drop table start_all_test;
create table start_all_test
(
id int,
dt string
) row format delimited fields terminated by ',';
-- 装载数据
load data inpath '/origin_data/cpucode/test/test11.txt'
into table start_all_test;
-- 查询数据
select id,
dt
from start_all_test;
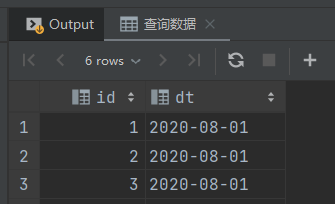
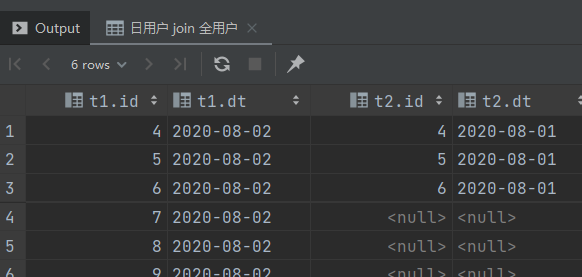
找出 2020-08-02 的新用户
-- 日用户 left join 全用户
select t1.id,
t1.dt,
t2.id,
t2.dt
from start_day_test t1
left join start_all_test t2
on t1.id = t2.id
where t1.dt = '2020-08-02';
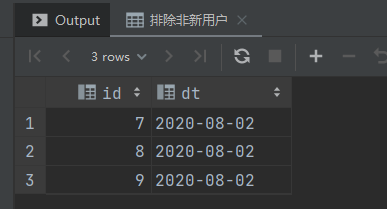
-- 排除非新用户
select t1.id,
t1.dt
from start_day_test t1
left join start_all_test t2
on t1.id = t2.id
where t1.dt = "2020-08-02"
and t2.id is null;
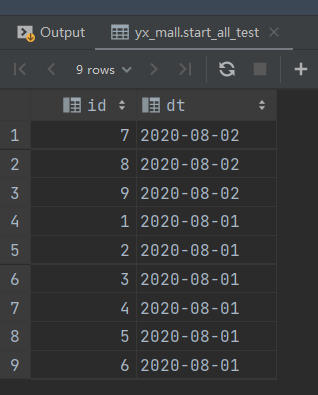
将 2020-08-02 新用户插入全量表
-- 将 2020-08-02 新用户插入全量表
insert into table start_all_test
select t1.id,
t1.dt
from start_day_test t1
left join start_all_test t2
on t1.id = t2.id
where t1.dt = "2020-08-02"
and t2.id is null;
检查结果
select *
from start_all_test;
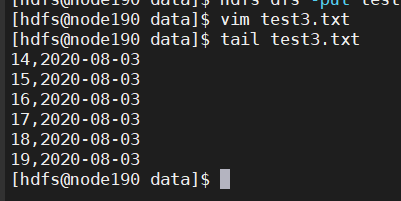
加载 2020-08-03 的数据
vim test3.txt
14,2020-08-03
15,2020-08-03
16,2020-08-03
17,2020-08-03
18,2020-08-03
19,2020-08-03
上传数据
hdfs dfs -put test3.txt /origin_data/cpucode/test/

装载
-- 装载2020-08-03数据
load data inpath '/origin_data/cpucode/test/test3.txt'
into table start_day_test;
-- 查询数据
select *
from start_day_test;
将新用户数据插入 全部表中
-- 装载新用户
insert into table start_all_test
select t1.id,
t1.dt
from start_day_test t1
left join start_all_test t2
on t1.id = t2.id
where t1.dt = '2020-08-03'
and t2.id is null;
-- 查询所有用户
select *
from start_all_test;
创建 DWS 层表
-- 删除用户留存明细
drop table if exists dws_member_add_day;
-- 创建 用户留存明细
create table dws_member_add_day
(
`device_id` string comment '设备id',
`uid` string comment '用户id',
`app_v` string comment 'app版本',
`os_type` string comment '系统版本',
`language` string comment '语言',
`channel` string comment '渠道',
`area` string comment '地区',
`brand` string comment '品牌',
`dt` string
) comment '每日新增会员明细'
stored as parquet;
装载数据
-- 装载数据
insert into table dws_member_add_day
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt
from dws_member_start_day t1
left join
dws_member_add_day t2
on t1.device_id = t2.device_id
where t1.dt = '2020-07-21'
and t2.device_id is null;
查询数据
-- 查询数据
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
dt
from dws_member_add_day
where dt = '2020-07-21';

加载DWS层数据脚本
vim script/member_active/dws_load_member_add_day.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
-- 装载数据
insert into table dws_member_add_day
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt
from dws_member_start_day t1
left join
dws_member_add_day t2
on t1.device_id = t2.device_id
where t1.dt = '$do_date'
and t2.device_id is null;
"
hive -e "$sql"
创建ADS层表
drop table if exists ads_new_member_cnt;
-- 创建新增用户数
create table ads_new_member_cnt
(
`cnt` string
) comment '新增用户数'
partitioned by (`dt` string)
row format delimited fields terminated by ',';
装载数据
-- 装载数据
insert overwrite table ads_new_member_cnt
partition (dt = '2020-07-21')
select count(1)
from dws_member_add_day
where dt = '2020-07-21';
查询数据
-- 查询数据
select cnt,
dt
from ads_new_member_cnt
where dt = '2020-07-21';
加载ADS层数据脚本
vim script/member_active/ads_load_member_add.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
-- 装载数据
insert overwrite table ads_new_member_cnt
partition (dt = '$do_date')
select count(1)
from dws_member_add_day
where dt = '$do_date';
"
hive -e "$sql"
小结
调用脚本次序:
dws_load_member_add_day.sh
ads_load_member_add.sh
留存用户
留存用户:某段时间的新增用户,经过一段时间后,仍继续使用应用
留存率 : 留存用户占当时新增用户的比例
需求:1日、2日、3日的用户留存数和用户留存率
| 30 | 31 | 1 | 2 | |
|---|---|---|---|---|
| 10W 新用户 | 3W | 1日留存数 | ||
| 20W | 5W | 2日留存数 | ||
| 30W | 4W | 3日留存数 |
- 10W 新用户:
dws_member_add_day(dt = 08-01)明细 - 3W: 在1号是新用户,在2日启动了(2日的启动日志)
dws_member_start_day
创建DWS层表
-- 用户留存明细
drop table if exists dws_member_retention_day;
create table dws_member_retention_day
(
`device_id` string comment '设备id',
`uid` string comment '用户id',
`app_v` string comment 'app版本',
`os_type` string comment '系统版本',
`language` string comment '语言',
`channel` string comment '渠道',
`area` string comment '地区',
`brand` string comment '品牌',
`add_date` string comment '用户新增时间',
`retention_date` int comment '留存天数'
) comment '每日用户留存明细'
partitioned by (`dt` string)
stored as parquet;
装载数据
查询当前留存数
set hivevar:do_date= 2020-07-22;
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt add_date,
1
from dws_member_start_day t1
join dws_member_add_day t2
on
t1.device_id = t2.device_id
where t1.dt = '${do_date}'
and t2.dt = date_add('${do_date}', -1);
装载数据
set hivevar:do_date= 2020-07-22;
insert overwrite table dws_member_retention_day
partition (dt = '${do_date}')
(
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt add_date,
1
from dws_member_start_day t1
join dws_member_add_day t2
on t1.device_id = t2.device_id
where t1.dt = '${do_date}'
and t2.dt = date_add('${do_date}', -1)
union all
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt add_date,
2
from dws_member_start_day t1
join dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('${do_date}', -2)
and t1.dt = '${do_date}'
union all
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
t1.dt add_date,
3
from dws_member_start_day t1
join dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('${do_date}', -3)
and t1.dt = '${do_date}'
);
查询数据
-- 查询数据
set hivevar:do_date= 2020-07-22;
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
add_date,
retention_date,
dt
from dws_member_retention_day
where dt = '${do_date}';

可能出现 :
return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
一般是内部错误
1、找日志(hive.log【简略】 /MR的日志【详细】)hive.log=> 默认情况下/tmp/root/hive.log(hive-site.conf)
MR的日志 => 启动historyserver、日志聚合 + SQL运行在集群模式
加载DWS层数据脚本
vim script/member_active/dws_load_member_retention_day.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
drop table if exists tmp.tmp_member_retention;
create table tmp.tmp_member_retention as
(
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
1
from dws.dws_member_start_day t1 join dws.dws_member_add_day
t2 on t1.device_id=t2.device_id
where t2.dt=date_add('$do_date', -1)
and t1.dt='$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
2
from dws.dws_member_start_day t1 join dws.dws_member_add_day
t2 on t1.device_id=t2.device_id
where t2.dt=date_add('$do_date', -2)
and t1.dt='$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
3
from dws.dws_member_start_day t1 join dws.dws_member_add_day
t2 on t1.device_id=t2.device_id
where t2.dt=date_add('$do_date', -3)
and t1.dt='$do_date'
);
insert overwrite table dws.dws_member_retention_day
partition(dt='$do_date')
select * from tmp.tmp_member_retention;
"
hive -e "$sql"
创建ADS层表
-- 用户留存数
drop table if exists ads_member_retention_count;
create table ads_member_retention_count
(
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数'
) comment '用户留存数'
partitioned by (`dt` string)
row format delimited fields terminated by ',';
装载数据
-- 装载数据
set hive.execution.engine = spark;
set hivevar:do_date= 2020-07-22;
insert overwrite table ads_member_retention_count
partition (dt = '${do_date}')
select add_date,
retention_date,
count(*) retention_count
from dws_member_retention_day
where dt = '${do_date}'
group by add_date, retention_date;
查询数据
-- 查询
select add_date,
retention_day,
retention_count,
dt
from ads_member_retention_count
where dt = '${do_date}'

会员留存率
-- 会员留存率
drop table if exists ads_member_retention_rate;
create table ads_member_retention_rate
(
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数',
`new_mid_count` bigint comment '当日会员新增数',
`retention_ratio` decimal(10, 2) comment '留存率'
) comment '会员留存率'
partitioned by (`dt` string)
row format delimited fields terminated by ',';
装载数据
-- 装载数据
set hive.execution.engine = spark;
set hivevar:do_date= 2020-07-22;
insert overwrite table ads_member_retention_rate
partition (dt = '${do_date}')
select t1.add_date,
t1.retention_day,
t1.retention_count,
t2.cnt,
t1.retention_count / t2.cnt * 100
from ads_member_retention_count t1
join ads_new_member_cnt t2
on t1.dt = t2.dt
where t1.dt = '${do_date}';
查询数据
-- 查询数据
select add_date,
retention_day,
retention_count,
new_mid_count,
retention_ratio,
dt
from ads_member_retention_rate
where dt = '${do_date}';

加载ADS层数据
vim script/member_active/ads_load_member_retention.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_retention_count
partition (dt='$do_date')
select add_date,
retention_date,
count(*) retention_count
from dws.dws_member_retention_day
where dt='$do_date'
group by add_date, retention_date;
insert overwrite table ads.ads_member_retention_rate
partition (dt='$do_date')
select t1.add_date,
t1.retention_day,
t1.retention_count,
t2.cnt,
t1.retention_count / t2.cnt * 100
from ads.ads_member_retention_count t1 join
ads.ads_new_member_cnt t2 on t1.dt = t2.dt
where t1.dt='$do_date';
"
hive -e "$sql"
最后一条 SQL 的连接条件应为:
t1.add_date = t2.dt
小结
用户活跃度 — 活跃用户数、新增用户、留存用户
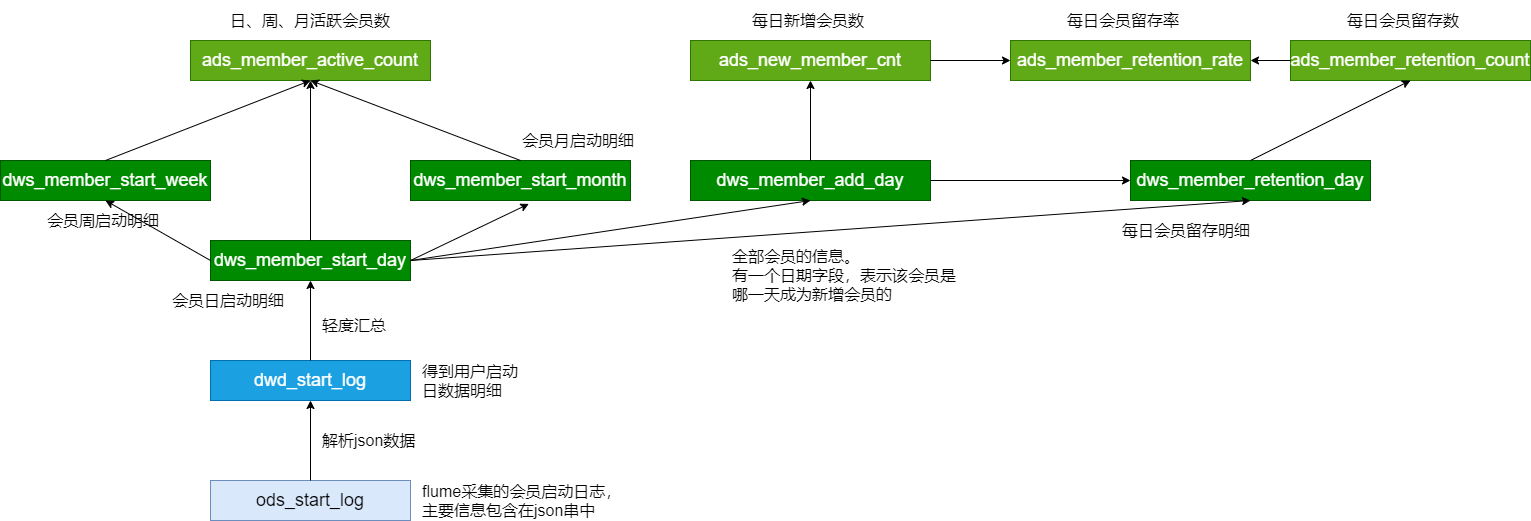
脚本调用次序:
# 加载ODS / DWD 层采集
ods_load_startlog.sh
dwd_load_startlog.sh
# 活跃用户
dws_load_member_start.sh
ads_load_member_active.sh
# 新增用户
dws_load_member_add_day.sh
ads_load_member_add.sh
# 用户留存
dws_load_member_retention_day.sh
ads_load_member_retention.sh
Datax 数据导出
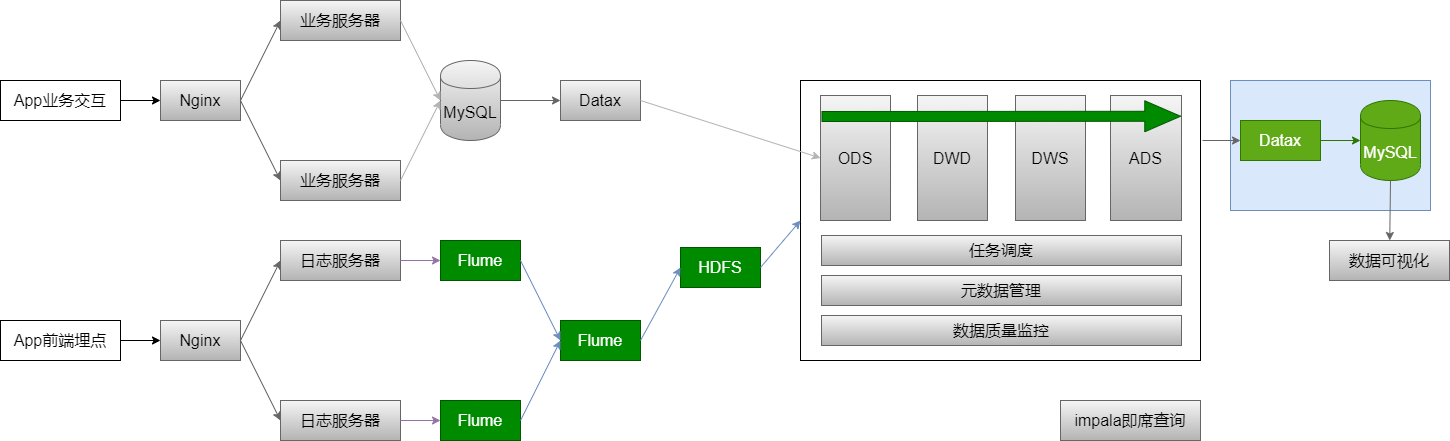
ADS 有 4 张表需要从数据仓库的 ADS 层导入MySQL,即:Hive => MySQL
ads.ads_member_active_count
ads.ads_member_retention_count
ads.ads_member_retention_rate
ads.ads_new_member_cnt
MySQL 建表
活跃用户数
drop table if exists ads_member_active_count;
-- 活跃用户数
create table ads_member_active_count
(
`dt` varchar(10) comment '统计日期',
`day_count` int comment '当日用户数量',
`week_count` int comment '当周用户数量',
`month_count` int comment '当月用户数量',
primary key (dt)
);
-- 查询
select dt,
day_count,
week_count,
month_count
from ads_member_active_count
where dt = '2020-06-21';
新增用户数
-- 新增用户数
drop table if exists ads_new_member_cnt;
create table ads_new_member_cnt
(
`dt` varchar(10) comment '统计日期',
`cnt` string comment '用户数',
primary key (dt)
);
-- 查询
select dt,
cnt
from ads_new_member_cnt
where dt = '2020-06-21';
用户留存数
-- 用户留存数
drop table if exists ads_member_retention_count;
create table ads_member_retention_count
(
`dt` varchar(10) comment '统计日期',
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数',
primary key (dt)
) comment '用户留存情况';
-- 查询
select dt,
add_date,
retention_day,
retention_count
from ads_member_retention_count
where dt = '2020-06-21';
用户留存率
-- 用户留存率
drop table if exists ads_member_retention_rate;
create table ads_member_retention_rate
(
`dt` varchar(10) COMMENT '统计日期',
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数',
`new_mid_count` bigint comment '当日用户新增数',
`retention_ratio` decimal(10, 2) comment '留存率',
primary key (dt)
) comment '用户留存率';
-- 查询
select dt,
add_date,
retention_day,
retention_count,
new_mid_count,
retention_ratio
from ads_member_retention_rate
where dt = '2020-06-21';
导出数据
导出活跃用户数( ads_member_active_count )
export_member_active_count.json
hdfsreader => mysqlwriter
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/lagou/hive/warehouse/ads.db/ads_member_active_count/dt=$do_date/*",
"defaultFS": "hdfs://hadoop1:9000",
"column": [
{
"type": "string",
"value": "$do_date"
},
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "hive",
"password": "12345678",
"column": [
"dt",
"day_count",
"week_count",
"month_count"
],
"preSql": [
""
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop2:3306/dwads?useUnicode=true&characterEncoding=utf-8",
"table": [
"ads_member_active_count"
]
}
]
}
}
}
]
}
}
执行命令:
python datax.py -p "-Ddo_date=2020-08-02" /data/lagoudw/script/member_active/t1.json
export_member_active_count.sh
#!/bin/bash
JSON=/data/lagoudw/script/member_active
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" $JSON/export_member_active_count.json 2020-08-02
高仿日启动数据测试
数据采集 => ODS => DWD => DWS => ADS> MySQL
活跃用户、新增用户、用户留存
- DAU: Daily Active User(日活跃用户)
- MAU: monthly active user(月活跃用户)
假设 App 的 DAU 在 1000W 左右,日启动数据大概 1000W 条 ( 3.5G+,每条记录约 370 字节 )
测试3天的数据:7月21日、7月22日、7月23日
Hive on MR 测试
选择 7月21日 的启动日志进行测试
修改 Flume
修改flume的参数:
- 1G滚动一次
- 加大channel缓存
- 加大刷新 hdfs 的缓存
# 配置文件滚动方式(文件大小1G)
a1.sinks.k1.hdfs.rollSize = 1073741824
a1.channels.c1.capacity = 500000
a1.channels.c1.transactionCapacity = 20000
# 向hdfs上刷新的event个数
a1.sinks.k1.hdfs.batchSize = 10000
清理数据
rm -f /data/flume/conf/startlog_position.json
rm -rf /data/flume/logs/start/*
hdfs dfs -rm -r -f /user/data/logs/start/dt=2020-07-21
启动 Flume
flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lagoudw/conf/flume-log2hdfs4.conf -name a1 -Dflume.root.logger=INFO,console
写日志
cp /data/lagoudw/logs/start/start0721.log
cp /data/lagoudw/logs/start/start0722.log
cp /data/lagoudw/logs/start/start0723.log
# 检查 hdfs 文件是否到达
hdfs dfs -ls /user/data/logs/start/dt=2020-07-21
1个文件大小 3.5 G,时间4分钟左右
Hive on Tez 测试
07-22(新增600W) / 0723(新增200W):1000W条左右
执行脚本
SCRIPT_HOME=/data/lagoudw/script/member_active
# 加载 ODS 层数据(文件与表建立关联)
sh $SCRIPT_HOME/ods_load_startlog.sh 2020-07-22
# 加载 ODS 层数据(解析json数据)
sh $SCRIPT_HOME/dwd_load_startlog.sh 2020-07-22
# 活跃会员
sh $SCRIPT_HOME/dws_load_member_start.sh 2020-07-22
sh $SCRIPT_HOME/ads_load_member_active.sh 2020-07-22
# 新增会员
sh $SCRIPT_HOME/dws_load_member_add_day.sh 2020-07-22
sh $SCRIPT_HOME/ads_load_member_add.sh 2020-07-22
# 会员留存
sh $SCRIPT_HOME/dws_load_member_retention_day.sh 2020-07-22
sh $SCRIPT_HOME/ads_load_member_retention.sh 2020-07-22
SCRIPT_HOME=/data/lagoudw/script/member_active
# 加载 ODS 层数据(文件与表建立关联)
sh $SCRIPT_HOME/ods_load_startlog.sh 2020-07-23
# 加载 ODS 层数据(解析json数据)
sh $SCRIPT_HOME/dwd_load_startlog.sh 2020-07-23
# 活跃会员
sh $SCRIPT_HOME/dws_load_member_start.sh 2020-07-23
sh $SCRIPT_HOME/ads_load_member_active.sh 2020-07-23
# 新增会员
sh $SCRIPT_HOME/dws_load_member_add_day.sh 2020-07-23
sh $SCRIPT_HOME/ads_load_member_add.sh 2020-07-23
# 会员留存
sh $SCRIPT_HOME/dws_load_member_retention_day.sh 2020-07-23
sh $SCRIPT_HOME/ads_load_member_retention.sh 2020-07-23
Error: Java heap space
遇到的问题:Error: Java heap space
原因:内存分配问题
解决思路:给map、reduce task分配合理的内存;map、reduce task处理合理的数据
现在情况下map task分配了多少内存?使用的是缺省参数每个task分配200M内存【mapred.child.java.opts】
每个节点:8 core / 32G;mapred.child.java.opts = 3G
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx3072m</value>
</property>
调整 map 个数:
mapred.max.split.size=256000000
调整 reduce 个数:
hive.exec.reducers.bytes.per.reducer
hive.exec.reducers.max
用户留存率的计算
script/member_active/ads_load_member_retention.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_retention_count
partition (dt='$do_date')
select add_date, retention_date,
count(*) retention_count
from dws.dws_member_retention_day
where dt='$do_date'
group by add_date, retention_date;
insert overwrite table ads.ads_member_retention_rate
partition (dt='$do_date')
select t1.add_date,
t1.retention_day,
t1.retention_count,
t2.cnt,
t1.retention_count/t2.cnt*100
from ads.ads_member_retention_count t1 join
ads.ads_new_member_cnt t2 on t1.add_date=t2.dt
where t1.dt='$do_date';
"
hive -e "$sql"
修改后的代码(计算留存率):
select t1.*, t2.*
from ads.ads_member_retention_count t1 join
ads.ads_new_member_cnt t2
on t1.add_date = t2.dt
where t1.dt='2020-07-23';
主要改的是连接条件。将连接条件改为:t1.add_date=t2.dt
SCRIPT_HOME=/data/lagoudw/script/member_active
sh $SCRIPT_HOME/ads_load_member_retention.sh 2020-07-23

若有收获,就点个赞吧
0 人点赞
