Introduction
Attention注意力机制(Bahdanau 等,2015)是神经网络机器翻译(NMT)的核心创新之一,其不仅在机器翻译领域(NMT)取得了很大的成效,在其他领域也有所应用。
事实上,Attention机制只是一种通用的技巧,并不是一类模型,最初是将其应用在Seq to Seq模型上的。Seq to Seq模型在上文中已有介绍,在此文中就不多加赘述了。事实上,在Seq to Seq模型中,我提到了一个词叫做中间语义编码,这个编码是通过Encoder中的LSTM层对输入的句子序列进行非线性变换推理演绎得到的。然后解码时的每一步位都会使用这一中间语义编码,这就涉及到了一个问题——中间语义编码对于解码区所有的步位影响都是相同的。事实上,在大多数情况下,我们的输出的信息都跟句子序列的位置有关,因此我们需要让中间语义对我们的解码区步位的影响不同。目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。 这意味着在生成每个单词 yi 的时候,原先都是相同的中间语义表示 C 会被替换成根据当前 生成单词而不断变化的 Ci。理解 Attention 模型的关键就是这里,即由固定的中间语义表 示 C 换成了根据当前输出单词来调整成加入注意力模型的变化的 Ci。增加了注意力模型的Encoder-Decoder 框架理解起来如下图所示。 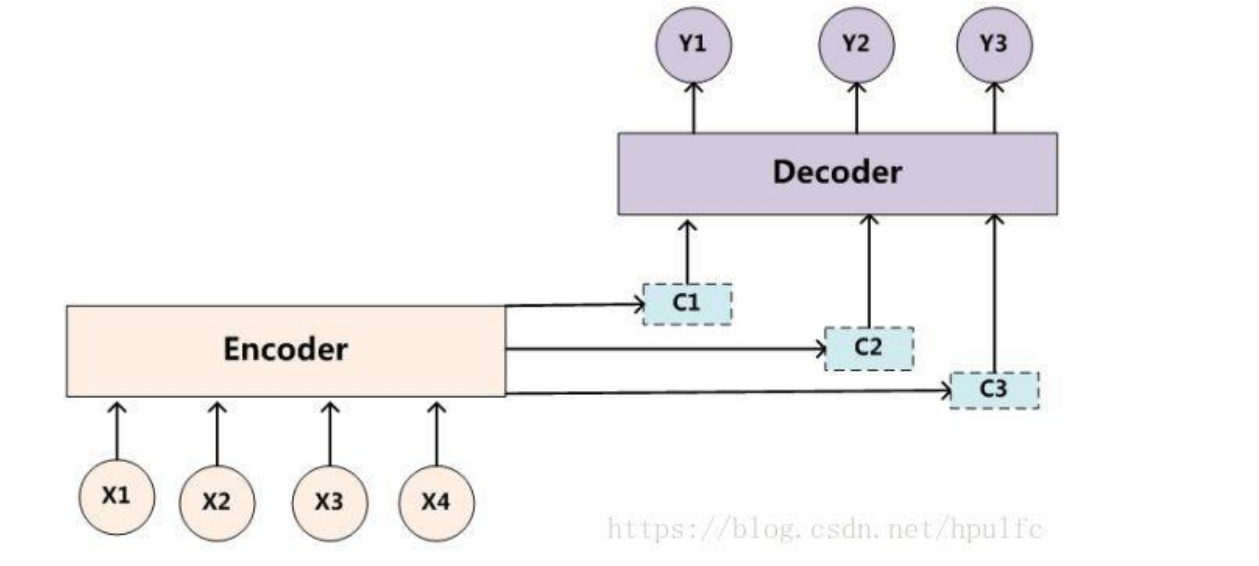
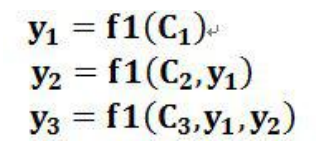
Examples
下面来举一个机器翻译的例子。这句话是”Tom chase Jerry”,我们要翻译成“汤姆追逐杰瑞”。如下图所示。
先来介绍函数的意思,f2函数代表的是隐藏层的非线性变换,数字代表着注意力权值,g函数是中间语义编码函数,也就是将输入映射到中间语义编码的函数。 在这里g函数是加权求和函数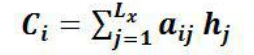 。其中,Lx 代表输入句子 Source 的长度,aij 代表在 Target 输出第 i 个单词时 Source 输入句子中第 j 个单词的注意力分配系数,而 hj 则是 Source 输入句子中第 j 个单词的语义编码。 假设下标 i 就是上面例子所说的“ 汤姆” ,那么 Lx 就是 3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是 0.6,0.2,0.2,所以 g 函数本质上就是个加权求和函数。表示成图示如下图所示。
。其中,Lx 代表输入句子 Source 的长度,aij 代表在 Target 输出第 i 个单词时 Source 输入句子中第 j 个单词的注意力分配系数,而 hj 则是 Source 输入句子中第 j 个单词的语义编码。 假设下标 i 就是上面例子所说的“ 汤姆” ,那么 Lx 就是 3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是 0.6,0.2,0.2,所以 g 函数本质上就是个加权求和函数。表示成图示如下图所示。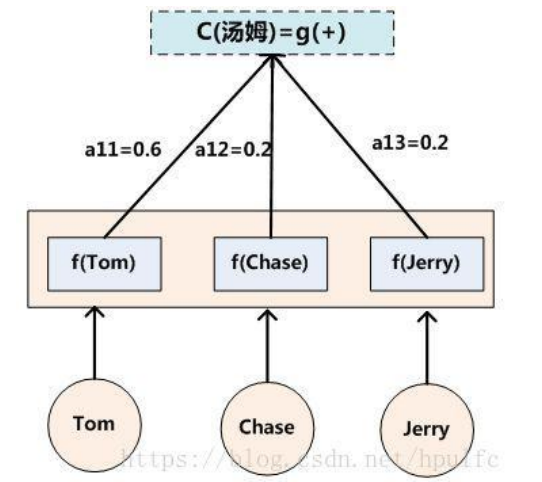
Approach
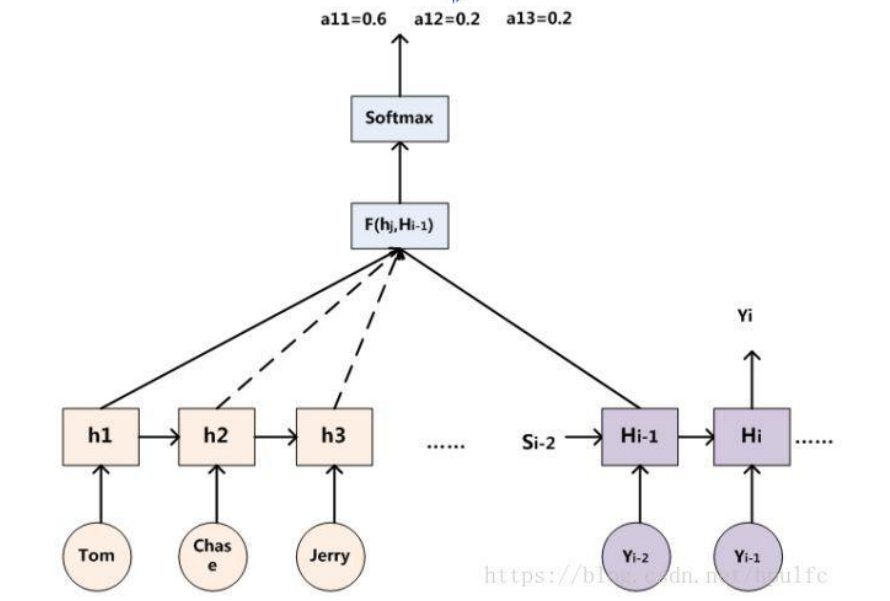
对于采用 RNN 的 Decoder 来说,在时刻 i,如果要生成 yi 单词,我们是可以知道 Target 在生成 Yi 之前的时刻 i-1时,隐层节点 i-1 时刻的输出值 Hi-1 的,而我们的目的是要计算生成 Yi 时输入句子中的单词“Tom”、“Chase”、“Jerry”对 Yi 来说的注意力分配概率分布,那么可以用 Target 输出句子 i-1 时刻的隐层节点状态 Hi-1 去一一和输入句子 Source 中每个单词对应的 RNN 隐层节点状态 hj 进行对比,即通过函数 F(hj,Hi-1)来获得目标单词 yi 和每个输入单词对应的对齐可能性,这个 F 函数在不同论文里可能会采取不同的方法,然后函数 F 的输出经过 Softmax 进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
Algorithm flow
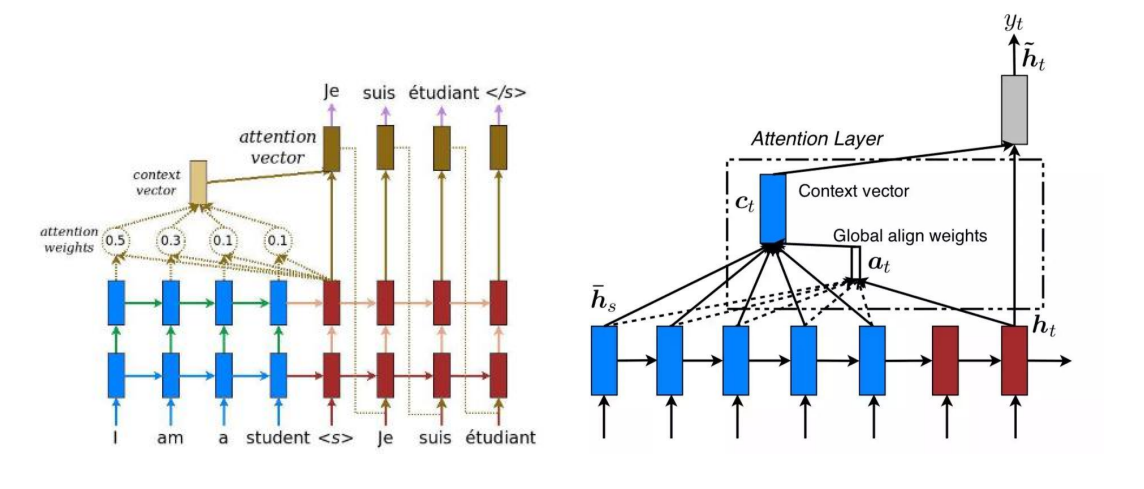
在了解整个流程前,我们需要弄清每一部分的作用,左图中的蓝色部分是Encoder部分,顾名思义,是输入数据端,也就是编码的过程,红色部分是Decoder部分,是我们的目标端,也就是解码的过程。假设我们要做机器翻译,我们有两层的隐藏层,我们要将英语翻译成西班牙语,那么输入端自然是我们的英语,目标端是西班牙语。我们先对Encoder部分和Decoder部分进行两次非线性变换,也就是穿过两层的隐藏层,事实上,如图所示,编码端每一次的非线性变换的输入来源不止一个,在输入端除了第一时刻,往后的每个时刻的纵列的隐层的输入一方来自于自己纵列,另一方来自于上一时刻隐藏的输出,输入来源不唯一,输出当然也不唯一,也分为了纵列输出和传给了下一时刻。解码端第一隐层的输入来源也有两个,一个是上一时刻隐藏层的输入,一个是上一时刻目标端的输出。(解码端的第一个步位由于没有上一时刻输出,因此是)。我们把第二个隐藏层的输出称为h,左边的是hs,右边的是ht。以第一个ht1为例,注意图中有个,这是一个标记符,一般放置在第一个,代表着从第一个开始。ht1先拿去和Encoder端的各个hsi求分数,求分数的方式有三种,一种是求余弦距离,一种是使用神经网络,最后一种是矩阵变换。我们常常用矩阵变换来求分数,即hsi与一权重W点积后再与ht1点积。这个过程可以这样理解:我们假定要输出的是“我”,我们用“我”和那几个英语单词求分数,越相似分数越高,那么英语单词中的I的分数肯定比其他高,我们求完分数后再做一次softmax变换得到attention weights,使得分数之和为1,然后我们将hsi与attention weights对应两两相乘加和求平均,得到context vector,简称cti,还记得我们前面有个hti对吗,我们将cti与hti进行矩阵的合并,然后我们将合并后的矩阵与一个W矩阵点积后进行Tanh变换得到attention vector。这就是Attention机制的整个流程。
tips
- hti与各个hs的分数是由ht-1去求的。也就是说下一时刻的注意力是由解码端上一时刻的隐藏层与编码端隐藏层的各个节点去求的。
- 求完分数后需要做softmax变换得到attention weights。
Summary
我们仔细分析Attention机制的过程可以得知,Attention机制将encoder端的所有隐藏层的信息都传到了decoder端,这是由求分数实现的,但是decoder却不是将所有的隐藏层都作为输入,而是采用一种选择机制,分数高的才会被选出来。

若有收获,就点个赞吧
0 人点赞
