引言 在最近使用Flask-SQLAlchemy的过程中,遇到了几个新问题及对应的解决方法,如下所示:
- 【问题1】怎么实现“动态查询”
- 【方案】请求参数改写为kwargs形式**。
- 【问题2】怎么实现“动态查询数据的序列化输出”
- 【方案】借助“ flask_marshmallow”进行实现。
1.动态查询
在Flask-SQLAlchemy中,我们可以将“请求参数改写为kwargs形式”,例如:“resID = db.session.query(Plan).filter_by(**requestBody**).all() ”,具体实现如下所示:
@planApp.post("/select")@check_login_status # 定义:检查token的装饰器def selectPlan():traceId = traceID()requestBody = request.get_json()print("requestBody:\t", requestBody)resID = db.session.query(Plan).filter_by(**requestBody).all() # 实现动态查询的核心代码print("【原始结果】 resID:\t", resID)resCount = db.session.query(Plan).filter_by(**requestBody).count()print("表数据\t", resID)print("表数据resCount\t", resCount)if resCount > 0:# 多个数据结果的组装plan_schema = PlanSchema() #plan_data = {"data": []}for x in range(resCount):# 进行字典拼接操作plan_data["data"] = plan_data["data"] + [plan_schema.dump(resID[x])]# print("表数据res=\t", plan_data)print("plan_data-type=\t", type(plan_data))print("最终-表数据res=\t", plan_data)msg = {"code": 0, "msg": "查询成功", "traceId": traceId, "success": True, "data": plan_data,"errorMessage": "成功"}# msg.update(data)return jsonify(msg), 200else:plan_data = {"code": 501, "msg": "查询失败", "traceId": traceId}return jsonify(plan_data), 500
2.动态查询结果的序列化
1.未进行序列化操作
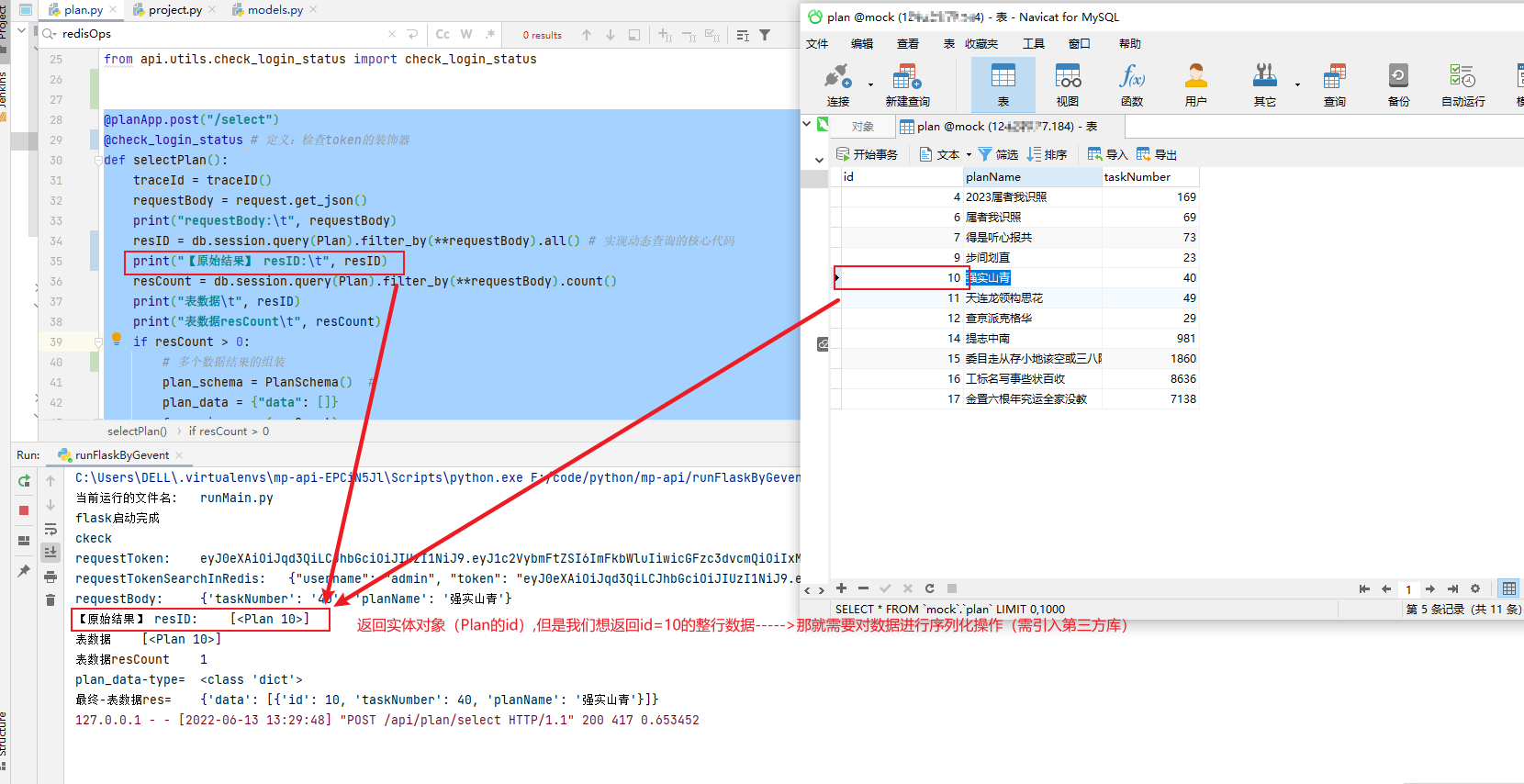
在Flask-SQLAlchemy的”db.session.qurey()”通常会返回“实体对象(即(理解为)查询结果的id)”,如下图所示
@planApp.post("/select")@check_login_status # 定义:检查token的装饰器def selectPlan():traceId = traceID()requestBody = request.get_json()print("requestBody:\t", requestBody)resID = db.session.query(Plan).filter_by(**requestBody).all() # 实现动态查询的核心代码print("【原始结果】 resID:\t", resID)#非核心代码省略
2.进行序列化操作
1.操作步骤流程
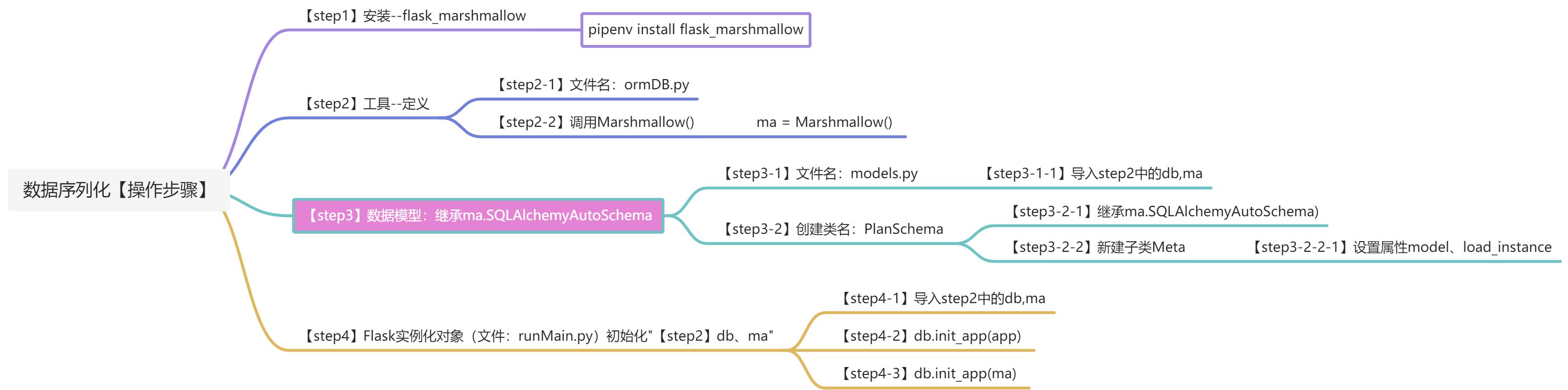
2.具体实现
1.安装flask_marshmallow
pipenv install flask_marshmallow
2.【自定义—工具】ormDB.py
说明:笔者自定义一个工具,并命名为ormDB.py。
from flask_sqlalchemy import SQLAlchemyfrom flask_marshmallow import Marshmallowdb = SQLAlchemy()ma = Marshmallow()
3.【核心】【自定义—数据模型Model】models.py
说明:笔者自定义一个py文件【命名:models.py】,用于定义Flask-SQLAlchemy中的数据模型及数据序列化展示/输出。
from utils.ormDB import db, ma # 导入自定义的[ormDB]ma、db# 定义数据模型class Plan(db.Model):__tablename__ = 'plan' # 设置表名, 表名默认为类名小写id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 设置主键, 默认自增planName = db.Column(db.String(20), nullable=False) # 设置字段名 和 不为空taskNumber = db.Column(db.Integer, default=10, nullable=False) # 设置默认值# 【数据序列化】数据转dict#PlanSchema:集成ma.SQLAlchemyAutoSchemaclass PlanSchema(ma.SQLAlchemyAutoSchema):# 子类Meta:设置属性model、load_instance的valueclass Meta:model = Planload_instance = True
4.Flask实例化对象—初始化db、ma
说明:笔者的“.Flask实例化对象存在于自定义的runMain.py中”。
import resource.flaskConfig as FlaskConfig # 导入flask的配置文件,并设置别名:FlaskConfigfrom flask import Flask, make_response, current_app, request, jsonifyfrom flask_cors import CORSfrom resource.blueprintConfig import bpConfig# 【start-工具utils】from utils.logUtils import logUtils # 【导入】日志工具-函数from utils.optUtils import traceID # 【导入】uuid工具-函数from utils.responseUtil import responseUtilfrom utils.optUtils import getPyFileName,getFunctonName# 【start-工具utils】from apiflask import APIFlaskimport jsonfrom utils.ormDB import db, maapp = Flask(__name__) # 实例化Flask对象# app = APIFlask(__name__)CORS(app) # 解决跨域bpConfig(app) # Flask蓝图配置app.config.update(RESTFUL_JSON=dict(ensure_ascii=False)) # 加载Flask配置app.config.from_object(FlaskConfig) # 加载flask的配置文件# 【核心代码】【使用/绑定】日志工具函数logUtils(app)db.init_app(app) # [初始化] db对象ma.init_app(app) # [初始化] ma对象
3.验证
1.被验证的接口
我们选择“已实现Flask-SQLAlchemy动态查询”的接口:“xxx/plan/select”
@planApp.post("/select")@check_login_status # 定义:检查token的装饰器def selectPlan():traceId = traceID()requestBody = request.get_json()print("requestBody:\t", requestBody)resID = db.session.query(Plan).filter_by(**requestBody).all() # 实现动态查询的核心代码print("【原始结果】 resID:\t", resID)resCount = db.session.query(Plan).filter_by(**requestBody).count()print("表数据\t", resID)print("表数据resCount\t", resCount)if resCount > 0:# 多个数据结果的组装plan_schema = PlanSchema() #plan_data = {"data": []}for x in range(resCount):# 进行字典拼接操作plan_data["data"] = plan_data["data"] + [plan_schema.dump(resID[x])]# print("表数据res=\t", plan_data)print("plan_data-type=\t", type(plan_data))print("最终-表数据res=\t", plan_data)msg = {"code": 0, "msg": "查询成功", "traceId": traceId, "success": True, "data": plan_data,"errorMessage": "成功"}# msg.update(data)return jsonify(msg), 200else:plan_data = {"code": 501, "msg": "查询失败", "traceId": traceId}return jsonify(plan_data), 500
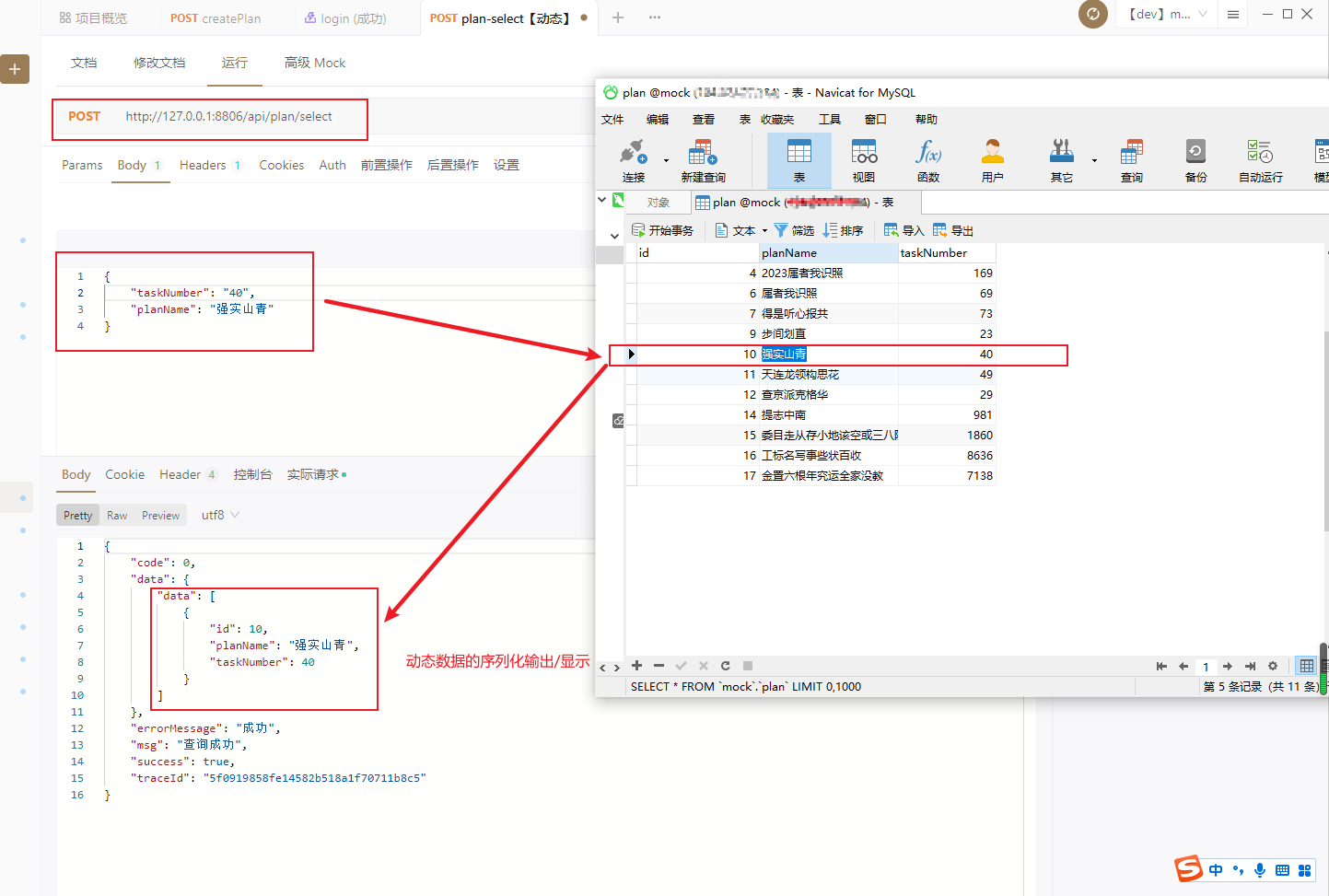
2.apifox请求验证
说明:如下图所示,则表示“动态查询结果数据序列化输出/显示—->成功、通过”
学习资料 《Flask之SQLAlchemy操作》 https://www.csdn.net/tags/Ntzacg5sOTMxNDktYmxvZwO0O0OO0O0O.html

若有收获,就点个赞吧
0 人点赞
