打印日志信息
客户端日志
你可以通过<font style="color:rgb(0, 0, 0);">print</font> 或者标准的 <font style="color:rgb(0, 0, 0);">Python logging</font> 模块,在 <font style="color:rgb(0, 0, 0);">PyFlink 作业中,Python UDF 之外</font>的地方打印上下文和调试信息。 在提交作业时,日志信息会打印在<font style="color:rgb(0, 0, 0);">客户端的日志文件</font>中。
from pyflink.table import EnvironmentSettings, TableEnvironment# 创建 TableEnvironmentenv_settings = EnvironmentSettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')])# 使用 logging 模块import logginglogging.warning(table.get_schema())logging.warning(table.to_pandas())# 使用 print 函数print(table.get_schema())print(table.to_pandas())
注意: 客户端缺省的日志级别是 WARNING,因此,只有日志级别在 WARNING 及以上的日志信息才会打印在客户端的日志文件中。
查看客户端日志
如果设置了环境变量<font style="color:rgb(0, 0, 0);">FLINK_HOME</font>,日志将会放置在 FLINK_HOME 指向目录的 log 目录之下。否则,日志将会放在安装的 pyflink 模块的 log 目录下。你可以通过执行下面的命令来查找 PyFlink 模块的 log 目录的路径:
这里我设置了环境变量 FLINK_HOME,所以 Flink 客户端日志路径为:
$ python -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__))+'/log')"
$FLINK_HOME/log/flink-root-client-<font style="color:rgb(51, 51, 51);background-color:rgb(248, 248, 248);">$HOSTNAME</font>.log
通过 Flink 命令行提交任务的日志保存在上面的文件夹中,同时命令行窗口也会打印输出
服务器端日志
你可以通过<font style="color:rgb(0, 0, 0);">print</font> 或者标准的 <font style="color:rgb(0, 0, 0);">Python logging</font> 模块,在 <font style="color:rgb(0, 0, 0);">Python UDF 中</font>打印上下文和调试信息。 在作业运行的过程中,日志信息会打印在 <font style="color:rgb(0, 0, 0);">TaskManager</font><font style="color:rgb(0, 0, 0);"> 的日志文件</font>中。
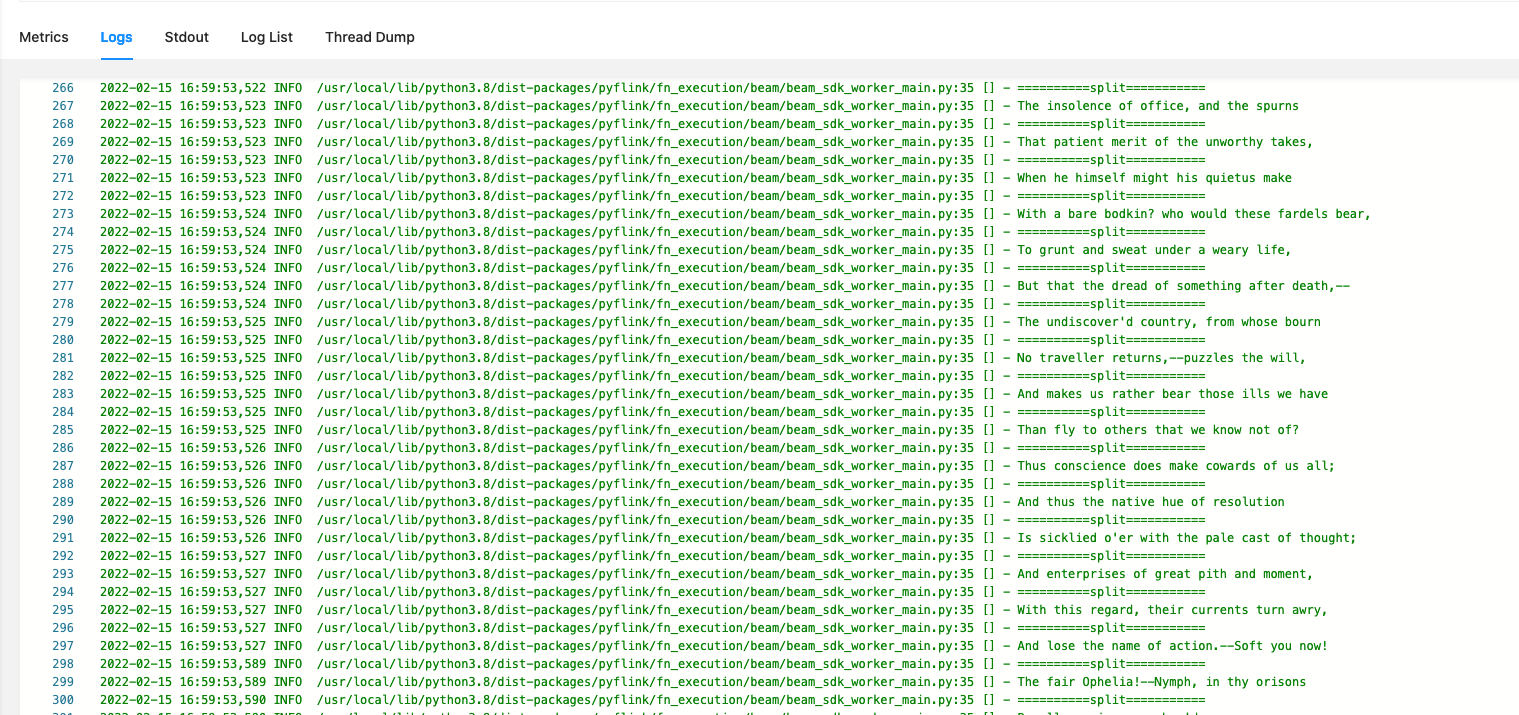
@udf(result_type=DataTypes.BIGINT())def add(i, j):# 使用 logging 模块import logginglogging.info("debug")# 使用 print 函数print('debug')return i + j
注意: 服务器端缺省的日志级别是 INFO,因此,只有日志级别在 INFO 及以上的日志信息才会打印在 TaskManager 的日志文件中。
查看服务器日志
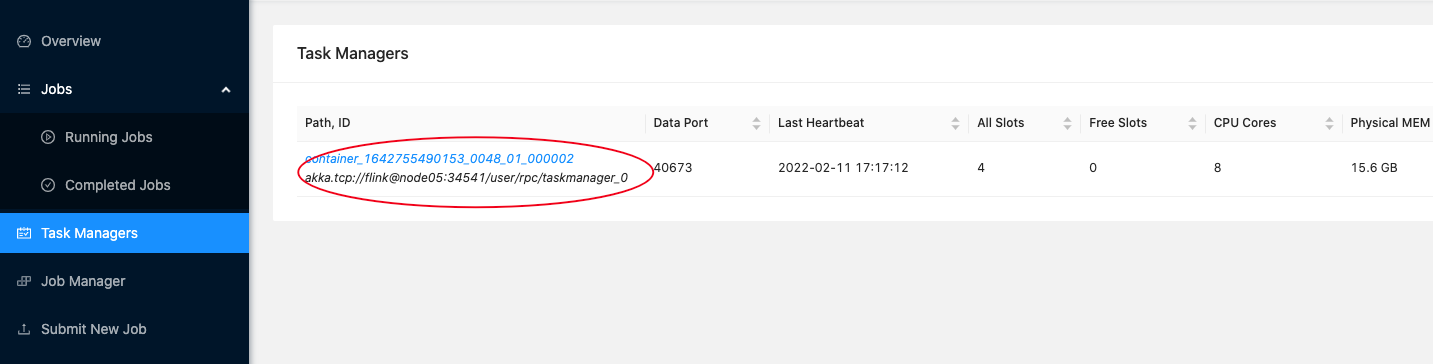
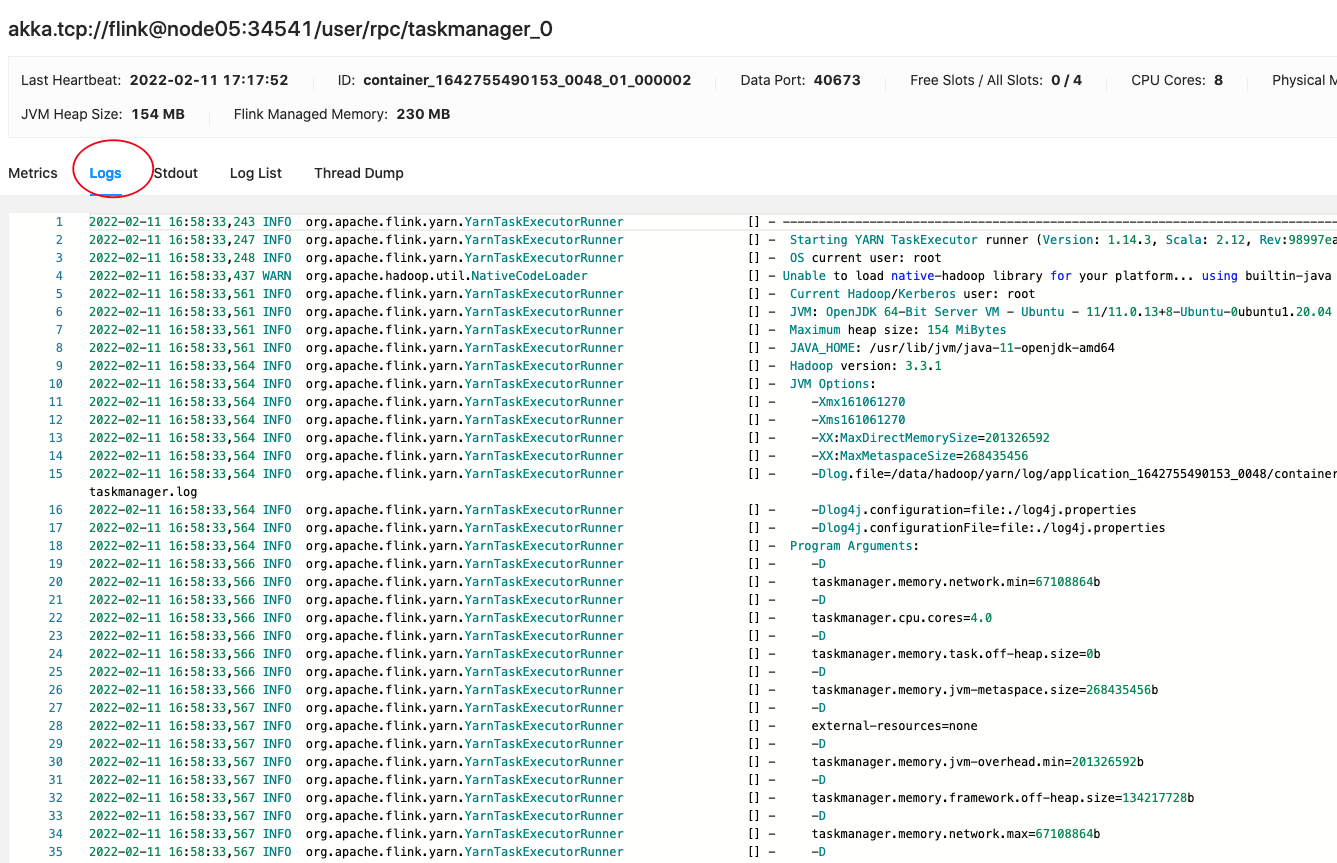
由于是 Flink On Yarn 部署,所以需要去 Yarn 的日志目录下查看 TaskManager 对应容器的日志 查看在 hadoop 的 yarn-site.xml 中配置的日志路径:进入 TaskManager 的日志,/data/hadoop/yarn/log/
<property><name>yarn.nodemanager.log-dirs</name><value>/data/hadoop/yarn/log</value></property>
调试 Python UDF
本地调试
你可以直接在 PyCharm 等 IDE 调试你的 Python UDF 函数(与普通 Python 函数没有差别)。远程调试
你可以利用 PyCharm 提供的 pydevd_pycharm 工具进行 Python UDF 的调试- 在 PyCharm 里创建一个 Python Remote Debugrun -> Python Remote Debug -> + -> 选择一个 port (e.g. 6789)
- 安装 pydevd-pycharm 工具
$ pip install pydevd-pycharm
- 在你的 Python UDF 里面添加如下的代码
import pydevd_pycharmpydevd_pycharm.settrace('localhost', port=6789, stdoutToServer=True, stderrToServer=True)
- 启动刚刚创建的 Python Remote Dubug Server
- 运行你的 Python 代码
可以参考 PyCharm 官网教程https://www.jetbrains.com/help/pycharm/remote-debugging-with-product.html
Profiling Python UDF
你可以打开 profile 来分析性能瓶颈你可以在
t_env.get_config().get_configuration().set_boolean("python.profile.enabled", True)
<font style="color:rgb(0, 0, 0);">TaskManager 的日志文件</font>里面查看 profile 的结果
PyFlink 应用调试实战
这里主要介绍如何打印日志信息以及打开 profile 来分析 Python UDF 性能,调试 Python UDF 与调试普通 Python 函数调试过程一样,这里就不在赘述,远程调试可以参考 PyCharm 官网教程。
完成示例程序如下:
import argparseimport loggingimport sysfrom pyflink.common import Rowfrom pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,DataTypes, FormatDescriptor)from pyflink.table.expressions import lit, colfrom pyflink.table.udf import udtfword_count_data = ["To be, or not to be,--that is the question:--","Whether 'tis nobler in the mind to suffer","The slings and arrows of outrageous fortune","Or to take arms against a sea of troubles,","And by opposing end them?--To die,--to sleep,--","No more; and by a sleep to say we end","The heartache, and the thousand natural shocks","That flesh is heir to,--'tis a consummation","Devoutly to be wish'd. To die,--to sleep;--","To sleep! perchance to dream:--ay, there's the rub;","For in that sleep of death what dreams may come,","When we have shuffled off this mortal coil,","Must give us pause: there's the respect","That makes calamity of so long life;","For who would bear the whips and scorns of time,","The oppressor's wrong, the proud man's contumely,","The pangs of despis'd love, the law's delay,","The insolence of office, and the spurns","That patient merit of the unworthy takes,","When he himself might his quietus make","With a bare bodkin? who would these fardels bear,","To grunt and sweat under a weary life,","But that the dread of something after death,--","The undiscover'd country, from whose bourn","No traveller returns,--puzzles the will,","And makes us rather bear those ills we have","Than fly to others that we know not of?","Thus conscience does make cowards of us all;","And thus the native hue of resolution","Is sicklied o'er with the pale cast of thought;","And enterprises of great pith and moment,","With this regard, their currents turn awry,","And lose the name of action.--Soft you now!","The fair Ophelia!--Nymph, in thy orisons","Be all my sins remember'd."]def word_count(input_path, output_path):t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode())# write all the data to one filet_env.get_config().get_configuration().set_string("parallelism.default", "1")# open profilet_env.get_config().get_configuration().set_boolean("python.profile.enabled", True)# define the sourceif input_path is not None:t_env.create_temporary_table('source',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).build()).option('path', input_path).format('csv').build())tab = t_env.from_path('source')else:print("Executing word_count example with default input data set.")print("Use --input to specify file input.")tab = t_env.from_elements(map(lambda i: (i,), word_count_data),DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())]))# define the sinkif output_path is not None:t_env.create_temporary_table('sink',TableDescriptor.for_connector('filesystem').schema(Schema.new_builder().column('word', DataTypes.STRING()).column('count', DataTypes.BIGINT()).build()).option('path', output_path).format(FormatDescriptor.for_format('canal-json').build()).build())else:print("Printing result to stdout. Use --output to specify output path.")t_env.create_temporary_table('sink',TableDescriptor.for_connector('print').schema(Schema.new_builder().column('word', DataTypes.STRING()).column('count', DataTypes.BIGINT()).build()).build())@udtf(result_types=[DataTypes.STRING()])def split(line: Row):print("==========split===========")print(line[0])for s in line[0].split():yield Row(s)# compute word counttab.flat_map(split).alias('word') \.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert('sink') \.wait()# remove .wait if submitting to a remote cluster, refer to# https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/python/faq/#wait-for-jobs-to-finish-when-executing-jobs-in-mini-cluster# for more detailsif __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')parser.add_argument('--output',dest='output',required=False,help='Output file to write results to.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input, known_args.output)
- 启动 Flink Session 集群
$FLINK_HOME/bin/yarn-session.sh --detached
- 提交 Job
为了满足 Python 版本要求,你可以选择通过软链接的方式将 python 指向 python3 解释器
$FLINK_HOME/bin/flink run --python word_count.py
如果你不想使用软链接的方式改变系统 Python 解释器的路径,你也可以通过配置的方式指定 Python 解释器
ln -s /usr/bin/python3 /usr/bin/python
$FLINK_HOME/bin/flink run -pyclientexec python3 -pyexec python3 --python word_count.py
- 查看控制台输出

- 查看客户端日志

- 查看服务器输出

- 查看服务器日志
- 查看 profile 日志


若有收获,就点个赞吧
0 人点赞
