ThingsBoard rule engine supports basic analysis of incoming telemetry data, for example, threshold crossing. The idea behind rule engine is to provide functionality to route data from IoT Devices to different plugins, based on device attributes or the data itself.
However, most of the real-life use cases also require the support of advanced analytics: machine learning, predictive analytics, etc.
This tutorial will demonstrate how you can:
- route telemetry device data from ThingsBoard to Kafka topic using the built-in rule engine capabilities (works for both ThingsBoard CE and PE).
- aggregate data from multiple devices using a simple Kafka Streams application.
- push results of the analytics back to ThingsBoard for persistence and visualization using ThingsBoard PE Kafka Integration.
The analytics in this tutorial is, of course, quite simple, but our goal is to highlight the integration steps.
Let’s assume we have a large number of solar panels which include a number of solar modules. ThingsBoard is used to collect, store and visualize anomaly telemetry from these solar modules in each panels.
We calculated anomaly by comparing value produced from a solar module with the average valued produced by all modules of the same panel and standard deviation of the same value.
We will analyze real-time data from multiple devices using Kafka Streams job with 30 seconds window (configurable).
In order to store and visualize the results of the analytics, we are going to create three virtual solar module devices for each solar panel.
Prerequisites
The following services must be up and running:
- ThingsBoard PE v2.4.2+ instance
Kafka server
Step 1. Rule Chain configuration
During this step we will configure three generator nodes that will produce simulated data for testing during development. Typically, you don’t need them in production, but it is very useful for debugging. We will generate data for 3 modules and one panel. Two of those modules will produce the same value and one module will produce much lower value. Of course, you should replace this with real data produced by real devices. This is just an example.
Let’s create three devices with type “solar-module”. If you are using ThingsBoard PE, you cna put them to new “Solar Modules” group.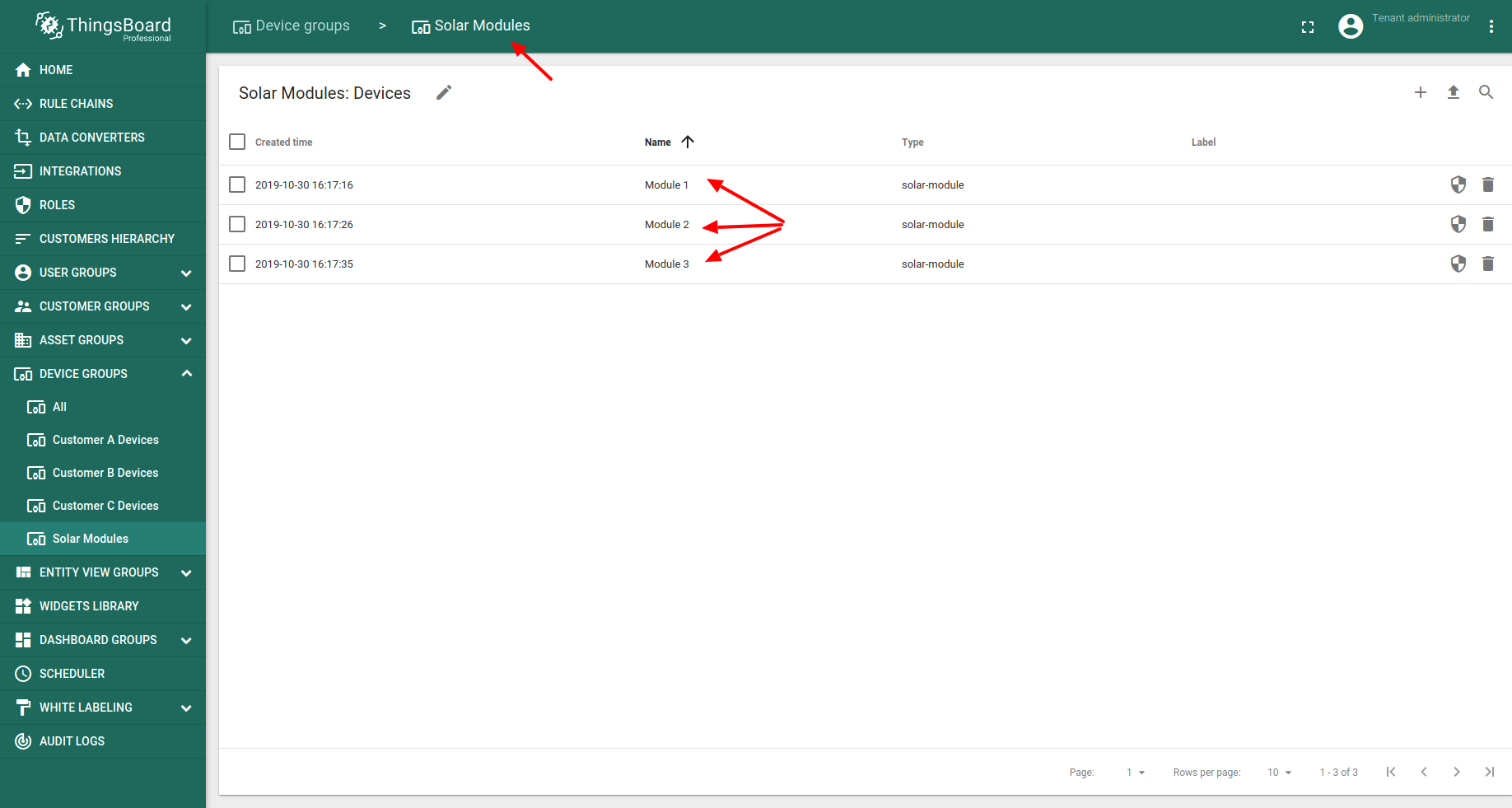
Now, let’s create three device simulators to push data directly to our local Kafka broker. The simulated data will be pushed to the Kafka Rule Node, which is responsible for pushing data to Kafka topic. Let’s configure Kafka Rule Node first. We will use local Kafka server (localhost:9092) and topic “solar-module-raw”.
Now, let’s add “generator” node for the first module. We will configure generator to constantly “produce” 5 watts.
Add “generator” node for the second module. We will configure generator to constantly “produce” 5 watts as well.
Now, let’s add “generator” node for the third module. We will configure generator to constantly “produce” 3.5 watts which simulates module degradation.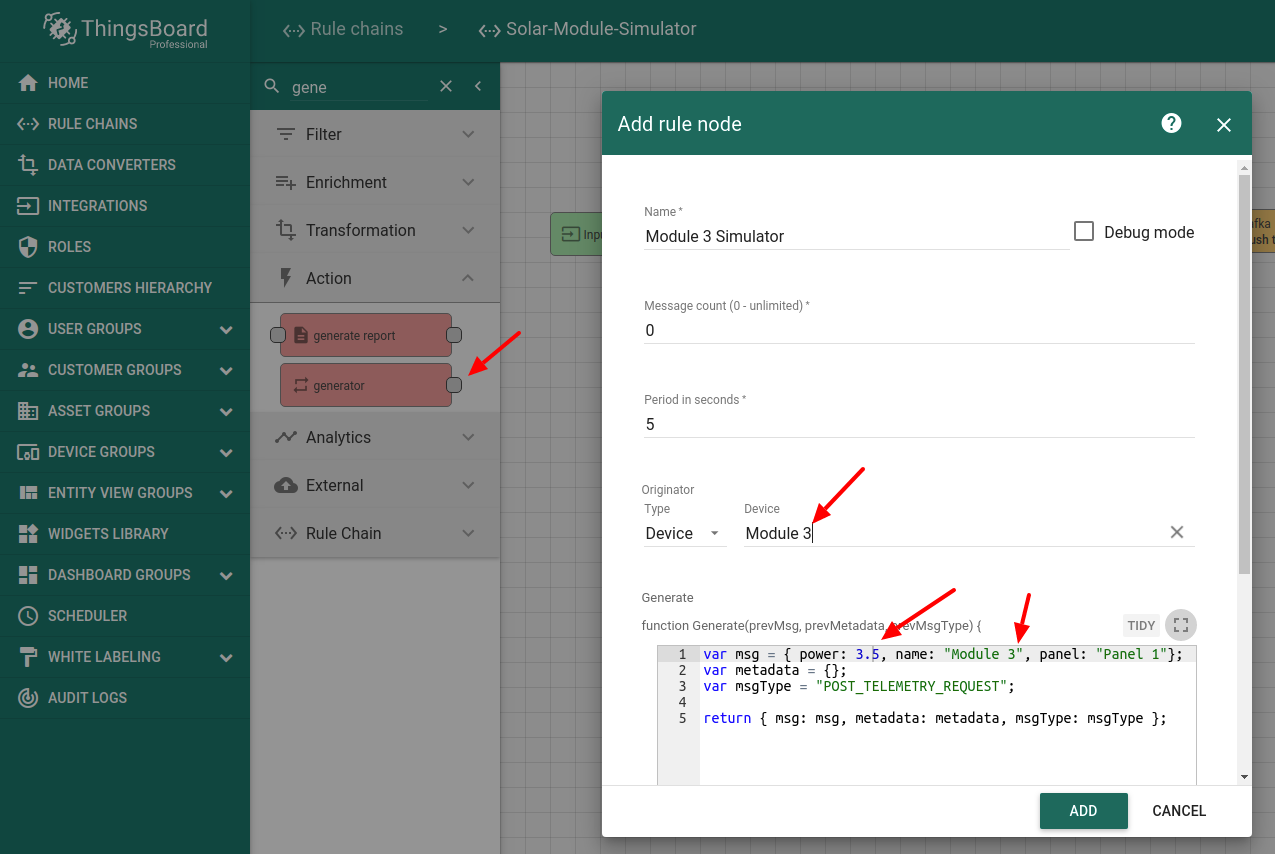
The result rule chain should look similar to this one:
You can also download the rule chain JSON file and import it to your project.
Once the rule chain is imported, you should check the debug output of the Kafka node. If your Kafka is up and running at localhost, you should see similar debug messages. Notice the absence of errors in debug log: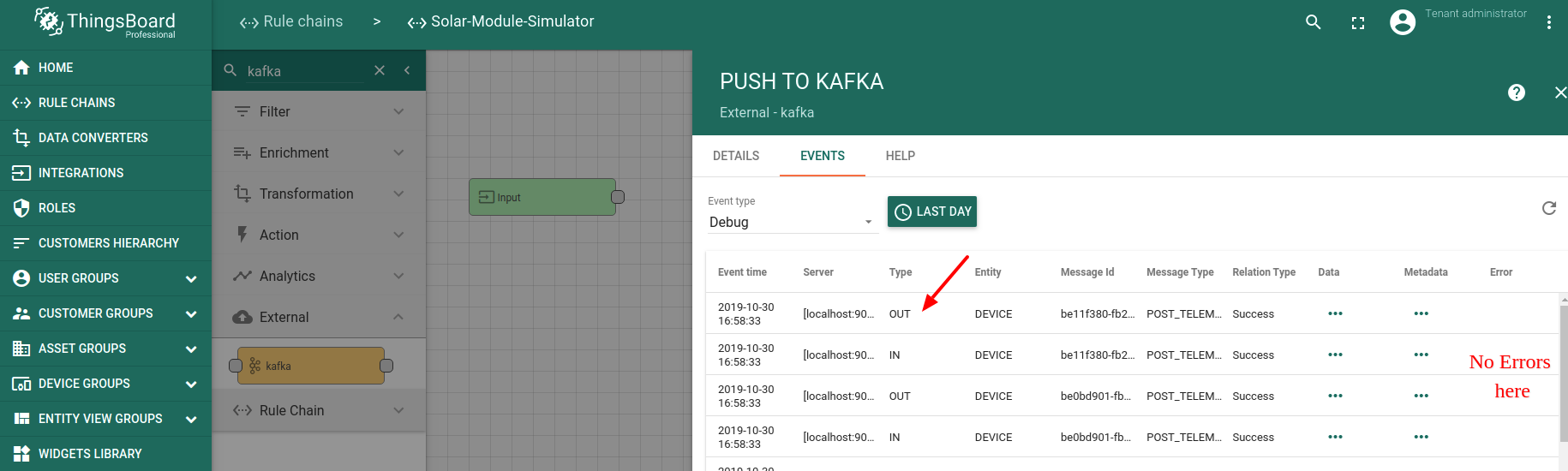
Step 2. Launch Kafka Streams application.
During this step we will download and launch sample application that analyze raw data from “solar-module-raw” and produce valuable insights about module degradations. The sample application calculates total amount of energy produced by each module in the panel within the time window (configurable). Then application calculates average power produced by module for each panel and it’s deviation within the same time window. Once this is done, the app compares each module values with the average and if the difference is bigger then the deviation, we treat this as anomaly.
The results of anomaly calculations are pushed to the “anomalies-topic”. ThingsBoard subscribed to this topic using Kafka Integration, generate alarms and store anomalies to the database.Download the sample application
Feel free to grab the code from the ThingsBoard repository and build the project with maven:
mvn clean install
Go ahead and add that maven project to your favorite IDE.
Dependencies review
Main dependencies that are used in the project:
<dependencies>...<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>${kafka.version}</version></dependency>...</dependencies>
Source code review
The Kafka Streams Application logic is concentrated mainly in the SolarConsumer class.
private static Properties getProperties() {final Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");return props;}
private static final String IN_TOPIC = "solar-module-raw";private static final TopicNameExtractor<String, SolarModuleAggregatorJoiner> OUT_TOPIC =new StaticTopicNameExtractor<>("solar-module-anomalies");// Time for windowingprivate static final Duration DURATION = Duration.ofSeconds(30);private static final TimeWindows TIME_WINDOWS = TimeWindows.of(DURATION);private static final JoinWindows JOIN_WINDOWS = JoinWindows.of(DURATION);private static final StreamsBuilder builder = new StreamsBuilder();// serde - Serializer/Deserializer// for custom classes should be custom Serializer/Deserializerprivate static final Serde<SolarModuleData> SOLAR_MODULE_DATA_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleData.class));private static final Serde<SolarModuleAggregator> SOLAR_MODULE_AGGREGATOR_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleAggregator.class));private static final Serde<SolarPanelAggregator> SOLAR_PANEL_AGGREGATOR_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarPanelAggregator.class));private static final Serde<SolarModuleKey> SOLAR_MODULE_KEY_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleKey.class));private static final Serde<SolarPanelAggregatorJoiner> SOLAR_PANEL_AGGREGATOR_JOINER_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarPanelAggregatorJoiner.class));private static final Serde<SolarModuleAggregatorJoiner> SOLAR_MODULE_AGGREGATOR_JOINER_SERDE =Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleAggregatorJoiner.class));private static final Serde<String> STRING_SERDE = Serdes.String();private static final Serde<Windowed<String>> WINDOWED_STRING_SERDE = Serdes.serdeFrom(new TimeWindowedSerializer<>(STRING_SERDE.serializer()),new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TIME_WINDOWS.size()));// 1 - sigmaprivate static final double Z = 1;
// source stream from kafkafinal KStream<SolarModuleKey, SolarModuleData> source =builder.stream(IN_TOPIC, Consumed.with(STRING_SERDE, SOLAR_MODULE_DATA_SERDE)).map((k, v) -> KeyValue.pair(new SolarModuleKey(v.getPanel(), v.getName()), v));// calculating sum power and average power for modulesfinal KStream<Windowed<SolarModuleKey>, SolarModuleAggregator> aggPowerPerSolarModuleStream =source.groupByKey(Grouped.with(SOLAR_MODULE_KEY_SERDE, SOLAR_MODULE_DATA_SERDE)).windowedBy(TIME_WINDOWS).aggregate(SolarModuleAggregator::new,(modelKey, value, aggregation) -> aggregation.updateFrom(value),Materialized.with(SOLAR_MODULE_KEY_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE)).suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded())).toStream();// calculating sum power and average power for panelsfinal KStream<Windowed<String>, SolarPanelAggregator> aggPowerPerSolarPanelStream =aggPowerPerSolarModuleStream.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v)).groupByKey(Grouped.with(WINDOWED_STRING_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE)).aggregate(SolarPanelAggregator::new,(panelKey, value, aggregation) -> aggregation.updateFrom(value),Materialized.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE)).suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded())).toStream();// if used for join more than once, the exception "TopologyException: Invalid topology:" will be thrownfinal KStream<Windowed<String>, SolarModuleAggregator> aggPowerPerSolarModuleForJoinStream =aggPowerPerSolarModuleStream.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v));// joining aggregated panels with aggregated modules// need for calculating sumSquare and deviancefinal KStream<Windowed<String>, SolarPanelAggregatorJoiner> joinedAggPanelWithAggModule =aggPowerPerSolarPanelStream.join(aggPowerPerSolarModuleForJoinStream,SolarPanelAggregatorJoiner::new, JOIN_WINDOWS,Joined.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE));//calculating sumSquare and deviancefinal KStream<Windowed<String>, SolarPanelAggregator> aggPowerPerSolarPanelFinalStream =joinedAggPanelWithAggModule.groupByKey(Grouped.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_JOINER_SERDE)).aggregate(SolarPanelAggregator::new,(key, value, aggregation) -> aggregation.updateFrom(value),Materialized.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE)).suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded())).toStream();// joining aggregated modules with aggregated panels in which calculated sumSquare and deviance// need for check modules with anomaly power valuefinal KStream<Windowed<String>, SolarModuleAggregatorJoiner> joinedAggModuleWithAggPanel =aggPowerPerSolarModuleStream.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v)).join(aggPowerPerSolarPanelFinalStream,SolarModuleAggregatorJoiner::new, JOIN_WINDOWS,Joined.with(WINDOWED_STRING_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE));// streaming result data (modules with anomaly power value)joinedAggModuleWithAggPanel.filter((k, v) -> isAnomalyModule(v)).map((k, v) -> KeyValue.pair(k.key(), v)).to(OUT_TOPIC, Produced.valueSerde(SOLAR_MODULE_AGGREGATOR_JOINER_SERDE));// starting streamsfinal KafkaStreams streams = new KafkaStreams(builder.build(), getProperties());streams.cleanUp();streams.start();Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
Calculating anomaly data
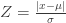
private static boolean isAnomalyModule(SolarModuleAggregatorJoiner module) {double currentZ = Math.abs(module.getSumPower() - module.getSolarPanelAggregator().getAvgPower()) / module.getSolarPanelAggregator().getDeviance();return currentZ > Z;}
Sample application output
...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 1]: 30.0:6...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 2]: 30.0:6...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 3]: 21.0:6...SolarConsumer - PerSolarPanel: [1572447690|Panel 1]: 81.0:3...SolarConsumer - PerSolarPanelFinal: [1572447660|Panel 1]: power:81.0 count:3 squareSum:54.0 variance:18.0 deviance:4.2...SolarConsumer - ANOMALY module: [1572447660|Panel 1|Module 3]: sumPower:21.0 panelAvg:27.0 deviance:4.2
Step 3. Configure the Kafka Integration.
Let’s configure ThingsBoard to subscribe to the “solar-module-anomalies” topic and create alarms. We will use Kafka Integration that is available since ThingsBoard v2.4.2.
Configure Uplink Converter
Before setting up a Kafka integration, you need to create the Uplink data converter. The uplink data converter is responsible for parsing the incoming anomalies data.
Example of the incoming message that is produced by our Kafka Streams application:{"moduleName": "Module 3","panelName": "Panel 1","count": 6,"sumPower": 21.0,"avgPower": 3.5,"solarPanelAggregator": {"panelName": "Panel 1","count": 3,"sumPower": 81.0,"avgPower": 27.0,"squaresSum": 54.0,"variance": 18.0,"deviance": 4.2}}
See the following script that is pasted to the Decoder function section:
// Decode an uplink message from a buffer// payload - array of bytes// metadata - key/value object/** Decoder **/// decode payload to stringvar msg = decodeToJson(payload);// decode payload to JSON// var data = decodeToJson(payload);var deviceName = msg.moduleName;var deviceType = 'module';// Result object with device attributes/telemetry datavar result = {deviceName: deviceName,deviceType: deviceType,attributes: {panel: msg.panelName},telemetry: {avgPower: msg.avgPower,sumPower: msg.sumPower,avgPowerFromPanel: msg.solarPanelAggregator.avgPower,deviance: msg.solarPanelAggregator.deviance}};/** Helper functions **/function decodeToString(payload) {return String.fromCharCode.apply(String, payload);}function decodeToJson(payload) {// covert payload to string.var str = decodeToString(payload);// parse string to JSONvar data = JSON.parse(str);return data;}return result;

The purpose of the decoder function is to parse the incoming data and metadata to a format that ThingsBoard can consume. deviceName and deviceType are required, while attributes and telemetry are optional. Attributes and telemetry are flat key-value objects. Nested objects are not supported.
Configure Kafka Integration
Let’s create kafka integration that will subscribe to “solar-module-anomalies” topic.

Step 4. Configure Rule Engine to raise Alarms.
Follow existing “Create and Clear Alarms” guide to raise the alarm based on the “anomaly” boolean flag in the incoming telemetry and use “Send email on alarm” guide to send email notifications. Explore other guides to learn mode.
Step 5. Remove debug messages logging
Although the Debug mode is very useful for development and troubleshooting, leaving it enabled in production mode may tremendously increase the disk space, used by the database, because all the debugging data is stored there. It is highly recommended to turn the Debug mode off when done debugging.
Next steps
Getting started guides - These guides provide quick overview of main ThingsBoard features. Designed to be completed in 15-30 minutes.
- Installation guides - Learn how to setup ThingsBoard on various available operating systems.
- Data visualization - These guides contain instructions how to configure complex ThingsBoard dashboards.
- Data processing & actions - Learn how to use ThingsBoard Rule Engine.
- IoT Data analytics - Learn how to use rule engine to perform basic analytics tasks.
- Hardware samples - Learn how to connect various hardware platforms to ThingsBoard.
- Advanced features - Learn about advanced ThingsBoard features.
- Contribution and Development - Learn about contribution and development in ThingsBoard.

若有收获,就点个赞吧
0 人点赞
