事实上,Skip-gram模型与CBOW模型是刚好相反的,CBOW模型是根据某个词上下文的词去预测这个词,而Skip-gram模型是通过某个词去预测其上下文的词。
我们首先需要有一个滑动窗口,滑动窗口大小可以设置,一般为2,对某个句子进行滑动取样本。从这句话的第一个字开始取,这个字后面的两个字将会是标签,即是我们需要预测的值,接下来对于每个字都是一样。
Skip-gram共分为三层,就如CBOW模型一样,实质有权重的也就只有两层。
- 第一层是输入层,Skip-gram模型的输入层是一个向量,这个向量是一个one_hot编码后的向量,设这个词向量的维度为1*10000,因为我们之前提到过,Skip-gram模型就是通过一个词来预测其上下文的词的,因此输入层仅仅有这一个词向量的输入。
- 第二层是隐藏层,隐藏层实质上不能称之为隐藏层,因为它没有做激活函数的变换,它只是做了一个权重与输入层的点积,设权重的维度大小为10000300,意味着隐藏层有着三百个神经元,经过隐藏层后,得到了一个1300的向量,就如CBOW所提到的,我们原来的带有one_hot编码的词向量与权重点积后,得到了我们想要的词嵌入,即word embedding,词嵌入的意思就是由本身的维度冗余的词向量,转化为一个精简的与权重大小有关的词向量,那个权重就被称为look up table。
- 第三层是输出层。最后词嵌入进入到输出层中,经历一个softmax变换,这里需要提出的是,我们不会像之前一样输出10000个维度的概率值,我们只会输出概率值最大的值。因此我们的输入层是一个向量,输出层是几个词的值分布,由于softmax的scaler作用,这些词加起来为1。
最后我们需要拿输出层的这几个值分布和输入的词的上下文(也就是真实的标签)进行比较,得到loss损失,然后多次迭代,用梯度下降法更新W和W’,使loss损失尽可能地小。这就是Skip-gram的整个过程。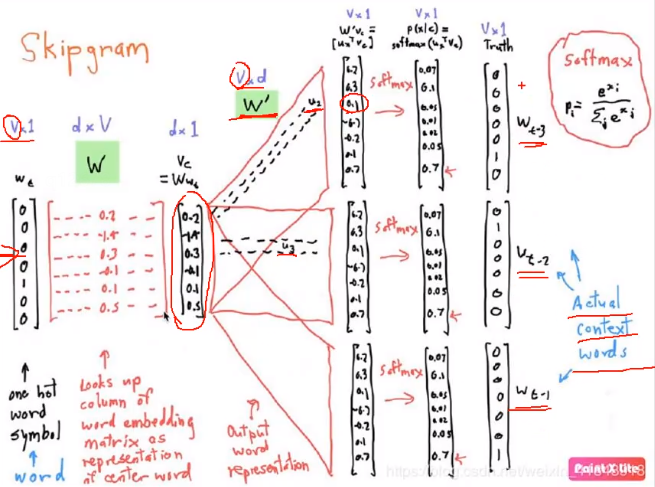

若有收获,就点个赞吧
0 人点赞
