人们经常问我们 Flink 如何处理背压效应。 答案很简单:Flink 没有使用任何复杂的机制,因为它不需要。 作为一个纯数据流引擎,它可以优雅地应对反压。 在这篇文章中,我们介绍了反压的问题。 然后,我们深入研究 Flink 的运行时如何在 Task 之间传输数据缓冲区,并展示流数据传输如何自然地应用反压机制。 我们最终通过一个小实验展示了这一点。
什么是反压
像 Flink 这样的流系统需要能够优雅地处理反压。 反压是指系统在临时负载峰值期间接收数据的速率高于它所能处理的速率。 许多日常情况都会导致反压。 例如,垃圾收集停顿可能会导致传入数据累积,或者数据源可能会出现发送数据的速度达到峰值。 反压如果处理不当,可能会导致资源耗尽,甚至在最坏的情况下会导致数据丢失。
让我们看一个简单的例子。 假设一个数据流管道有一个 Source、一个 Streaming Job 和一个 Sink,它在稳定状态下以每秒 500 万个元素的速度处理数据,如下所示(一个黑条代表 100 万个元素,图像是系统1秒的“快照”):

在某个时间点,Streaming Job 或 Sink 有 1 秒的停顿,导致 500 万个元素累积。 或者,Source 可能有一个尖峰,在一秒钟的时间内以双倍的速率生成数据。

我们如何处理这样的情况? 当然,可以丢弃这些元素。 但是,对于许多流式应用程序来说,数据丢失是不可接受的,因为它们只需要精确一次( exactly once)处理记录。 额外的数据需要在某处缓冲。 缓冲也应该是持久的,因为在失败的情况下,需要重放这些数据以防止数据丢失。 理想情况下,这些数据应该缓冲在一个持久的通道中(例如,如果 Source 保证持久性,则 Source 本身就应该进行缓冲 - Apache Kafka 就是这种通道的一个典型示例)。 理想的反应是从 Sink 到 Source “反压”整个管道,并对 Source 进行限速,以便将速度调整到管道最慢部分的速度,从而达到稳定状态:

Flink 中的反压
Flink 运行时的构建块是算子和流。 每个算子都在消费中间流,对它们应用转换,并产生新的流。 描述网络机制的最好类比是,Flink 使用容量有限的有效分布式阻塞队列。 与 Java 连接线程的常规阻塞队列一样,一旦队列的缓冲耗尽(有限容量),速度较慢的接收方将降低发送方的速度。
以下面两个 Task 之间的简单流程为例,说明 Flink 如何实现反压:
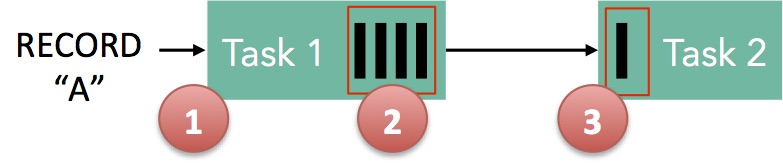
- 记录“A”进入 Flink 并由 Task 1 处理
- 记录被序列化到缓冲区中
- 这个缓冲区被发送到 Task 2,然后从缓冲区中读回记录
主要观察结果如下:为了让记录通过 Flink,缓冲区需要可用。 在 Flink 中,这些分布式队列是逻辑流,有界容量是通过每个生产和消费流的托管缓冲池来实现的。 缓冲池是一组缓冲区,它们在使用之后被回收。 总体思路很简单:你从池中取出一个缓冲区,用数据填充它,在数据被使用之后,你将缓冲区放回池中,在那里你可以再次重用它。
这些池的大小在运行时动态变化。 网络堆栈中的内存缓冲区数量(= 队列的容量)定义了系统在存在不同发送方/接收方速度的情况下可以执行的缓冲量。 Flink 保证总是有足够的缓冲区来取得某些进度,但是进度的速度取决于用户程序和可用内存的数量。 更多内存意味着系统可以简单地缓冲某些瞬时反压(短周期、短 GC)。 更少的内存意味着对反压的更快的反应。
以上面的简单示例为例:Task 1 在输出端有一个与之关联的缓冲池,而 Task 2 在输入端。 如果有可用于序列化“A”的缓冲区,我们将其序列化并分配缓冲区。
我们必须在这里看两个案例:
- 本地交换:如果 Task 1 和 Task 2 都运行在同一个工作节点(TaskManager)上,缓冲区可以直接交给下一个 Task。 一旦 Task 2 使用完它,它就会被回收。 如果 Task 2 比 Task 1 慢,缓冲区的回收速度将低于 Task 1 填充的速度,从而导致 Task 1 的速度变慢。
- 远程交换:如果 Task 1 和 Task 2 在不同的工作节点上运行(TaskManager),则缓冲区可以发送到线路上(TCP 通道)后立即回收。 在接收端,数据从线路上复制到输入缓冲池的缓冲区。 如果没有可用的缓冲区,则会中断从 TCP 连接上读取数据。 输出端永远不会通过简单的 watermark 机制在线路上放置太多的数据。 如果有足够的数据在传输中,则在将更多数据复制到线路之前需要等待,直到它低于阈值。 这保证了永远不会有太多的数据在传输中。 如果接收端没有消耗新数据(因为没有可用的缓冲区),这会降低发送方的速度。
在固定大小的池之间的这种简单的缓冲区流使 Flink 具有强大的反压机制,其中 Task 生成数据的速度永远不会超过消耗的速度。
我们描述的 Task 之间的数据传输机制自然地推广到复杂的管道,保证反压通过整个管道传播。
让我们看一个简单的实验,展示 Flink 工作在反压下的行为。 我们运行一个简单的生产者-消费者流式拓扑,Task 在本地交换数据,我们改变 Task 产生记录的速度。 因为演示的原因,对于这个测试,我们使用的内存少于默认值,从而使反压效果更加可见。 我们为每个 Task 使用 2 个大小为 4096 字节的缓冲区。 在通常的 Flink 部署中,Task 将具有更大的缓冲区,这只会提高性能。 该测试在单个 JVM 中运行,但使用完整的 Flink 代码堆栈。
该图显示了生产(黄色)和消费(绿色)Task 随时间变化的平均吞吐量占最大吞吐量(在单个 JVM 中达到了每秒 800 万个元素)的百分比。 为了测量平均吞吐量,我们每 5 秒测量一次 Task 处理的记录数。
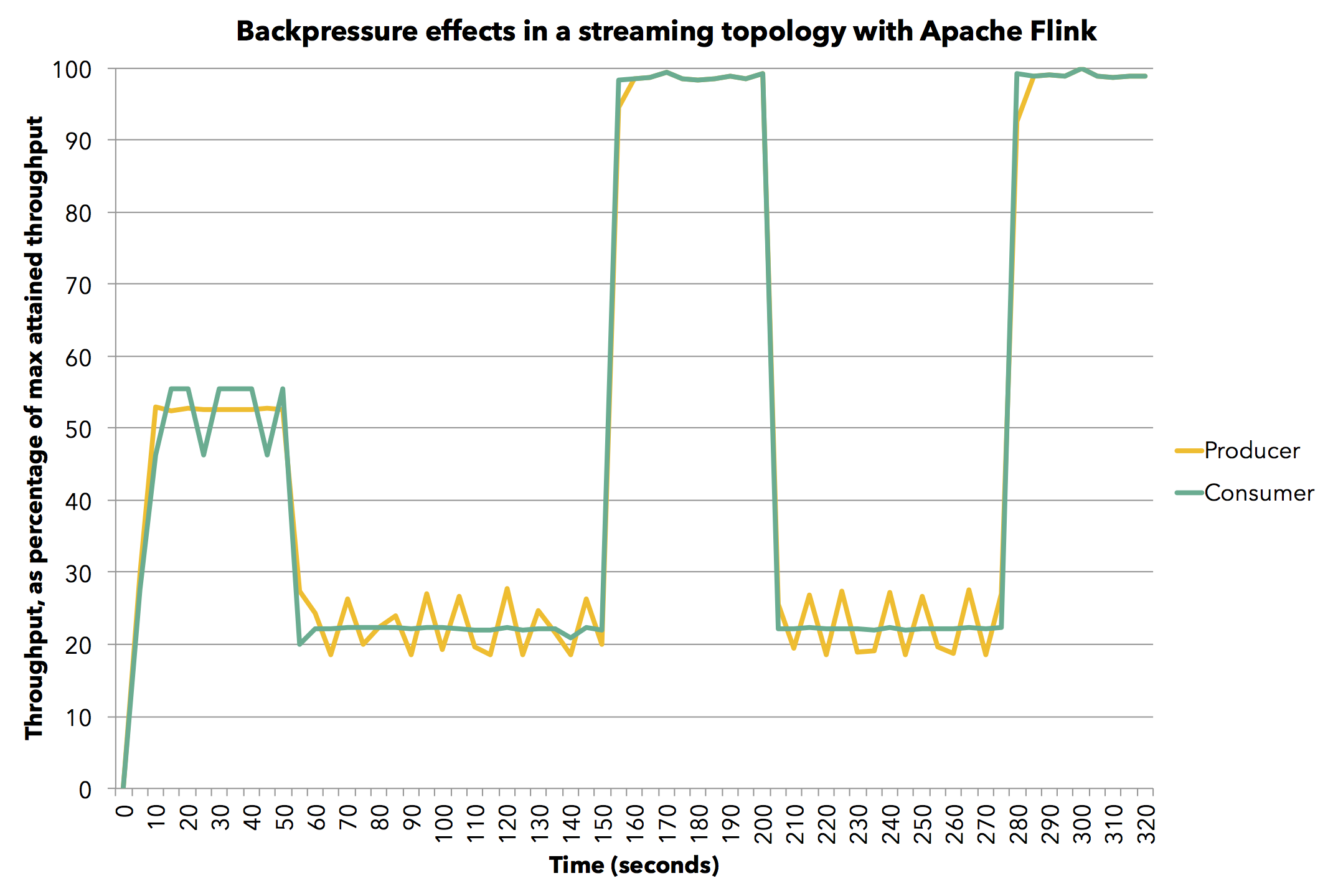
首先,我们以 60% 的全速运行生产任务(我们通过 Thread.sleep() 调用模拟减速)。 消费者以相同的速度处理数据,而不用人为地降低速度。 然后我们将消耗任务减慢到全速的 30%。 在这里,反压效应开始发挥作用,因为我们看到生产者也自然地减速到其全速的 30%。 然后我们停止消费者的人为减速,两个任务都达到最大吞吐量。 我们再次将消费者减速到全速的 30%,管道立即做出反应,生产者也减速到全速的 30%。 最后,我们再次停止减速,两个任务都以 100% 的全速继续。 总而言之,我们看到生产者和消费者在管道中相互跟踪对方的吞吐量,这是流管道中的预期行为。
总结
Flink 与 Kafka 这样的持久源一起,可以让你在不丢失数据的情况下立即处理反压。 Flink 不需要特殊的机制来处理反压,因为 Flink 中的数据传输兼作反压机制。 因此,Flink 达到了管道中最慢部分所允许的最大吞吐量。
翻译

若有收获,就点个赞吧
0 人点赞
