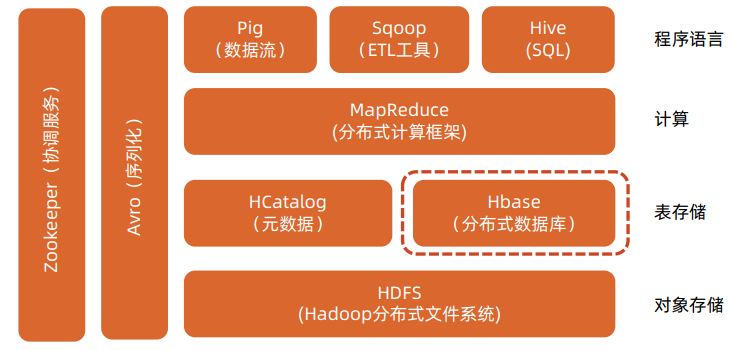
HBase概述
背景
结构化数据适合使用关系数据库系统 ( RDMS ) 进行存储和处理
半结构化数据不适合使用关系数据库进行存储和处理 , 就使用 Hbase
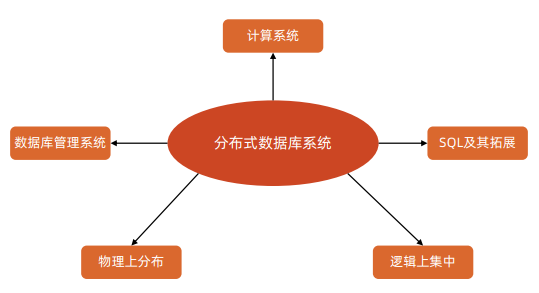
分布式数据库
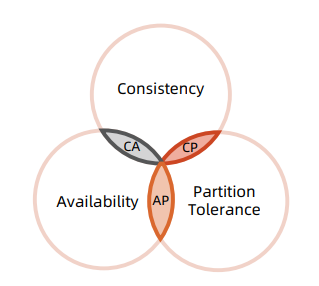
分布式数据库首先得是一个数据库 , 分布式数据库无法逃开 CAP 理论
分布式数据库的一些特征:
- 数据分布式存储
- 行级事务管理
- 水平拓展性好
- 支持标准SQL
- 数据一致性(强,最终)
- 事务透明性
- 两阶段提及
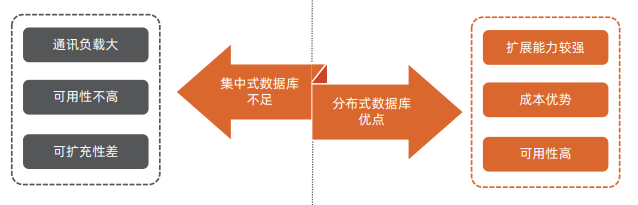
从集中式数据库走向分布式数据库
分片分组
分片(sharding) : 解决扩展性问题,属于水平拆分
分表 : 解决数据量过大的问题
分库 : 解决数据库性能瓶颈的问题
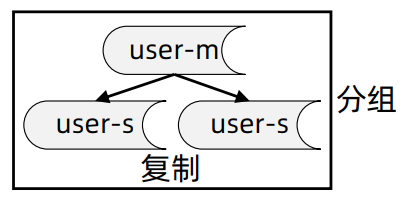
分组(group) : 解决可用性问题,通常通过主从复制 ( replication ) 的方式实现
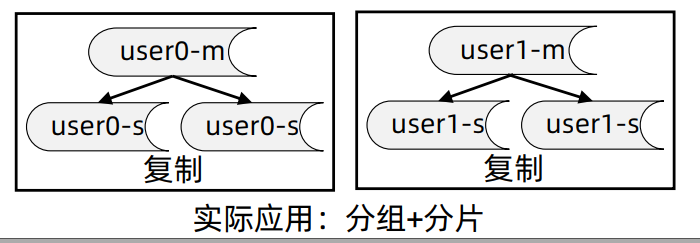
分片+分组:互联网公司数据库实际软件架构是 ( 大数据量下 )
分库分表
分表:把一张表分成多个小表
关系型数据库大于一定数据量时 , 检索性能会急剧下降。在大数据时,所有数据都存于一张表,容易超过数据库表可承受的数据量阈值
分库:
单纯的分表只能解决数据量过大导致检索变慢,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以可以采用分库,来解决大数据量和高并发的问题
跨库跨表的 join 问题:
原本一次查询能够完成的业务,可能需要多次查询才能完成
HBase 的逻辑视图
数据模型
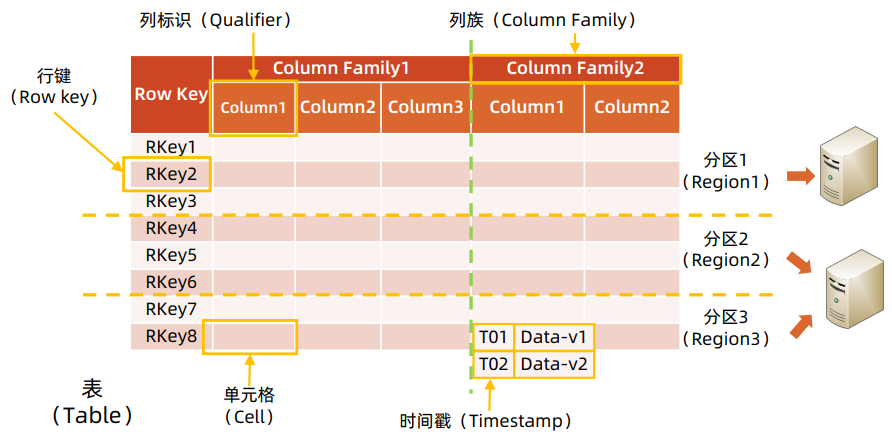
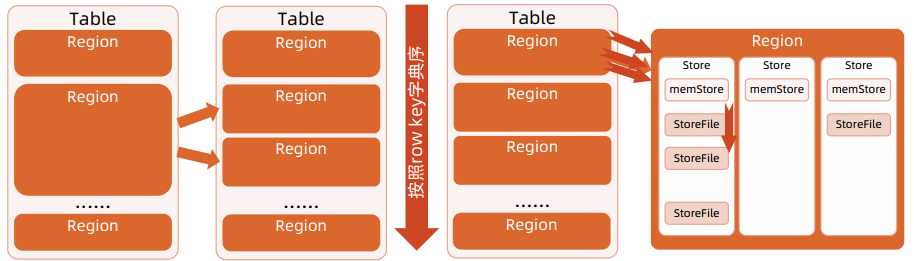
Row Key
行关键字(row key):行的主键,唯一标识一行数据 ( 最大长度 : 64KB ) ,用于检索记录
存储时,按照 row key 字典序排序存储,利用该特性可以根据 “ 位置相关性 ” 设计 row key
访问 Hbase 表有三种方式:
- 通过单个 row key 访问
- 通过 row key 的 range
- 全表扫描
Column family
列族(Column Family):行中的列被分为 “ 列族 ”
同一个列族的所有成员具有相同的列族前缀
一般存放在同一列族下的数据通常都属于同一类型(同一个列族下的数据压缩在一起)
表的列族必须在创建表时预先定义
列键(Column Key , 列名):必须以列族作为前缀,格式 = 列族:限定词
Timestamp和Cell
时间戳(Timestamp)( 类型 : 64 位整型 ) :插入单元格时的时间戳,默认作为单元格的版本号
不同版本的数据按照时间戳倒序排序,即最新的数据排在最前面
存储单元格(Cell):在 HBase 中,值作为一个单元保存在单元格中
要定位一个单元,需要满足 “ 行键 + 列键 + 时间戳 ” 三个要素
每个 Cell 保存着同一份数据的多个版本
Cell 中没有数据类型,完全是字节存储
HBase的物理视图
Key-Value
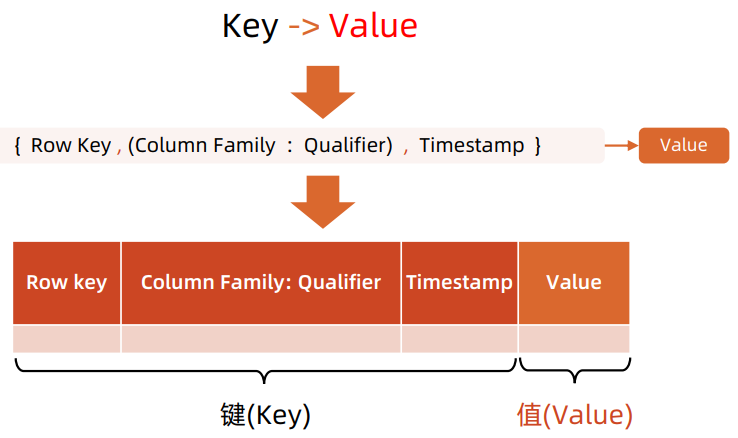
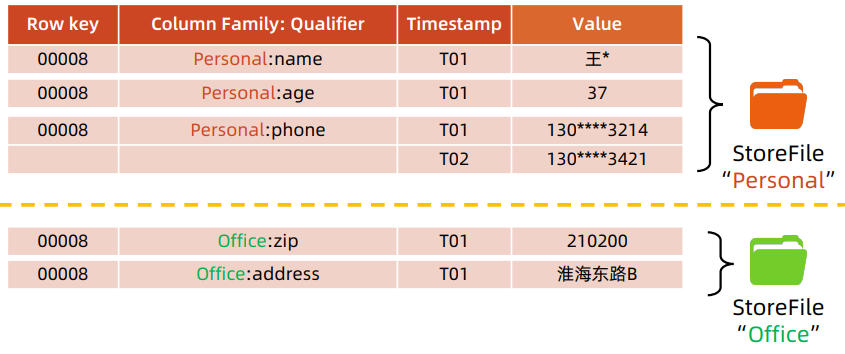
StoreFile
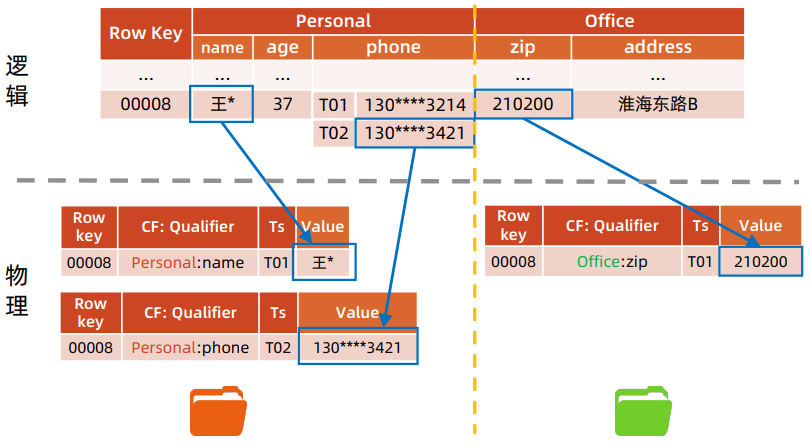
逻辑 vs 物理
HBase 整体架构
功能组件
- API
- Master Server
- Region Server
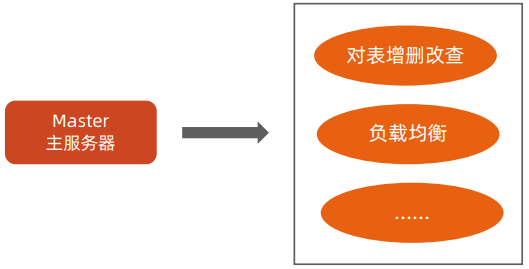
Master 服务器
- 维护和管理分区信息
- 维护一个Region Server 列表
- 负责对 Region 进行分配
- 负载均衡
Region 服务器
HBase 整体架构
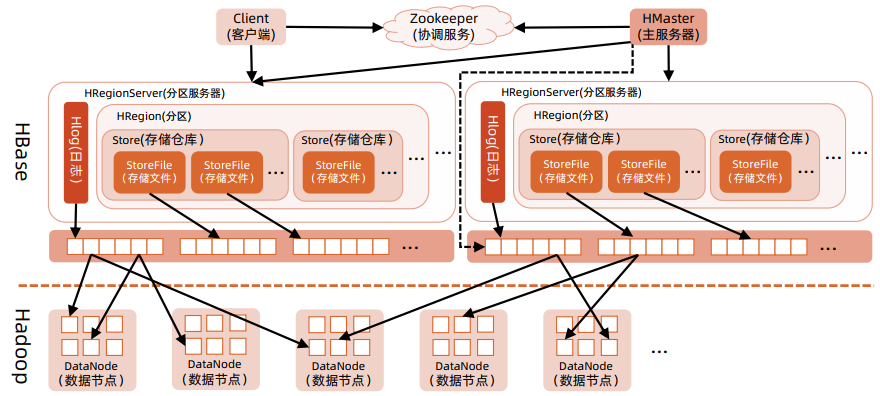
HMaster
每台 Region Server 会与 Master 进行通信,HMaster 的主要任务 : 告诉 RegionServer 需要维护哪些 Region
具体功能 :
- 管理用户对表的增删改查操作
- 管理 Region Server 的负载均衡,动态调整 Region 分布
- 在 Region 分裂后,负责新的 Region 的分配
- 在 Region Server 停机后,负责失效 Region Server 上的 Region 的迁移
Region
Region:由多个 Store 组成,HBase 使用表存储数据集,当表的大小 > 设定的值时,HBase 会自动将表划分为不同的 Region,它是HBase 集群上分布式存储和负载均衡的最小单位
Store:由两部分组成:MemStore 和 StoreFile。首先用户写入的数据存放到 MemStore 中,当 MemStore 满了后刷入 StoreFile
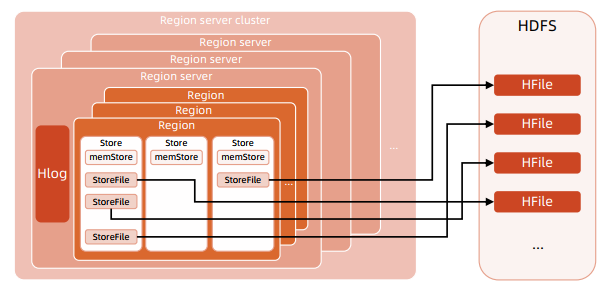
Region Server
Region Server:由多个 Region 组成,在整个集群中可能存在多个节点,每个节点只能运行一个 Region Server,负责对 HDFS 中读写数据和管理 Region 和 HLog
HLog:Write ahead log(WAL ),到达 Region 上的写操作首先被追加到 HLog 中,然后才被加载到 MemStore ,主要功能 : 故障修复,当某台 Region Server 发生故障,新的 Region Server 在加载 Region 时 , 可以通过 HLog 对数据进行恢复
WAL技术
WAL ( Write Ahead Log ) 预写日志,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性
当使用了 WAL,在重启之后系统可以通过比较日志和系统状态来决定是继续完成操作还是撤销操作
Hbase 实现 WAL 的方法将 HLog,Hbase 的 RegionServer 会将数据保存在内存中(MemStore),直到满足一定条件,将其 flush 到磁盘上。可以避免创建很多小文件
Zookeeper 和 Client
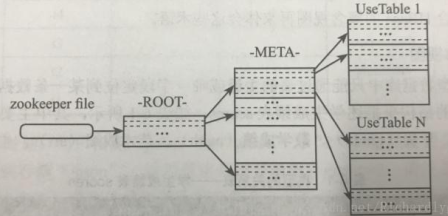
ZooKeeper:存储 HBase 的 ROOT 表(根数据表)和 META 表(元数据表),元数据表保存普通用户表的 Region 标识符信息,标识符格式为:表名+开始主键+唯一ID。 随着 Region 的分裂,标识符信息也会发生变化,分成多个 Region 后,需要由一个根数据表来贯穿多个元数据表
ZooKeeper 负责 Region Server 故障时,通知 HMaster 进行 Region 迁移
若 HMaster 出现故障,ZooKeeper 负责恢复 HMaster,并且保证有且只有一个 HMaster 正在运行
Client:客户端访问 HBase 的单位,访问时首先访问 Zookeeper — ROOT — META — table
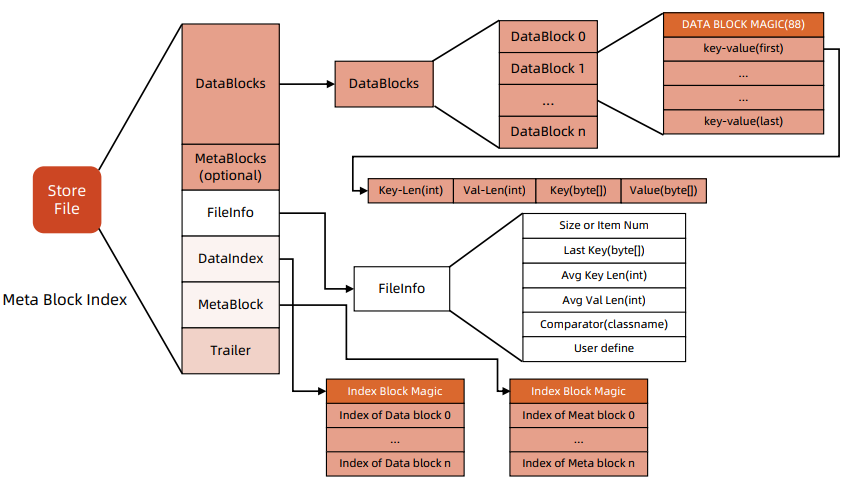
HFile
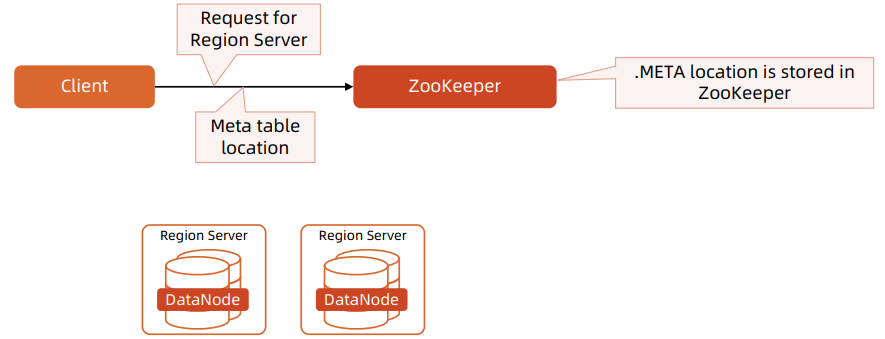
HBase读流程
Client 先访问 ZK 的 META 表,获取需要访问的 Region Server
Client 缓存 META 表在本地,从 META 表中找到相应 row key 需要访问的 Region Server
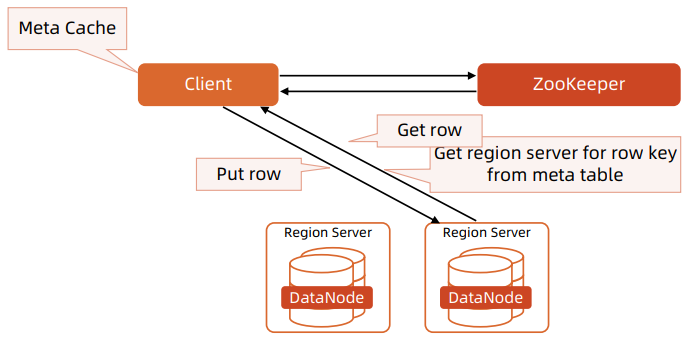
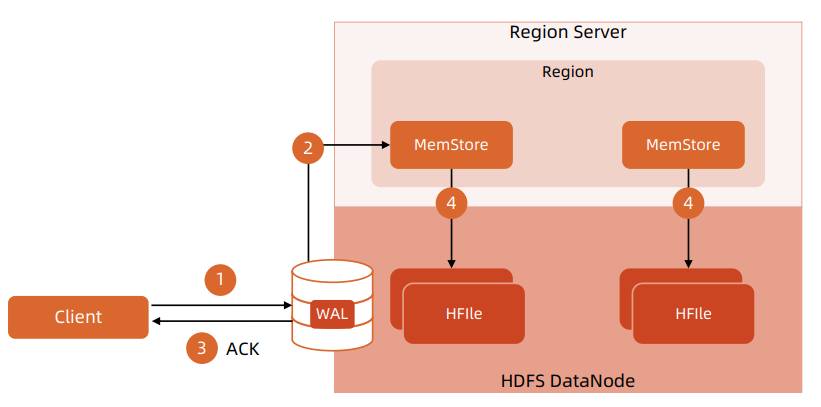
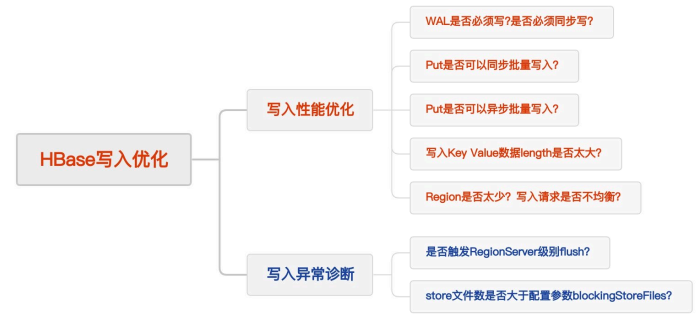
HBase写机制
- Client 的 Put 操作会将数据先写入WAL
- 当数据写入 WAL,然后将数据拷贝到 MemStore 。 MemStore 是内存空间,数据并未写入磁盘
- 一旦数据成功拷贝到 MemStore 。 Client 将收到 ACK
- 当 MemStore 中的数据达到阈值,数据会写入HFile
HBase API和实验
HBase Shell
DDL
| HBase Shell命令 | 功能描述 |
|---|---|
| create | 创建一张表 |
| list | 列出HBase中所有表 |
| drop | 删除一张表 |
| describe | 显示表的详细信息 |
| alter | 修改表的列族 |
| disable | 禁用表,使表无效 |
| enable | 启用表,使表有效 |
DML
| HBase Shell命令 | 功能描述 |
|---|---|
| put | 向指定单元添加值 |
| get | 获取行或单元格的值 |
| scan | 通过扫描表获取数据 |
| deleteall | 删除整行 |
| delete | 删除指定对象的值 |
| truncate | 清空表 |
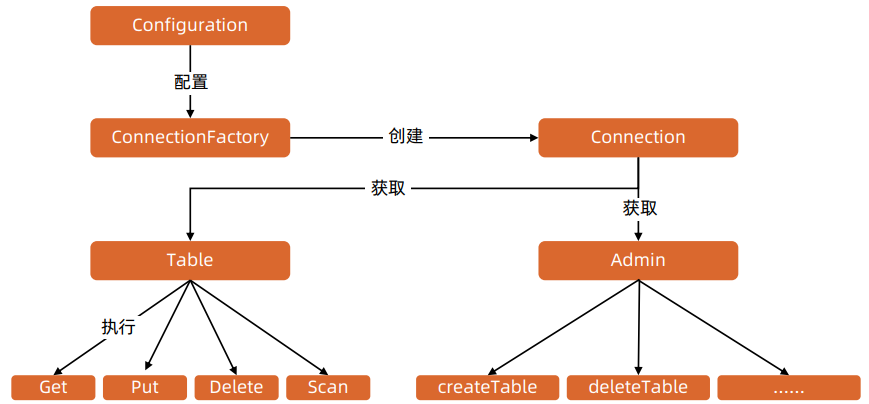
Java API
| Java类 | HBase数据模型中的概念 |
|---|---|
| Admin | HBase数据库 |
| Connection | |
| HBaseConfiguration | |
| HTableDescriptor | 表 |
| TableName | |
| Table | |
| HColumnDescriptor | 列族 |
| Put | 添加数据(put命令) |
| Get | 获取数据(get命令) |
| Scan | 扫描表(scan)命令 |
API 流程
HBase Compaction
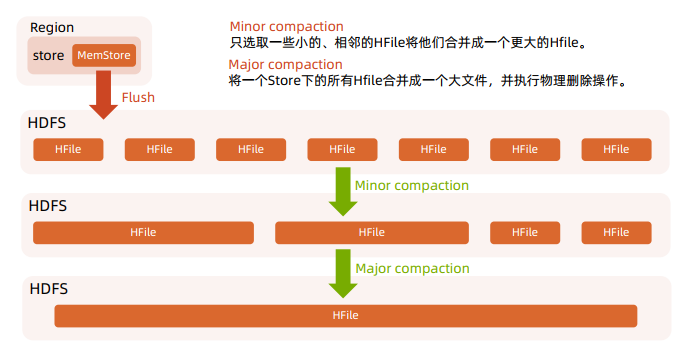
HBase 的 MemStore 在满足阈值时 , 会将内存中的数据刷写成 HFile,一个 MemStore 刷写就会形成一个 Hfile
这样同一个 Store 下的 HFile 会越来越多,文件太多会影响 HBase 查询性能,主要体现 : 查询数据的 IO 次数增加
为了优化查询性能,HBase 会合并小的 HFile 以减少文件数量 ( Compaction )
Compaction 的主要原因 :
- 将多个小的 HFile 合并成一个更大的 HFile 以增加查询性能
- 在合并过程中对过期的数据(超过TTL,被删除,超过最大版本号)进行真正的删除
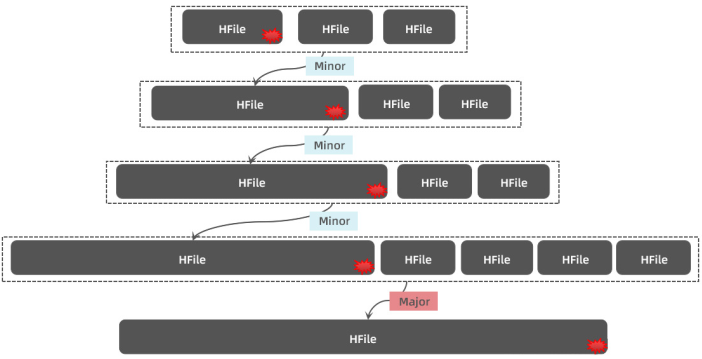
Compaction
Minor Compaction :将邻近的若干个 HFile 合并,在合并时会清理 TTL 的数据,但不会清理被删除的数据
Major Compaction:将一个 Store 下的所有 HFile 进行合并,并会清理掉过期的和被删除的数据 ( 删除全部需要删除的数据 ) 。但是 Major Compaction 时间较长,会消耗大量系统资源,对上层业务有比较大的影响。一般在生产环境下会关闭自动触发 Major Compaction ,改为手动在业务低峰期触发
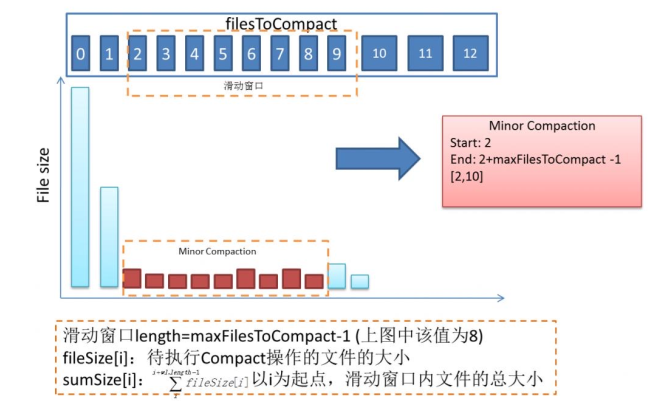
首先内存中维护着一个 filesToCompact(合并队列),在该队列中的 Hfile 将会被 Minor 合并
当有新的 HFile 文件产生时,如果同一个列簇下的文件数 >= hbase.hstore.compaction.min 时,就会将符合合并规则的文件放入合并队列
合并规则如下:
- 当该文件 <
hbase.hstore.compaction.min.size, 就会被添加到合并队列中 - 当该文件 >
hbase.hstore.compaction.max.size,就会从队列中被排除 - 当该文件 < 它后面
hbase.hstore.compaction.max(默认 : 10)个文件之和 *hbase.hstore.compaction.ratio(默认 : 1.2),该文件就会加入到合并队列中
存在的问题
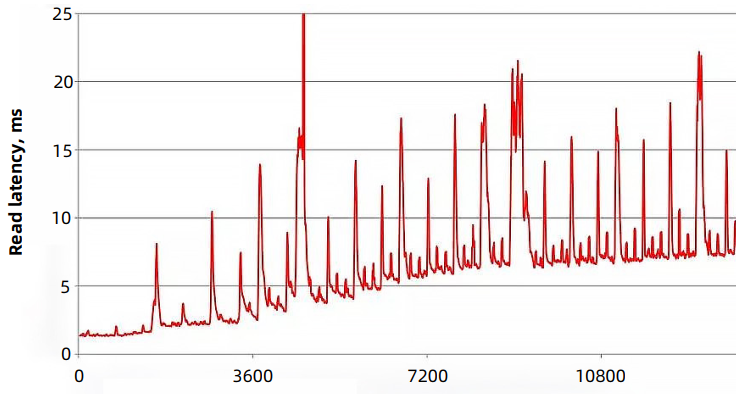
Compaction 是一个 IO 密集型操作,会对读写造成性能影响
对读的影响:
在 compaction 时 , 读性能就会降低,当有许多毛刺时 , 就是因为 compaction 时 , 读性能会降低,然后又回到正常水平
对写的影响:
HFile 个数超过 hbase.hstore.blockingStoreFiles(默认 : 7)时, 系统将会强制执行
当 compaction 进行文件合并时, 就会出现写阻塞。当数据生成速度很快时,HFile 会不断快速生成 , 就需要进行频繁 compaction ,从而限制写请求速度
compaction 会导致写放大。 当一次写入的数据,会被多次反复读取与写入,造成集群 IO 资源的浪费
HBase 调优
GC调优
- GC算法选择
- 参数调整
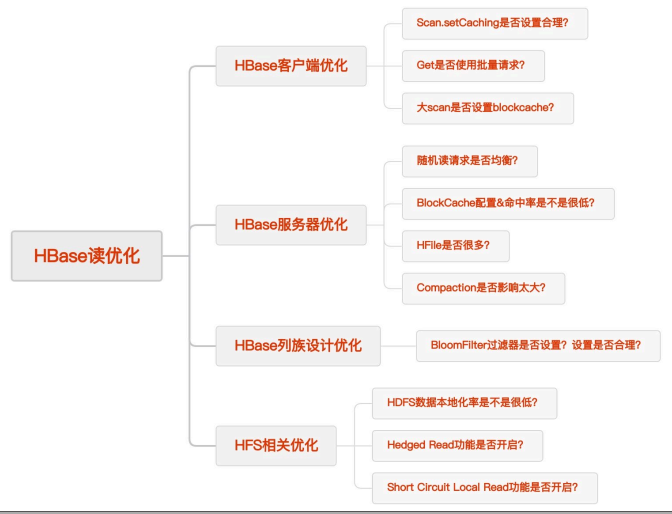
存储调优(HDFS)
- Linux系统参数(网络,内存,IO)
- Short-Circuit Read
- Data Locality
表结构调优
- Row Key设计
- 列族设计
HBase RIT
Region-In-Trasition 是 Hbase 的一种变迁机制
RIT 问题 : Region 进行变迁 ( merge、split、assign、unssign ) 时,导致 Region 的状态一直是 RIT, Hbase 出现异常
Hbase Table 进入RIT 解决方法:
- 当在 Hbase webui 看到某个表某个 Regin 进入 RIT 时,可以重启该 Regin 所在节点进行恢复
- 停止 Hbase 集群删除 zk 上
/hbase节点,重启集群进行恢复 - 重启不能恢复时,就查看 Hbase 日志,检查 hdfs 文件是否异常,修复 hdfs 文件异常,通过
hbase hbck进行修复 - ReginServer 内存太小也会导致 Table 进入RIT,加大 ReginServer 内存解决
- 暴力删除异常 Table 或 Table 部分受损的数据分区,通过删除 hdfs 上 /hbase 下的目录文件,修复 HbaseMeta,会丢失数据
HBase 的高可用性和灾备
HLog
HBase 采用类 LSM 的架构体系,数据写入并没有直接写入数据文件,而是会先写入缓存(MemStore),在满足一定条件下缓存数据再会异步刷新到硬盘
为了防止数据写入缓存之后 , 因为 Region Server 进程发生异常 , 导致数据丢失,在写入缓存之前 , 会首先将数据顺序写入 HLog 中。当Region Server 宕机时,就会从 HLog 中进行日志回放来数据补救,保证数据不丢失
Hlog 结构
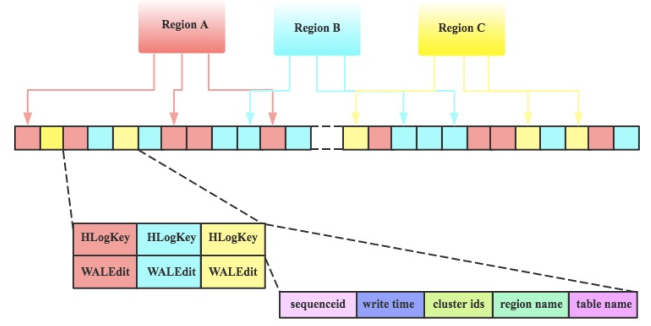
WAL 的实现类为 HLog,每个 Region Server 拥有一个 HLog 日志,所有 Region 的写入都是写到同一个 HLog
同一个 Region Server 中的 3 个 Region 共享一个 HLog
当数据写入时,是将数据对 <HLogKey,WALEdit> 按照顺序追加到 HLog 中,提高写入性能
Region Server 故障恢复
发现:
HBase通过 Zookeeper 检测宕机, 正常时 RegionServer 会周期性向 Zookeeper 发送心跳,一旦发生宕机,心跳就会停止,超过一定时间( SessionTimeout ), Zookeeper 就会认为 RegionServer 宕机离线,并把该消息通知给 Master
HLog切分:
一台 Region Server 只有一个 HLog 文件 ( 所有 Region 的日志都混合写入该 HLog ),而回放日志是以 Region 为单元进行的,所以在回放之前首先将 HLog 按照 Region 进行分组,该分组的过程为 : HLog 切分
HLog回放:
重新回放 HLog,写入 MemStore ,也就是 HBase 写入的过程

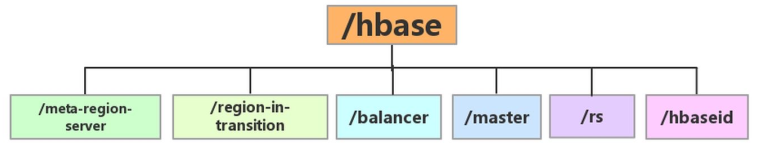
HMaster HA
HMaster 是有 HA ( 主备模式 )。同一时间只有一个 HMaster 能成功在 Zookeeper 中注册 /hbase/master 节点,成为 Active 提供服务
因为每台 HMaster 都和 Zookeeper 之间存在着心跳保持,当 Active HMaster 发生故障时,Zookeeper 中的 /hbase/master 节点自动删除,此时其他 HMaster 如果成功注册该节点,就成为新的 Active 。成为 Active 的 HMaster 需要从 Zookeeper 中加载完相应的数据到内存,就可以提供服务
Hbase 2.x
Hbase 2,核心功能 :
- Read HA
- In-memory compaction
- OffHeap 读写
HBase Read HA
Region 不只保存在某一单独的 Region Server 上,而是选择其他的两个 Region Server 分别存储该 Region 的两个备份,当某台 Region Server 挂掉时,客户端仍然能从其它 Region Server 上备份的 Region 中读到数据,这样就能保证 HBase 的读高可用,可用性达到了 99.99%
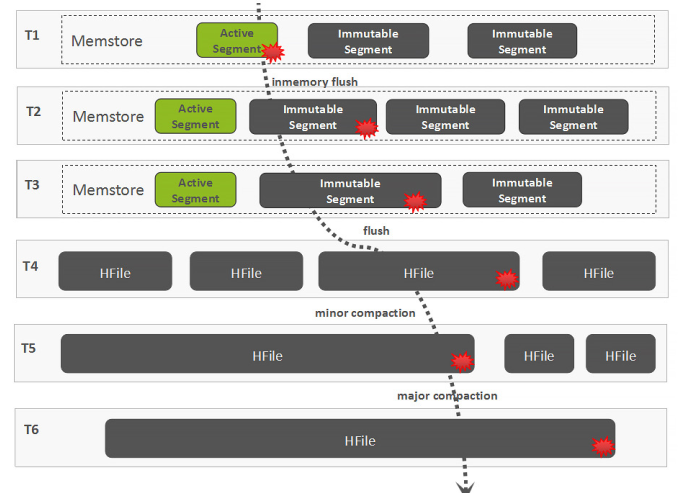
In-Memory Compaction
In-Memory Compaction : 通过在内存中引入 LSM 结构,减少多余数据,实现降低 flush 频率和减小写放大的效果
MemStore 的数据先 Flush 成一个 Immutable 的 Segment,多个 Immutable Segments 能在内存中进行 Compaction ,当达到一定阈值时 , 就会把内存中的数据持久化成 HDFS 中的 HFile 文件
OffHeap读写
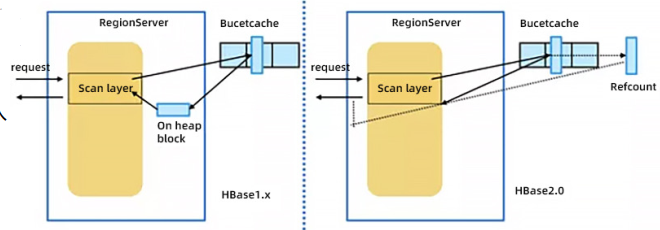
HBase 服务读写数据 , 比较依赖堆内内存实现,JVM 采用的是 stop-the-world 进行垃圾回收,很容易造成 JVM 进程因为 GC 而停顿时间比较长 , HBase 是一个低延迟、对响应性要求比较高的系统,GC 很容易造成 HBase 服务抖动、延迟高
HBase 社区解决 GC 延迟的思路 : 尽量减少使用 JVM 堆内内存,堆内内存使用减少,GC 也就随着减少了,为此支持了读写链路 offheap
读链路的 offheap :
- 对 BucketCache 引用计数,避免读取时的拷贝
- 服务端 通过 ByteBuffer 实现 KeyValue ,让 KeyValue 存储在 offheap 的内存中写链路的 offheap
- 在 RPC 层直接把网络流上的 KeyValue 读入 offheap 的 bytebuffer 中
- 使用 offheap 的 MSLAB pool
- 使用支持 offheap 的 Protobuf
HBase的不足
分布式事务:每个事务都遵循事务的 ACID 原则,但 HBase 无法支持,它只能执行单行事务,一行数据中包含多个列(column),一个事务中可以操作同一行中的多个列
强一致性数据同步:如 : A 要求 B 和 C 分别对数据进行运算,就必须在 B 和 C 无异常时 , 才可进行,当一个拒绝,则整个事务就没法进行,得不到结果 , 也就是事务被取消,资源得不到更新
全球负载均衡:
- 存储负载(存储空间全球数据中心共享)
- 调度负载(在全球数据中心内平衡 CPU / MEM 利用)
- 网络负载(在全球数据中心内平衡网络流量)
- 距离负载(让数据紧贴应用进行全球移动)
ACID : 数据库事务正确执行的四个基本要素的缩写 :
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)

若有收获,就点个赞吧
0 人点赞
