Introduction
提到Transformer就不得不提到《Attention is all you need》这篇论文。这篇论文是google机器翻译团队在2017年6月放在arXiv上,最后发表在2017年nips上。Transformer提出了一个观点,那就是用Attention机制代替了原来encoder和decoder中的RNN网络,这算是一次革新,因为其抛弃了RNN和CNN算法,转而用Attention机制来完成整个过程,下面一起来分析一下。
Architecture
我们先得了解一下整个构架是怎样的,论文中的构架如下图所示。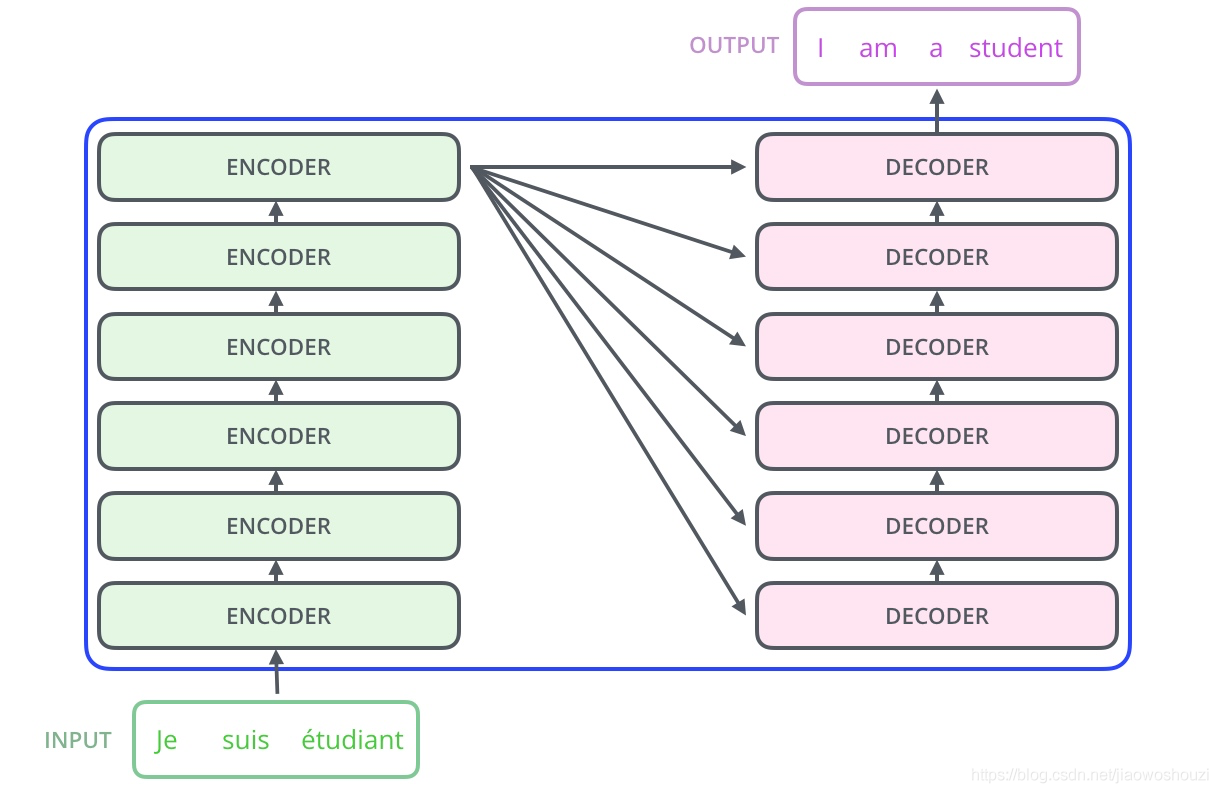
这个图就是我们的transformer框架了,可以看到,transformer框架也是由encoder和decoder组成的。但是相比于Seq to Seq,Transformer主要做了两点改进:
- 整体结构上我们采用了encoder和decoder堆叠的方式,相比于Seq to Seq,可以进行更多层的非线性变换。
- 内部结构的不同,在Seq to Seq模型中,encoder和decoder内部是LSTM序列模型。
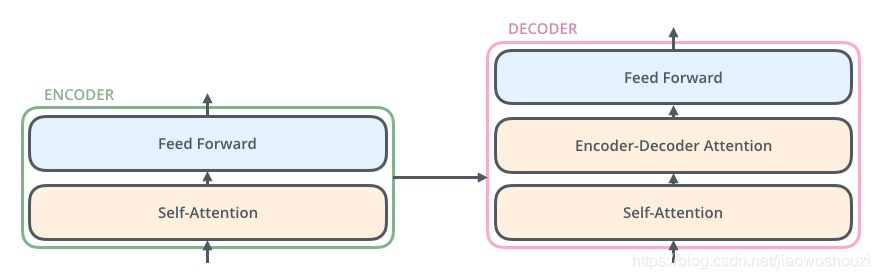 在Transformer模型中,每个encoder和decoder的结构是如上图所示的。encoder中包含了一个自注意层和一个前向反馈层,decoder中包含了一个自注意层,一个Encoder-Decoder注意层,还有一个前向反馈层。在这之前,我们首先需要来聊一聊Self-Attention。事实上,Self-Attention的原理和Encoder-Decoder Attention是一样的,只是Self-Attention是对自己序列本身引入Attention机制。
在Transformer模型中,每个encoder和decoder的结构是如上图所示的。encoder中包含了一个自注意层和一个前向反馈层,decoder中包含了一个自注意层,一个Encoder-Decoder注意层,还有一个前向反馈层。在这之前,我们首先需要来聊一聊Self-Attention。事实上,Self-Attention的原理和Encoder-Decoder Attention是一样的,只是Self-Attention是对自己序列本身引入Attention机制。
Self Attention
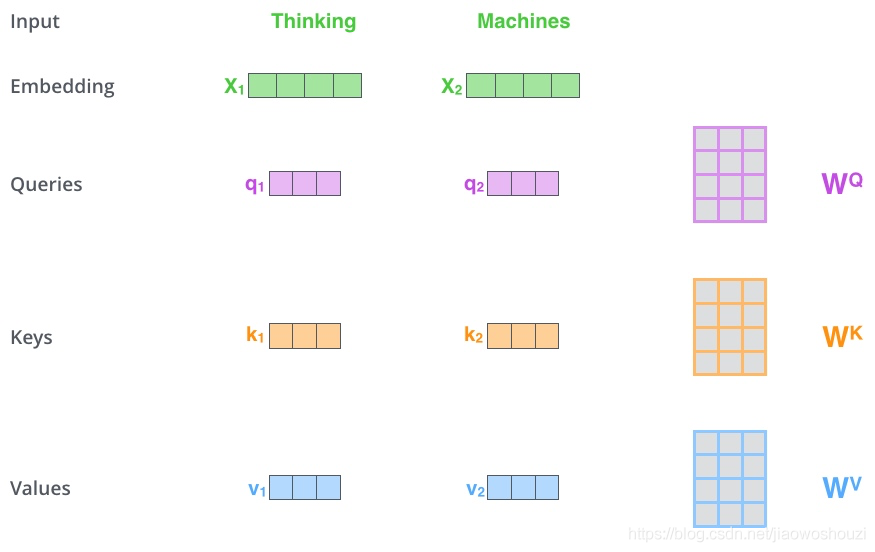 我们还是需要看图说话。上图是论文中的Self-Attention机制的流程图。首先我们需要向Self-Attention层输入数据,但事实上,在此之前我们需要对序列中的词做一些变换。首先当然是要进行Word2Vec变换,将词文本转化为词向量(word to vector),之后我们还需要做一次词嵌入(word embedding),这是之前提到过的,在这里就无需赘述了。我们将做完词嵌入后的数据输入到Self-Attention层中,接下来有一个很棒的小技巧,那就是我们将用三个不同权重的矩阵与词嵌入向量进行点积运算,然后我们会得到三个向量,第一个是Queries向量,第二个是Keys向量,第三个是Values向量。可能会纳闷,这三个不同的向量各自有什么作用呢。正如其名字一样,Queries向量是负责询问的,还记得我们在带有Attention机制的Seq to Seq模型中所讲的内容吗。我们用解码端的hti挨个去与编码端的hs求分数,事实上这就是一个Queries的过程,那么显而易见,这些编码端的hs就是我们的Keys。如下图。
我们还是需要看图说话。上图是论文中的Self-Attention机制的流程图。首先我们需要向Self-Attention层输入数据,但事实上,在此之前我们需要对序列中的词做一些变换。首先当然是要进行Word2Vec变换,将词文本转化为词向量(word to vector),之后我们还需要做一次词嵌入(word embedding),这是之前提到过的,在这里就无需赘述了。我们将做完词嵌入后的数据输入到Self-Attention层中,接下来有一个很棒的小技巧,那就是我们将用三个不同权重的矩阵与词嵌入向量进行点积运算,然后我们会得到三个向量,第一个是Queries向量,第二个是Keys向量,第三个是Values向量。可能会纳闷,这三个不同的向量各自有什么作用呢。正如其名字一样,Queries向量是负责询问的,还记得我们在带有Attention机制的Seq to Seq模型中所讲的内容吗。我们用解码端的hti挨个去与编码端的hs求分数,事实上这就是一个Queries的过程,那么显而易见,这些编码端的hs就是我们的Keys。如下图。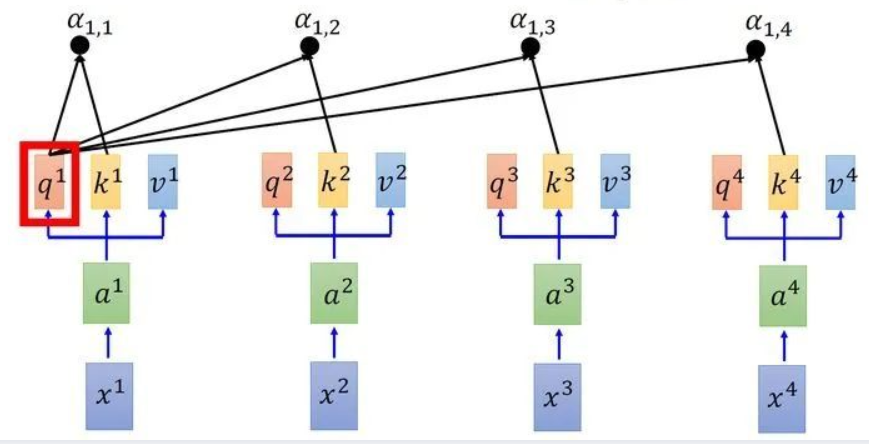
事实上,我们真正运作的时候并不是一个一个等找完才能找下一个,我们常常讲究“并行化”,也就是说我们把几个Queries向量和几个Keys向量分别整合成矩阵Q和矩阵K,然后Q矩阵和K矩阵进行点积,注意点积前要注意维度的变换。如下图所示,我们把向量拼接到一起成为矩阵,然后进行并行化运算操作。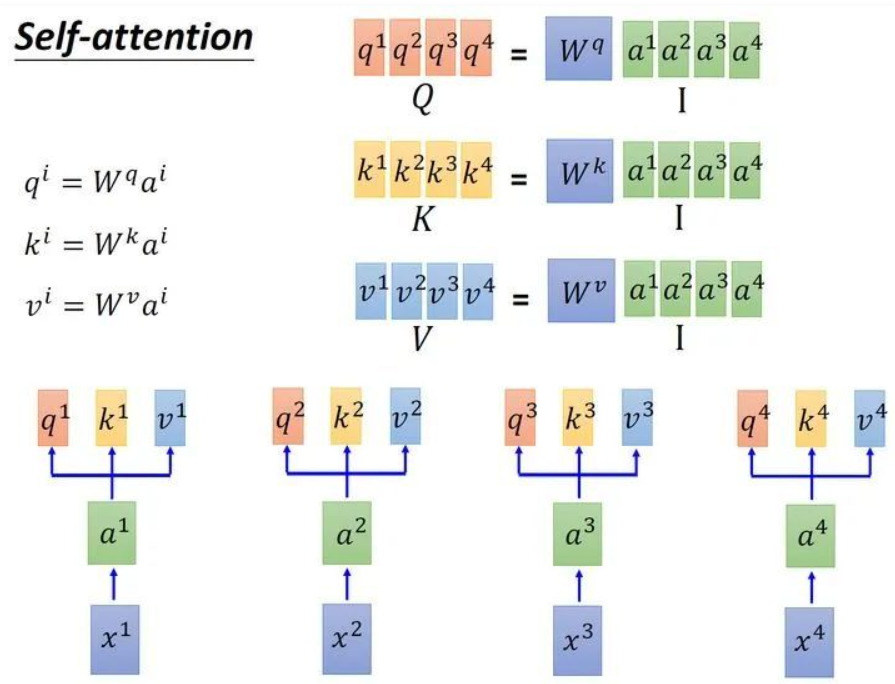
还记得我们之前提到,求完分数后需要进入softmax层进行一次变换,变换后所有的分数加和为一,相当于一次缩放变换。如下图所示,得到分数α。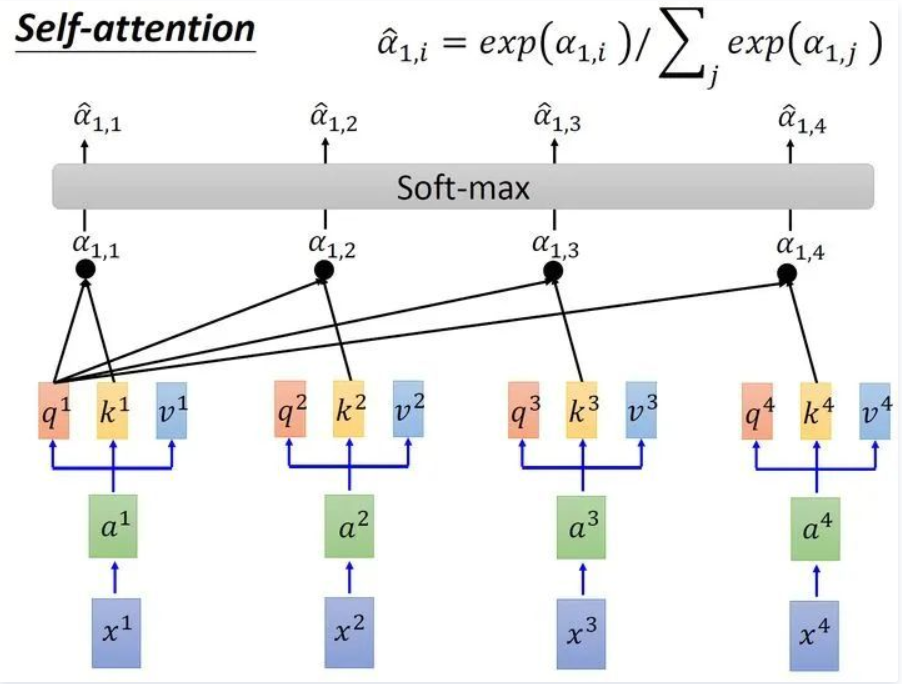
在这之后我们把每一个分数与hs中的对应位置的values向量进行乘积运算并加和,得到了输出。在我的理解里,我们求分词的过程就是一个求权重的过程,因此Q和K是一个配对的过程。就好比说我们找老婆,有的女生和你配对指数高,有的女生和你配对指数低,这一过程归根结底就是一次求权重的过程,是为了我们的values向量服务的。
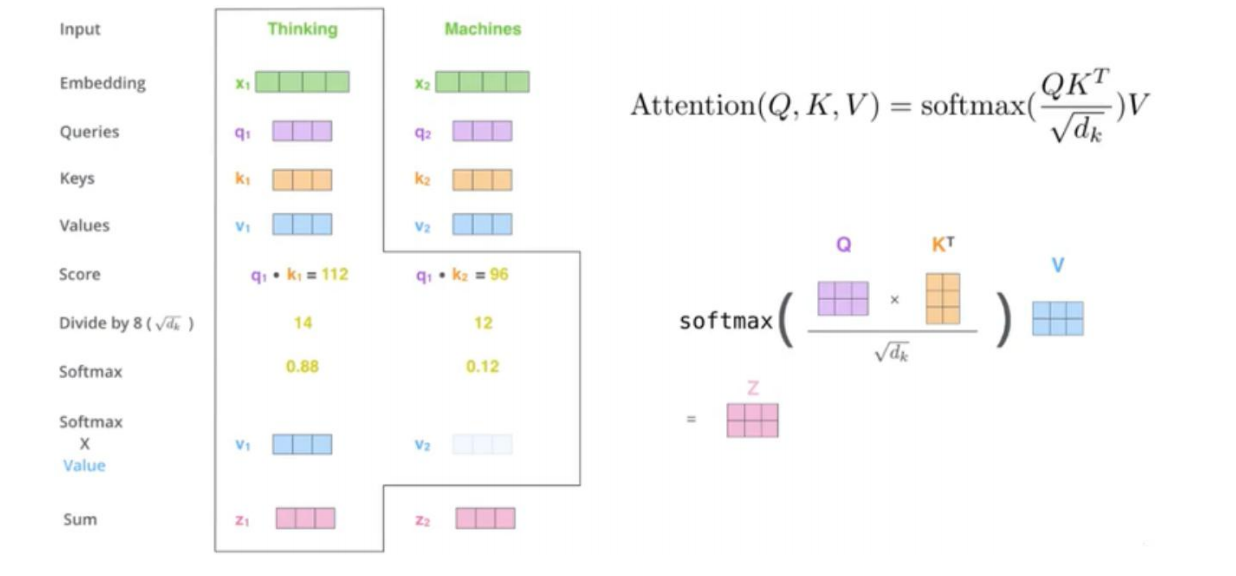
对于使用self Attention的原因,论文中提到的考虑因素主要有三点:
- 第一点是层的复杂度。相比于RNN网络,Self-Attention机制会更加注意相关性强的信息,能更好的利用已有信息,在短序列中,Self-Attention机制具有比较大的优势,当序列很长时,我们也可以通过改变询问个数,例如只与其中一部分来求分数。来避免运算量太过巨大。
- 第二点是并行运算。在并行运算方面,Self-Attention机制并不过分依赖于前一时刻的输出,更大程度上是采用了并行运算,而RNN比较依赖于前一时刻的输出。
- 第三点是长距离依赖学习。这也是比较重要的一点,我们知道,在RNN序列中,我们下一个时刻节点都与上一时刻的时间节点相关联,若是序列很长,那么前几个时刻的信息点就更容易被丢弃,尽管LSTM能够很好地解决这一问题,但由于RNN机制的存在,我们在保留的信息更多的是离输出端更近的信息。而Self-Attention机制不同,不管序列有多长,我们只需要直接与其计算分数即可,不需要经过多个时刻的传输,因此空间损耗很小,在长序列中能更好地捕捉到相关关系,因此Self-Attention机制地应用还是十分广泛的。
Flow Path
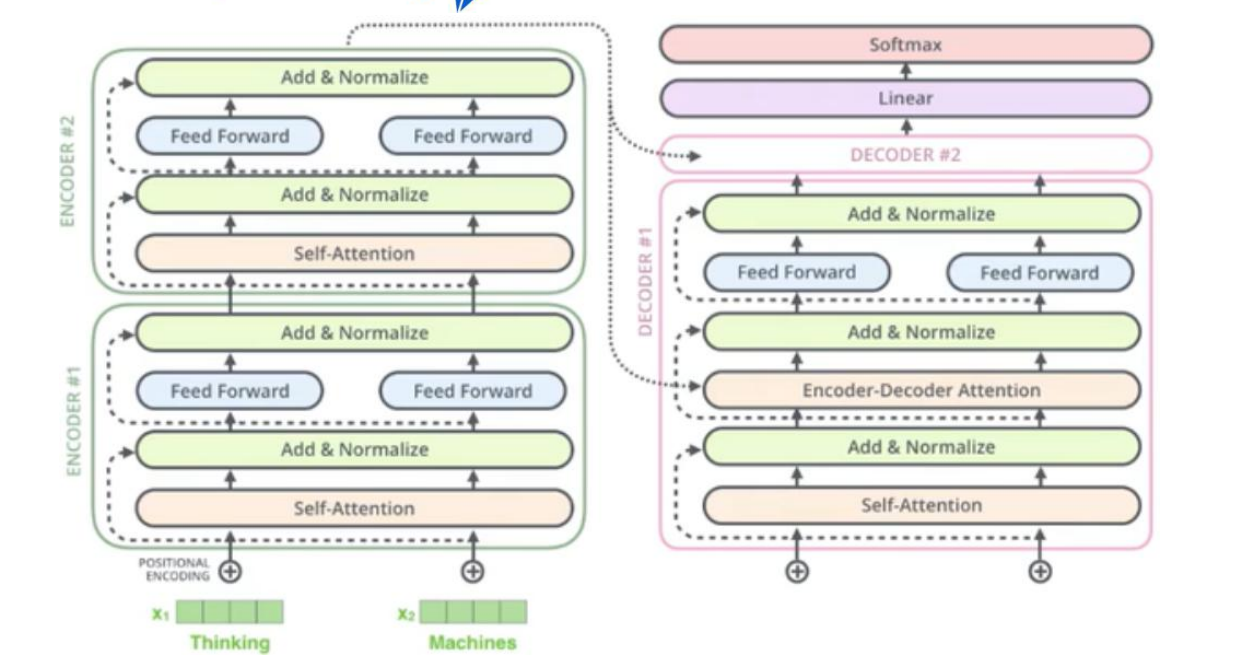
先来看看ENCODERS这边。先将输入的词文本转换成词向量,然后词向量再进行词嵌入(word embedding),将词嵌入向量ED输入到Self-Attention层中,将得到的输出与词嵌入向量加和(Resnet机制)并进行归一化操作,得到AN1,输出到Feed Forward层中,Feed Forward层无非就是做非线性变换而已,最后再将输出与AN1做加和操作,然后继续归一化。这就是一个ENCODER所做的事情,将几个ENCODER级联在一起就是ENCODERS。
再看看DECODERS这边。我们主要提提DECODERS几个需要注意的点:
- Decoder中存在Encoder-Decoder Attention层,这个层我们可以注意到图中的虚线,从ENCODERS的最后输出部分引出到各个DECODER中的Encoder-Decoder Attention层。Encoder-Decoder Attention层的过程我们无需再说,因为在上文中提到过。
- Decoder中的最后接了Linear线性变换和Softmax层,softmax层用于输出词分数,分数大的词序号作为预测值输出。
Tips
提出几个在transformer模型中得到了应用的优化:
- Position Embedding,事实上,由于Transformer的特殊机制,能使运算并行化,极大地提高了运行效率,但对于那些对于时间有着很高要求的序列,例如做机器翻译时,“我想你”和“你想我”意思有着极大的不同,但如果没有注意位置信息,很容易就会造成翻译错误,因此这时候我们常常会做Position Embedding操作来使得我们的序列带有位置信息。事实上,Embedding这个词对我们来说也不陌生了,它就是嵌入的意思,顾名思义,我们要把位置信息嵌入到序列中,还记得我们序列自己也要进行Word Embedding吗,我们把序列和位置信息分别做Embedding后会得到两个序列,之后我们进行对应位置的加和即可。
- Resnet机制。引用于微软的何恺明的残差网络机制,我们都知道,在推理演绎的过程中,我们很可能会丢失一部分信息,而这部分信息是不可逆的,也就是说丢掉了就不会再出现了,因此引入残差网络机制能够更好地保留那些重要的信息,事实也证明,引入残差网络机制更有利于我们对于特征的构建。
- Normalization。我要说的最后一个优化点就是归一化,无论当我们经过隐藏层还是Self Attention层或者是前馈层,都可以做一次归一化,使数据服从于同一分布,这绝对是有好处的。
Summary
这就是Transformer的整个过程了。自从2017年Transformer被提出后,其就得到了广泛的应用,像之后提出的Bert也算是一种小型的优化和封装,但事实上原理依然是Transformer模型,之后的一些优化也大部分都是围绕Transformer展开的,根据所需求的工程,我们完全可以使用微调模型,使之能更好地与你的工程进行匹配。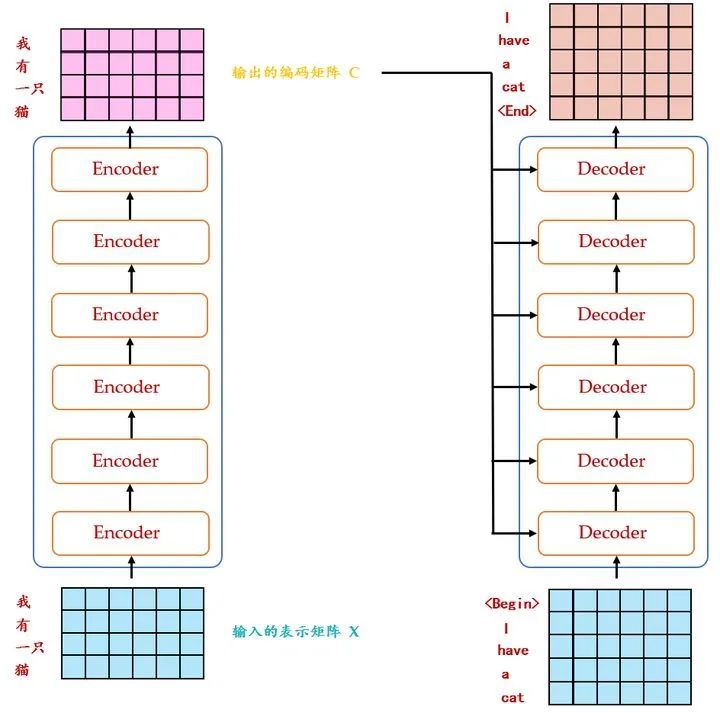

若有收获,就点个赞吧
0 人点赞
