Flink On Yarn 集群的高可用其实就是 JobManager 的高可用。
默认情况下,每个 Flink 集群只有一个 JobManager 实例。这会导致单点故障(SPOF):如果 JobManager 崩溃,则不能提交任何新程序,运行中的程序也会失败。
使用 JobManager 高可用模式,你可以从 JobManager 失败中恢复,从而消除单点故障。
如下是一个使用三个 JobManager 实例的例子: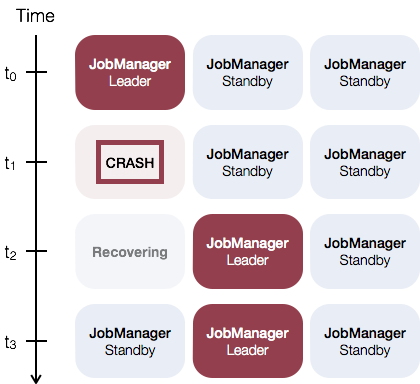
一个 Leader JobManager 以及两个 Standby JobManager,Leader 和 Standby 之间的切换是依赖于 zookeeper,所以部署之前必须安装好 Zookeeper 集群。
Flink On Yarn 部署
修改配置文件
修改 flink-conf.yaml
# jobmanager和taskmanager、其他client的RPC通信IP地址,TaskManager用于连接到JobManager/ResourceManager。# HA模式不用配置此项,在master文件中配置,由zookeeper选出leader与standbyjobmanager.rpc.address: localhost# jobmanager和taskmanager、其他client的RPC通信端口,TaskManager用于连接到JobManager/ResourceManager。# HA模式不用配置此项,在master文件中配置,由zookeeper选出leader与standbyjobmanager.rpc.port: 6123# jobmanager JVM heap 内存大小jobmanager.memory.process.size: 1024m# taskmanager JVM heap 内存大小taskmanager.memory.process.size: 1024m# 每个taskmanager提供的任务slots数量taskmanager.numberOfTaskSlots: 4# 并行计算个数parallelism.default: 4# 高可用模式high-availability: zookeeper# JobManager元数据保留在文件系统storageDir中 指向此状态的指针存储在ZooKeeper中high-availability.storageDir: hdfs://node01:9000/flink/ha/# Zookeeper集群high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181,node04:2181,node05:2181# 在zookeeper下的根目录high-availability.zookeeper.path.root: /flink_yarn# zookeeper节点下的集群ID 该节点下放置了集群所需的所有协调数据 多个flink集群连接同一套zookeeper集群需要配置各自不同的集群ID# 重要: 在 YARN、原生 Kubernetes 或其他集群管理器上运行时,不应该手动设置此值。在这些情况下,将自动生成一个集群 ID。如果在未使用集群管理器的机器上运行多个 Flink 高可用集群,则必须为每个集群手动配置单独的集群 ID(cluster-ids)。# high-availability.cluster-id: /default_ns# 单个flink job重启次数 必须小于等于yarn-site.xml中Application Master配置的尝试次数yarn.application-attempts: 10#==============================================================================# Fault tolerance and checkpointing#==============================================================================# jobmanager (MemoryStateBackend), filesystem (FsStateBackend), rocksdb (RocksDBStateBackend)state.backend: rocksdb# 检查点的默认目录。Flink支持的文件系统中存储检查点的数据文件和元数据的默认目录。必须从所有参与的进程/节点(即所有TaskManager和JobManager)访问存储路径。state.checkpoints.dir: hdfs://node01:9000/flink/checkpoints# 保存点的默认目录。由状态后端用于将保存点写入文件系统(MemoryStateBackend,FsStateBackend,RocksDBStateBackend)。state.savepoints.dir: hdfs://node01:9000/flink/savepoints# 是否应该创建增量检查点。对于增量检查点,只存储前一个检查点的差异,而不存储完整的检查点状态。一些状态后端可能不支持增量检查点并忽略此选项。state.backend.incremental: false# jobmanager故障恢复策略,指定作业计算如何从任务失败中恢复 full重新启动所有任务以恢复作业 region重新启动可能受任务失败影响的所有任务jobmanager.execution.failover-strategy: region# 全局检查点的保留数量state.checkpoints.num-retained: 3# 本地恢复。默认情况下,本地恢复处于禁用状态。本地恢复当前仅涵盖keyed state backends。当前,MemoryStateBackend不支持本地恢复。state.backend.local-recovery: true# 存储基于文件的状态以进行本地恢复的根目录。本地恢复当前仅涵盖keyed state backendstaskmanager.state.local.root-dirs: /opt/flink-tm-state# Task 重启策略restart-strategy: fixed-delayrestart-strategy.fixed-delay.attempts: 3restart-strategy.fixed-delay.delay: 10 s
修改 masters
修改 conf 目录下 masters 文件:
node01:8081node02:8081node03:8081node04:8081node05:8081
修改 workers
修改 conf 目录下 workers 文件:
node01node02node03node04node05
主备切换验证
启动 Flink session 集群
cd $FLINK_HOME./bin/yarn-session.sh --detached
提交 Job
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
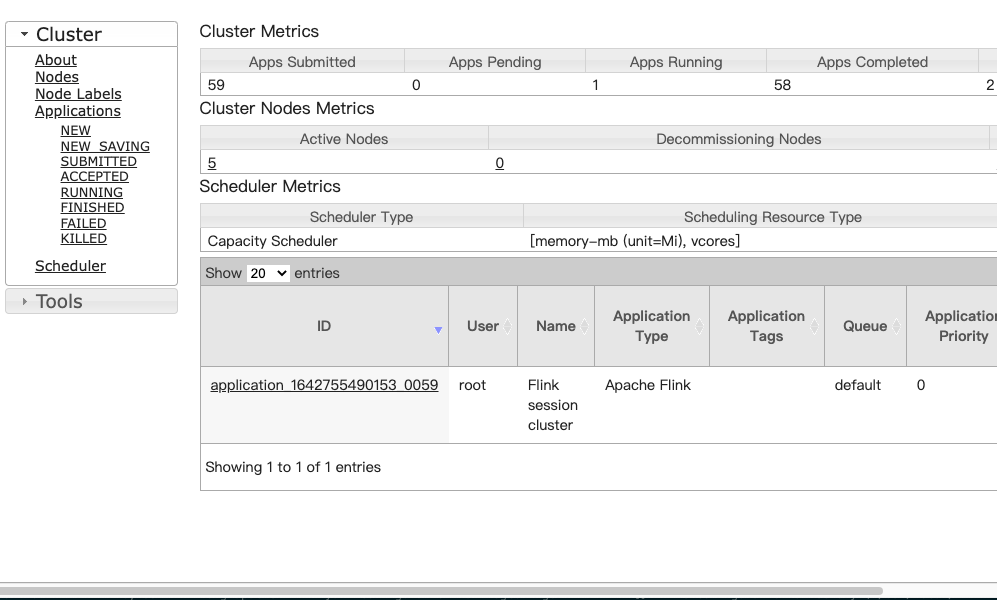
查看集群配置以及运行的节点
- 通过 Yarn 管理界面打开 Apache Flink Dashboard
拖动下面的滚动条至最右边,然后点击 ApplicationMaster 进入 Apache Flink Dashboard
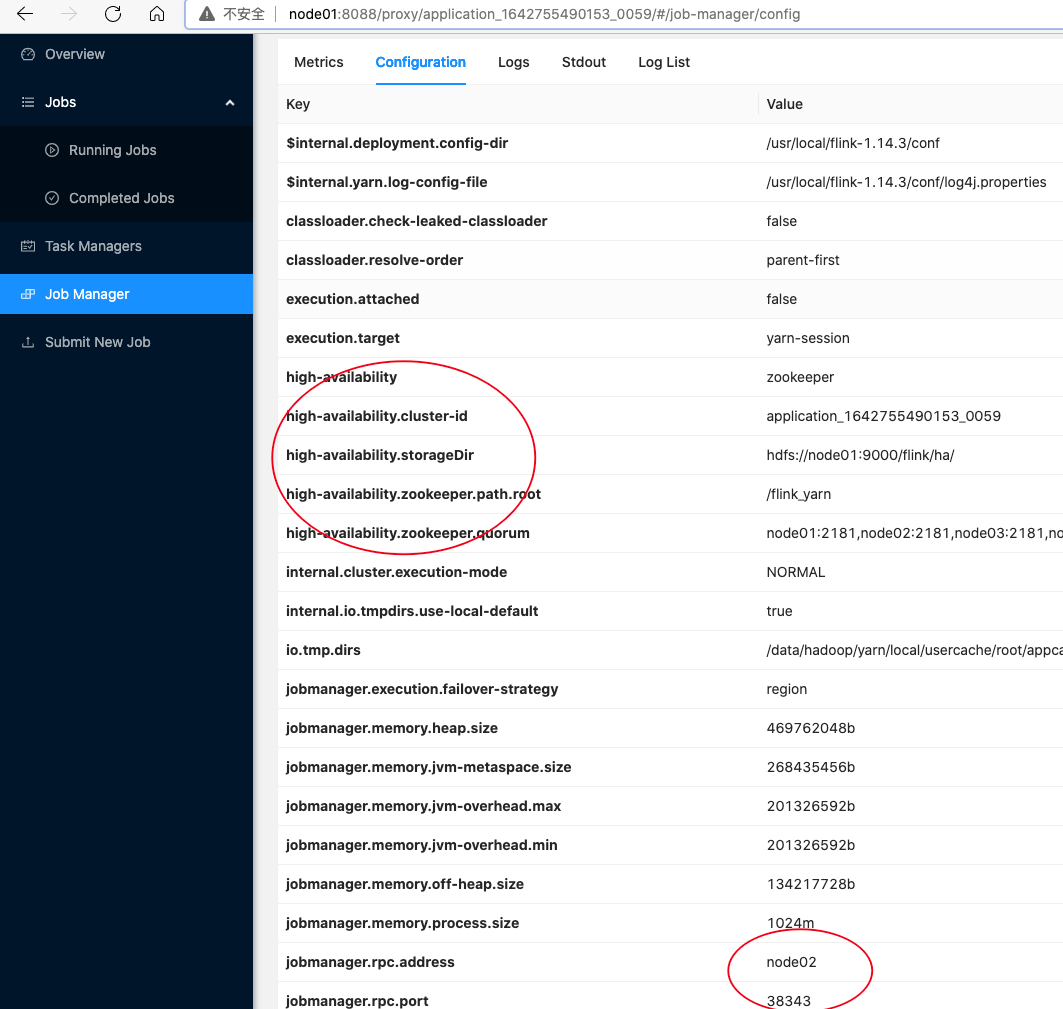
- 点击 Job Manager,可以看到 JobManager 的高可用配置,并且此时 JobManager 运行在 node02,端口号为 38343
- 在 node02 上查看运行的进程,其中 YarnSessionClusterEntrypoint 就是 JobManager 的进程
root@node02:~# jps26896 NodeManager25746 JournalNode26099 DataNode2177269 Jps2176890 YarnSessionClusterEntrypoint22878 QuorumPeerMain
- 点击 Task Managers,可以看到 TaskManager 运行在 node01,端口号为 41963
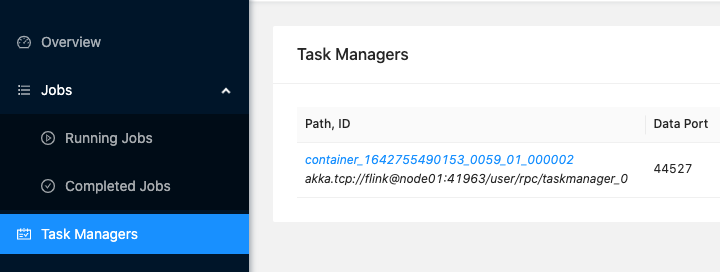
- 在 node01 上查看运行的进程,其中 YarnTaskExecutorRunner 就是 TaskManager 的进程
root@node01:/usr/local/flink# jps27043 NameNode2301152 Jps28965 ResourceManager29174 NodeManager23529 QuorumPeerMain28715 SecondaryNameNode27260 DataNode26494 JournalNode2300685 YarnTaskExecutorRunner
JobManager 高可用
Kill 掉 Active JobManager
在 node02 节点 kill YarnSessionClusterEntrypoint 进程
kill -9 2176890
查看 JobManager 运行的节点
- 刷新后点击 Job Manager,可以看到此时 JobManager 运行在 node01,端口号为 42831
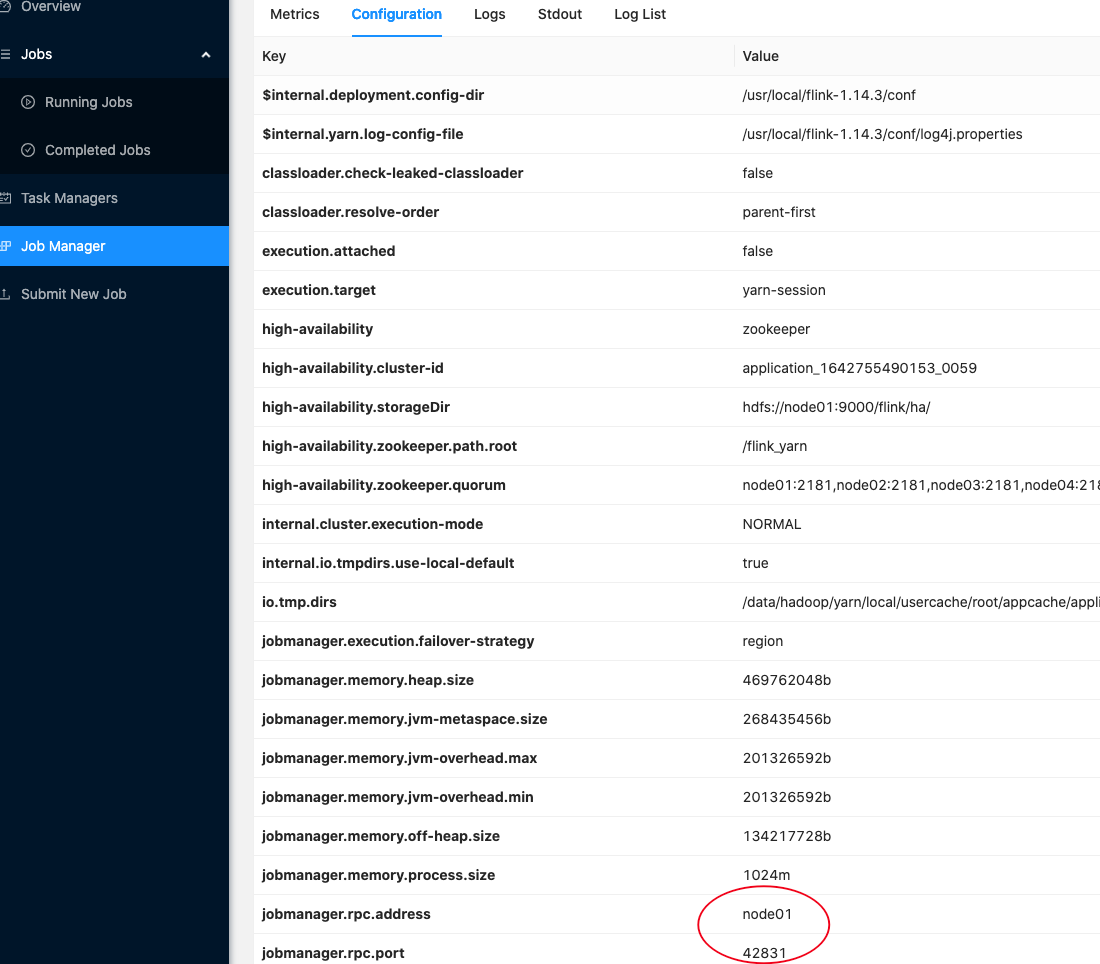
- 在 node01 上查看运行的进程,此时 YarnSessionClusterEntrypoint 和 YarnTaskExecutorRunner 都在 node01 节点上
root@node01:/usr/local/flink# jps27043 NameNode28965 ResourceManager29174 NodeManager23529 QuorumPeerMain2301481 Jps28715 SecondaryNameNode2301400 YarnSessionClusterEntrypoint27260 DataNode26494 JournalNode2300685 YarnTaskExecutorRunner
TaskManager 高可用
Kill 掉 Active TaskManager
在 node01 节点 kill YarnTaskExecutorRunner 进程
kill -9 2300685
查看 JobManager 运行的节点
- 刷新后点击 Task Managers,可以看到此时 JobManager 运行在 node01,端口号为 37241
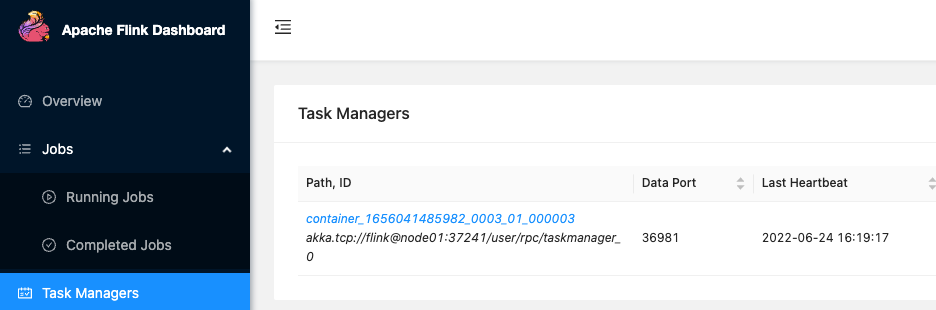
- 在 node01 上查看运行的进程,此时 YarnTaskExecutorRunner 进程号已经为新的进程
root@node01:/usr/local/flink# jps27649 YarnTaskExecutorRunner

若有收获,就点个赞吧
0 人点赞
