2014 年,Sutskever 等人提出了 sequence-to-sequence 模型。sequence-to-sequence模型是利用神经网络将一个序列映射成另一个序列的语言处理框架。事实上,我们可以把Seq to Seq模型分为两部分,一部分是我们的编码区(encoder area),另一部分是我们的解码区(decoder area)。下面来介绍一下模型的整体流程。
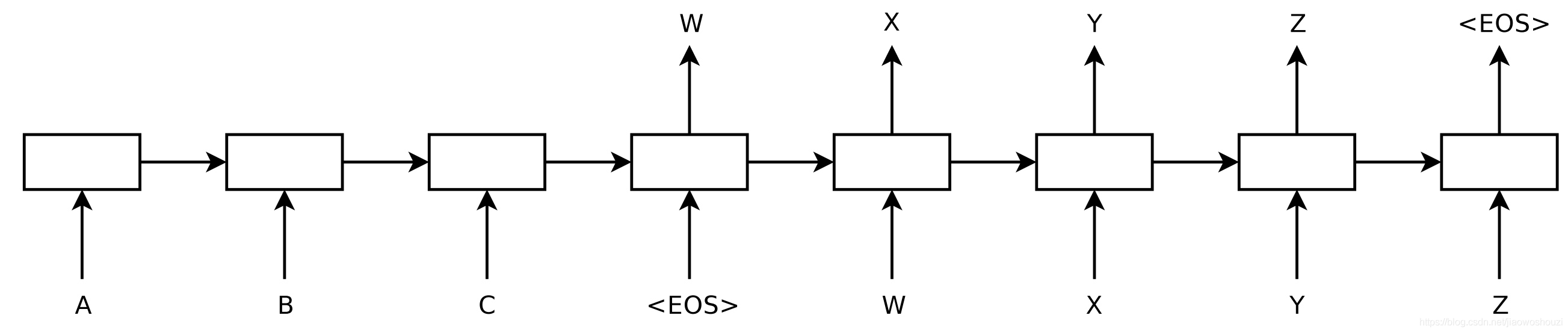
首先我们得到一定长度的序列,这里的序列可以是长度任意的序列,因为我们引入了一个特别的技巧,就是标识符,我们通过标识符来判断句子的起始位置和末尾位置。我们将序列输入到encoder area中,事实上,encoder area是堆叠的LSTM层,用于编码,因为LSTM在长时记忆上具有很大的优势,所以这里我们依然采用LSTM层去编码。我们用编码区逐符号地处理一个句子,然后将整个句子压缩成一个向量表示,这个向量表示实际上就是中间语义,这个中间语义可以更简洁地表述我们已经输入的句子序列。然后我们通过解码器逐符号地进行解码,并将上一步的输出作为下一步的输入,事实上,我们不但把上一步的输出作为下一步的输入,还将之前得到的中间语义编码也输入,也就是说,除了第一个解码的步位,以后的每一个解码步位都有两个输入,注意解码区最后一步的输出是一个标识符,代表解码结束。
具体过程如下图所示。

若有收获,就点个赞吧
0 人点赞
