Introductions
如今处于人工智能崛起的时代,自然语言处理是十分火热的,自然语言处理被广泛应用于机器翻译,语音识别,情感分析等领域。虽然自然语言处理近年来很火热,但其发展却离不开统计语言模型,换言之,统计语言模型是自然语言处理的基础,因此,在进入自然语言处理之前我们需要先深入了解统计语言模型。传统的统计语言模型是表示语言基本单位(一般为句子)的概率分布函数,这个概率分布也是该语言的生成模型。通俗的讲,如果一句话没有在语料库中出现,可以模拟句子的生成的方式,生成句子在语料库中的概率。一般语言模型可以使用各个词语条件概率的形式表示: 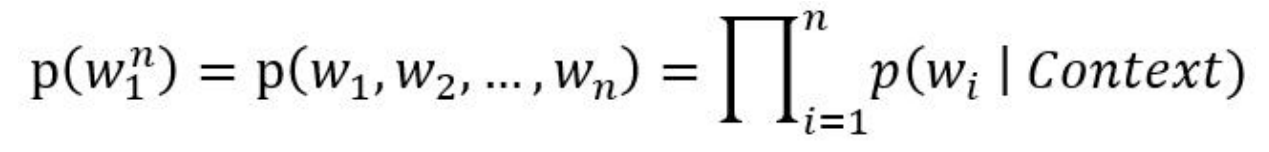
其中,Context 为 w_i 的上下文表示。根据 Context 的表示差异,统计语言模型又可以分为不同的类别,其中最具代表性的有 n-gram 语言模型及 nn 语言模型。
Applications
N-gram是自然语言处理(NLP)中一个非常重要的概念,通常在 NLP 中,人们基于一定的语料库,
可以利用 N-gram 来做以下几类事情:
- 预计或者评估一个句子是否合理
- 评估两个字符串之间的差异程度,这也是模糊匹配中常用的一种手段
- 语音识别
- 机器翻译
- 文本分类
概率模型
统计语言实际上是概率模型,N-gram是概率模型中相当重要的概念,它常常被用于检测句子的合理性,模糊匹配,机器翻译,文本分类等等。
马尔可夫提出假设:未来的事件只取决于有限的历史,用到这里的话可以理解为句子中的第i个词取决于其之前的i-1个词,也就是说第i个词出现的概率是一个条件概率。由大数定律得,当样本量够多的时候,概率的比值可以用出现频次的比值来逼近。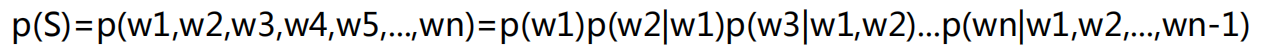
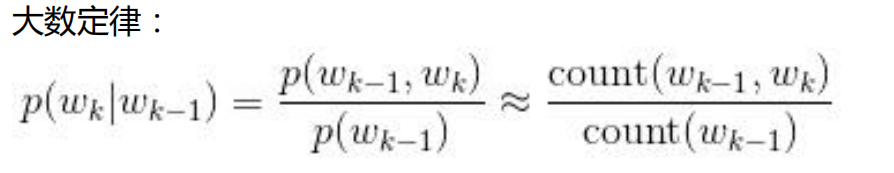
然而这也面临着一些问题,若是词库的量很大,句子中每个词需要计算的参数量都十分巨大,因此我们的N-gram模型常常选用三种模型,分别是一元模型,二元模型以及三元模型。N=1时是一元模型,每个词之间并无条件概率的关系,即每个词只由自己所决定。N=2时是二元模型,是最常用的模型,即每个词的出现取决于前一个词。N=3时是三元模型,是效果最好的模型,它的出现取决于前两个词,但事实上N=3的模型并没有N=2的模型常用。我们来展示一下二元模型。
- 频次分布表
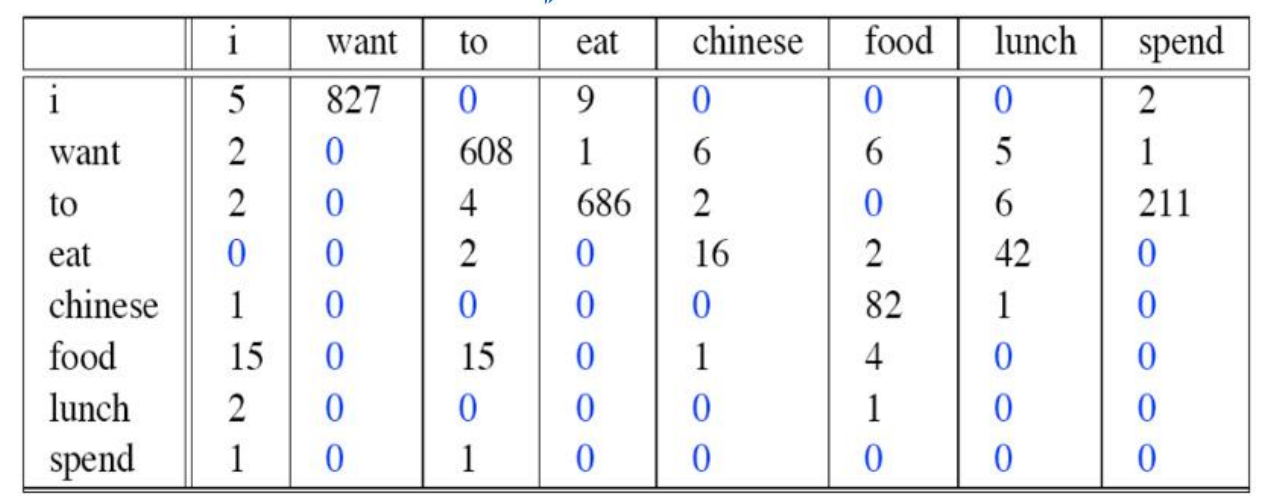
频率分布表
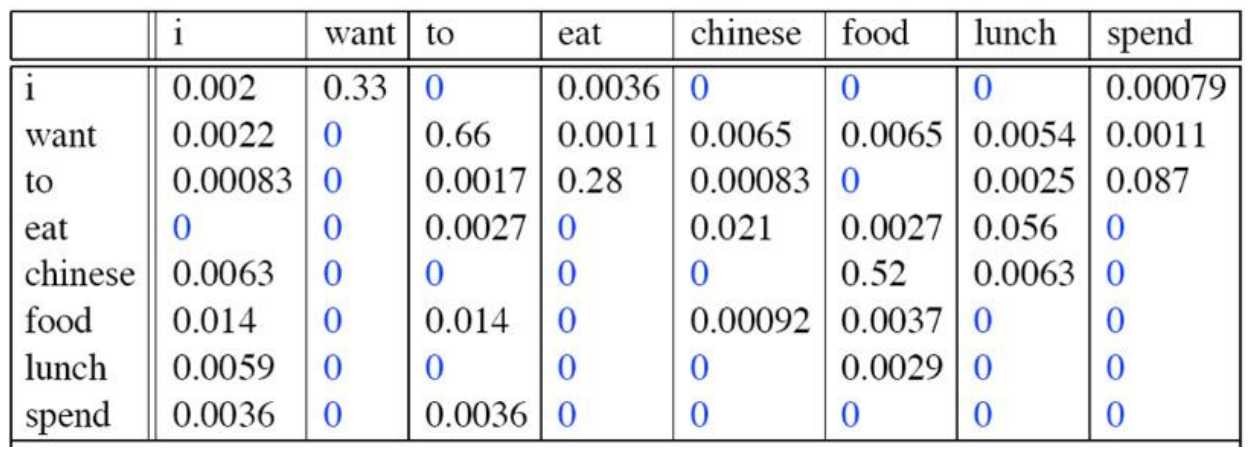
可以看出,N是一个超参数,N越大,每个词关联的相关因素就更多,约束信息就越多,模型具有强大的辨别力,辨别力怎么理解呢,举个例子,当N很大时,它可以很好的分辨出“它”,“他”,“她”三者的区别;N越小,在训练的语料库中出现的次数更多,可靠性越强,但是我们N大于3时的模型并不常用,因为语料库数目不够时大数定律不成立,可靠性就会降低,因此宁愿用N=2和N=3的模型,也不用N更大时的模型。
OOV问题与解决
我们还需要提到N-gram模型会出现的一些问题,比如说oov问题(out of vocabulary),oov问题是指我们的序列中出现了表外值,即不存在于词库中的词,一般的解决方案是设立一个词频阈值,当某个词出现的频次大于词频阈值时,我们会将这个词加入词库,将那些低于词频阈值的词替换为UNK(即未知符号的意思)。
还有一个问题就是某些词的词频是0(事实上很多词的词频都是0),也就构成了稀疏矩阵,因此我们需要做平滑处理,将对应位置词的词频加1,这样生成的概率也是个接近于0的概率值,同时也不会对整个句子的预测产生很大的影响。
优点与缺点
N-gram的优点是某个词的出现受前面的词的影响,因此具有很强的约束力,而且只看前i-1个词不看所有词,效率比较高。当然N-gram也有缺点,比如n-gram无法建立更远更深的模型关系,由于N通常等于2或3,因此不能训练更高阶的模型,通常只用于浅层模型,而且该模型无法建模出词与词的相似度。

若有收获,就点个赞吧
0 人点赞
