[toc]
数据仓库建模方法
适合存储的模型 , 优点 :
- 性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐
- 成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本
- 效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率
- 质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性
维度模型
维度建模从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能
维度建模 :
- 星型模型
- 雪花模型
设计步骤 :
- 业务过程:单个业务事件,如 : 交易的支付、退款 ; 某个事件状态,如 : 当前的账户余额 ; 一系列相关业务事件组成的业务流程
- 数据粒度 : 在事件分析中,先预判所有分析需要细分的程度,从而决定选择的粒度
- 维表 : 选择好粒度后,就基于此粒度设计维表,包括维度属性,用于分析时 , 进行分组和筛选
- 事实 : 确定分析需要衡量的指标
维度建模对技术要求不高,快速上手,敏捷迭代,快速交付;更快速完成分析需求,较好的大规模复杂查询的响应性能
数据仓库分层
数据仓库 : 数据建模、ETL(数据抽取、转换、加载)、作用调度等在内的完整的理论体系流程
数据仓库在构建过程中都会进行分层处理。业务不同,分层的技术处理手段也不同
分层的主要原因 : 在管理数据的时候,能对数据有一个更加清晰的掌控
主要原因:
- 清晰的数据结构 : 每一个数据分层都有它的作用域,在使用表时能更方便地定位和理解
- 将复杂的问题简单化 : 将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的问题,比较简单和容易理解。且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的地方开始修复
- 减少重复开发 : 规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
- 屏蔽原始数据的异常 : 屏蔽业务的影响,不必改一次业务就需要重新接入数据
- 数据血缘的追踪 : 给业务呈现的是能直接使用业务表,但是它的来源很多,如果有一张来源表出问题了,借助血缘最终能够快速准确地定位到问题,并清楚它的危害范围
数仓的常见分层:
- 数据操作层
- 数据仓库层
- 应用数据层(数据集市层)
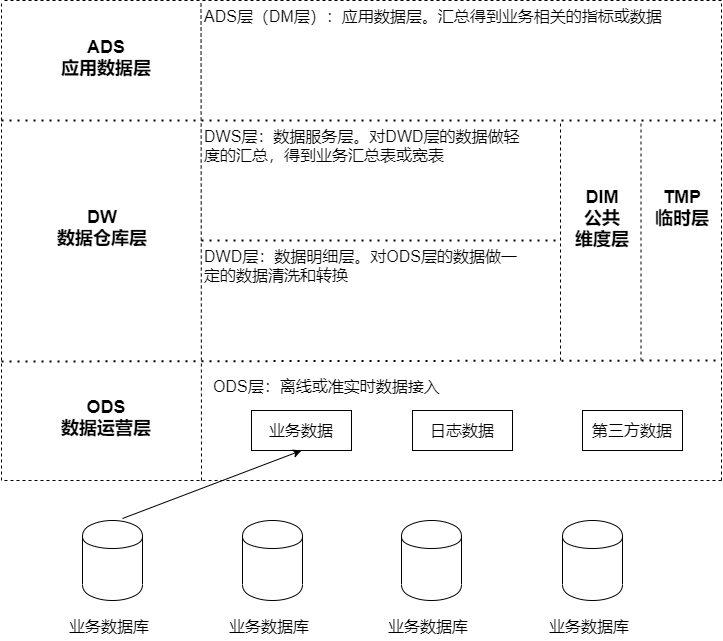
ODS(Operation Data Store 数据准备区): 数据仓库源头系统的数据表通常会原封不动的存储一份。它们是后续数据仓库层加工数据的来源
ODS 层数据的主要来源:
- 业务数据库 : 可用 DataX、Sqoop 来抽取,每天定时抽取一次;在实时应用中,可用 Canal 监听 MySQL 的 Binlog,实时接入变更的数据
- 埋点日志 : 线上系统会打入各种日志,这些日志一般以文件的形式保存,可以用 Flume 定时抽取
- 其他数据源 : 从第三方购买的数据、或 网络爬虫抓取的数据
DW(Data Warehouse 数据仓库层): DWD、DWS、DIM 层,由 ODS 层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标
- DWD(Data Warehouse Detail 细节数据层): 业务层与数据仓库的隔离层。以业务过程作为建模驱动,基于每个具体的业务过程特点,构建细粒度的明细层事实表。可结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余 ( 宽表化处理 )
- DWS(Data Warehouse Service 服务数据层): 基于 DWD 的基础数据,整合汇总成分析某一个主题域的服务数据。以分析的主题为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表
- 公共维度层(DIM):基于维度建模理念思想,建立一致性维度
- TMP层 :临时层,存放计算过程中临时产生的数据
ADS(Application Data Store 应用数据层): 基于 DW 数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等
数据仓库模型
事实表与维度表
事实表的主要特点 : 数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据 , 表多(各种各样的事实表);数据量大
事实表根据数据的粒度分为:
- 事务事实表
- 周期快照事实表
- 累计快照事实表
常见维度表:
- 时间维度
- 地域维度
- 商品维度
事实表分类
事务事实表
事务事实表 ( 原子事实表 ) : 记录的事务层面的事实,保存的是最原子的数据
事务事实表中的数据 : 在事务事件发生后产生,数据的粒度通常是每个事务一条记录。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式 : 增量更新
事务事实表的日期维度记录 : 事务发生的日期,它记录的事实 : 事务活动的内容。用户可以通过事务事实表对事务行为进行特别详细的分析
如:订单表
周期快照事实表
周期快照事实表 : 以具有规律性的、可预见的时间间隔来记录事实,时间间隔 , 如 : 每天、每月、每年 , 如 : 销售日快照表、库存日快照表。
统计的是间隔周期内的度量统计,如历史至今、自然年至今、季度至今等等
周期快照事实表的粒度 : 每个时间段一条记录,通常比事务事实表的粒度要粗,是在事务事实表之上建立的聚集表
周期快照事实表的维度个数比事务事实表要少,但是记录的事实要比事务事实表多
如:商家日销售表(无论当天是否有销售发生,都记录一行)日期、商家名称、销售量、销售额
累积快照事实表
累积快照事实表和周期快照事实表有些相似之处,它们存储的都是事务数据的快照信息
不同 : 周期快照事实表记录的确定的周期的数据,而累积快照事实表记录的不确定的周期的数据
累积快照事实表 : 完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点。另外还会有指示最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,所以必须使用代理关键字来处理未定义的日期,而且这类事实表在数据加载完后,是可以对它进行更新的,来补充随后知道的日期信息
如:订货日期、预定交货日期、实际发货日期、实际交货日期、数量、金额、运费
如:商家本周、本月、本年累计销售表
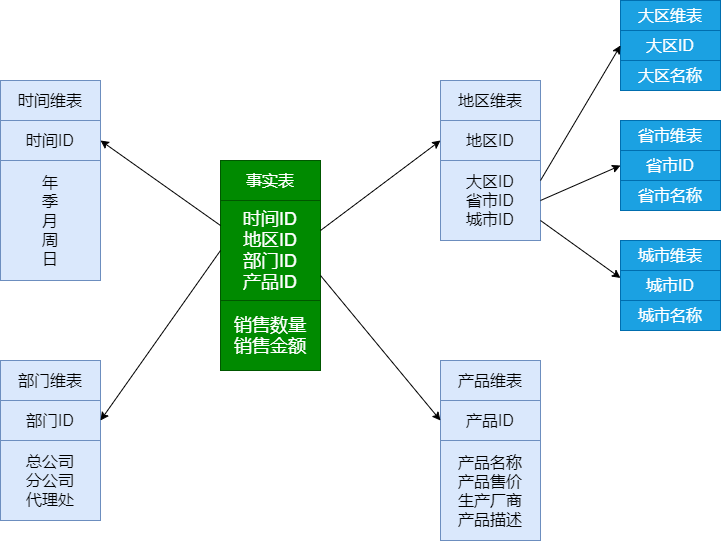
星型模型
星型模是一种多维的数据关系,它由一个事实表和一组维表组成
事实表在中心,周围围绕地连接着维表
事实表中包含了大量数据,没有数据冗余
维表是逆规范化的,包含一定的数据冗余
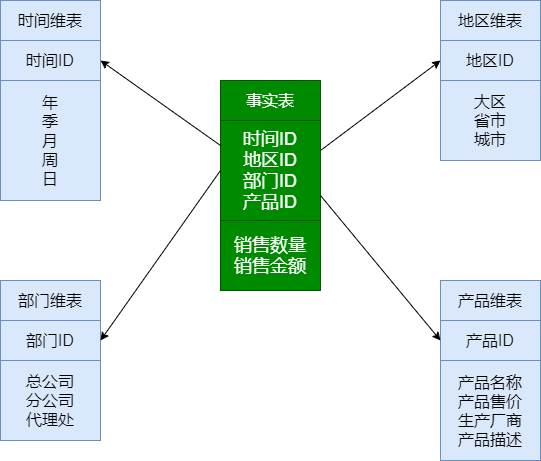
雪花模型
雪花模式 : 星型模型的变种,维表是规范化的,模型类似雪花的形状
特点:雪花型结构去除了数据冗余
- 星型模型存在数据冗余,所以在查询统计时只需要做少量的表连接,查询效率高
- 星型模型不考虑维表正规化的因素,设计、实现容易
- 在数据冗余可接受的情况下,实际上使用星型模型比较多
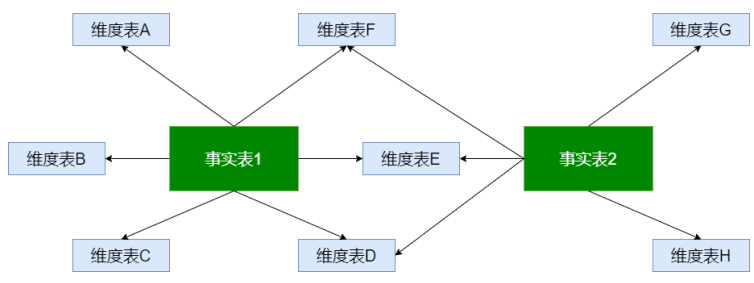
事实星座
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,该模式可以看做星型模式的汇集 ( 星系模式 , 事实星座模式 )
特点:公用维表
元数据
元数据(Metadata): 关于数据的数据。元数据打通了源数据、数据仓库、数据应用,记录了数据从产生到消费的全过程
元数据 : 相当于所有数据的地图,能知道数据仓库中:
- 有哪些数据
- 数据的分布情况
- 数据类型
- 数据之间有什么关系
- 哪些数据经常被使用,哪些数据很少有人光顾
在大数据平台中,元数据贯穿大数据平台数据流动的全过程,主要包括数据源元数据、数据加工处理过程元数据、数据主题库专题库元数据、服务层元数据、应用层元数据等
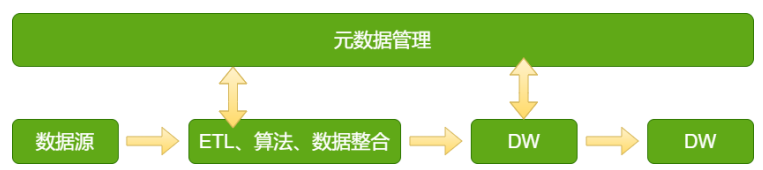
元数据分类型:
- 技术元数据:库表结构、数据模型、ETL程序、SQL程序
- 业务元数据:业务指标、业务代码、业务术语
- 管理元数据:数据所有者、数据质量、数据安全

若有收获,就点个赞吧
0 人点赞
