Introduction
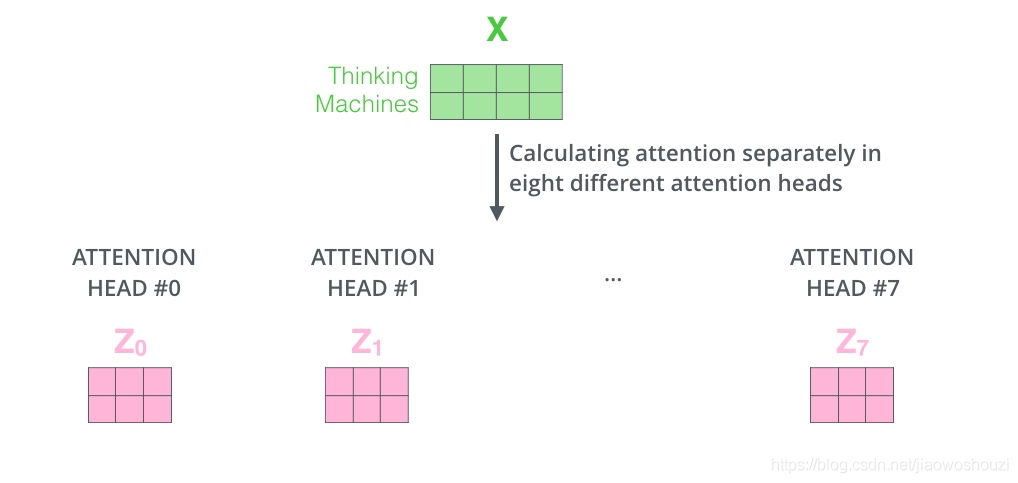
Multi-head attention事实上很容易理解,就是将我们之前提到的self-attention过程复制n次,但是是并行的。
Approach
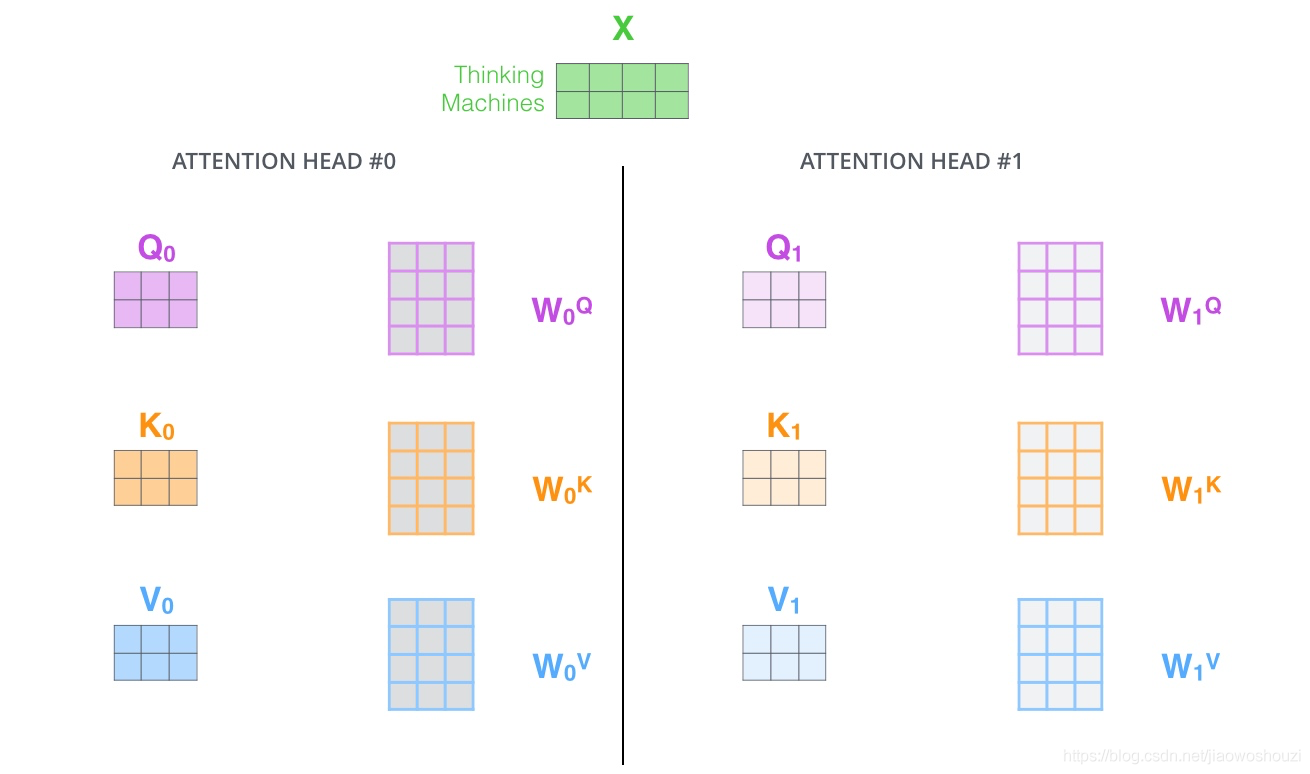
Multi-head attention整个过程如下:我们之前已经讲过Queriers,Keys和Values是怎么来的了,这里就不多做介绍了。唯一需要提到的是,上篇文章说的过程要做h次,这也就是所谓的多头的意思,每一次都算做一个头,而且每次Q,K,V进行线性变换的参数W是不一样的,我们把求出来的结果进行拼接,接下来会有所不同,我们需要把拼接得到的矩阵与一个W矩阵进行点积,然后才能得到最后的结果,也就是self-attention层的输出。

Summary
多头注意力机制主要目的是将解码器和编码器来进行翻译对齐。在编码器和解码器中都使用了multi-head self-attention来学习文本的表示。Self-attention中K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。在Self-Attention机制中,相比于单头,多头注意力机制可以更好地找寻句子内部的结构关系,从而捕捉到更多的结构信息,事实上在Transformer中也是这么做的。

若有收获,就点个赞吧
0 人点赞
