Flink 集群架构
Flink 集群架构简介

- Client 将 Flink 应用程序的代码转换为 JobGraph 并将其提交给 JobManager
- JobManager 将作业分配给 TaskManager,实际的算子(如 source、transformation和 sink)在 TaskManager 中运行
| 组件 | 目的 | 实现 |
|---|---|---|
| Flink Client | 将批处理或流式应用程序编译成数据流图,然后将其提交给 JobManager | + 命令行界面 + REST API + SQL 客户端 + Python REPL + Scala REPL |
| JobManager | JobManager 是 Flink 的工作协调组件。 实现了多个不同的资源提供者,它们在高可用性、资源分配方式和支持的作业提交模式上有所不同。 |
+ Standalone(这种模式只需要启动 JVM。 在此模式下可以使用 Docker, Docker Swarm / Compose,non-native Kubernetes 和其他模型进行手动部署) + Kubernetes + YARN |
| TaskManager | TaskManager 是实际执行 Flink 作业的服务 | |
| 外部组件 | ||
| HA 服务提供商 | Flink 的 JobManager 可以在高可用模式下运行,这样 Flink 可以从 JobManager 故障中恢复。 为了更快地进行故障转移,可以启动多个备用 JobManager 作为备份 | + Zookeeper + Kubernetes HA |
| 文件存储和持久性 | 对于 checkpoint(流式作业的恢复机制),Flink 依赖于外部文件存储系统 | 参见 FileSystems |
| 资源提供者 | Flink 可以通过不同的资源提供者框架进行部署,例如 Kubernetes 或 YARN | 参见 JobManager |
| Metrics 存储 | Flink 组件报告内部指标,Flink 作业也可以报告额外的、特定于作业的指标 | 参见 Metrics Reporter |
| 应用程序级 source 和 sink | 虽然应用程序级别的 source 和 sink 在技术上不是 Flink 集群组件部署的一部分,但在规划新的 Flink 生产部署时应该考虑它们。 使用 Flink 托管常用数据可以带来显着的性能优势 | 例如: + Apache Kafka + Amazon S3 + ElasticSearch + Apache Cassandra 参见 Connectors |
Flink 集群架构详解
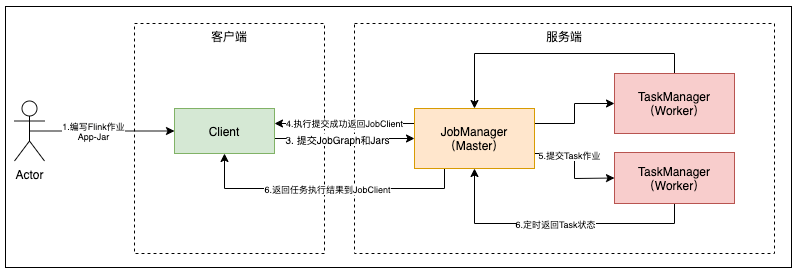
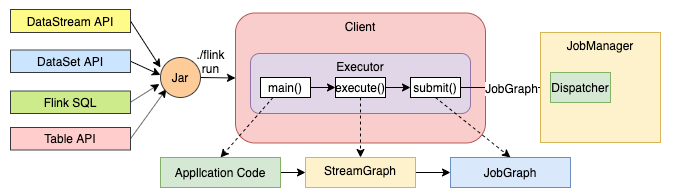
- Client:本地执行应用 main() 方法解析 JobGraph 对象,并最终将 JobGraph 提交到 JobManager 运行,同时监控 Job 执行的状态
- JobManager:管理节点,每个集群至少一个 JM,管理整个集群计算资源,Job 管理与调度执行,以及 Checkpoint 协调
- TaskManager:每个集群有多个 TM,负责提供计算资源
Client
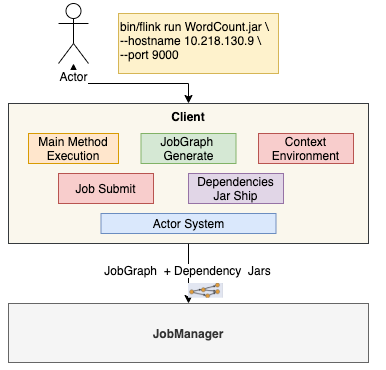
- Main Method Execution
- JobGraph Generate
- Execution Environment
- Job Submit
- Dependeny Jar Ship
- Actor System(RPC 通信)
- 负责网络的通信
JobManager
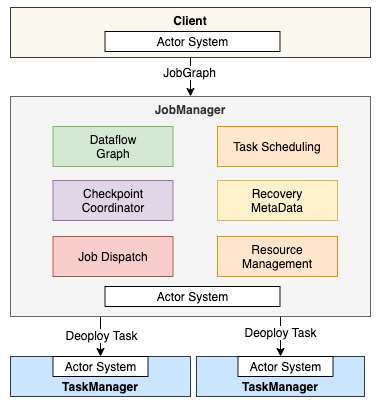
- Dataflow Graph
- 将 JobGraph 转换成 Execution Graph(JobGraph -> ExecutionGraph), 最终将运行 Execution Graph
- Task Scheduling
- 负责 Task 的调度
- Checkpoint Coordinator
- 负责协调整个任务的 Checkpoint, 包括 Checkpoint 的开始和完成
- Recovery Metadata
- 用于进行故障恢复时, 可以从 Metadata 里面读取数据
- Resource Management
- 集群资源管理
- Job Dispatch
- Job 接收
- Actor System(RPC 通信)
- 负责网络的通信
TaskManager
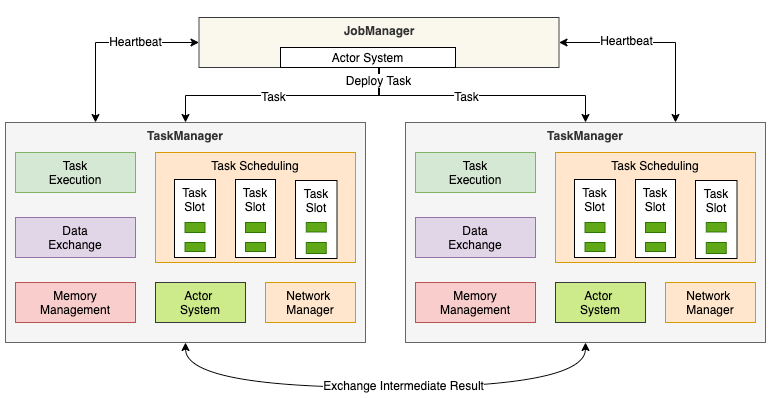
- Task Execution
- 执行 Task
- Data Exchange
- Memory Management
- 内存 I/O 的管理
- Actor system(RPC 通信)
- 负责网络的通信
- Network Manager
- 网络方面进行管理
- TaskSlot
- TaskManager 被分成很多个 TaskSlot, 每个任务都要运行在一个 TaskSlot 里面,TaskSlot 是调度资源里的最小单位
JobGraph
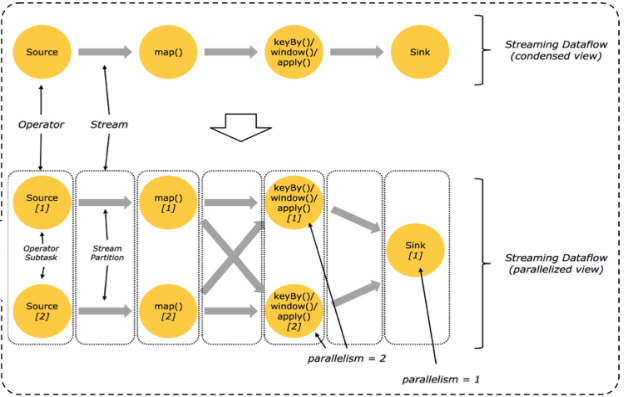
- 通过有向无环图 (Dag ) 方式表达用户程序
- 不同接口程序的抽象表达
- 客户端和集群之间的 Job 描述载体
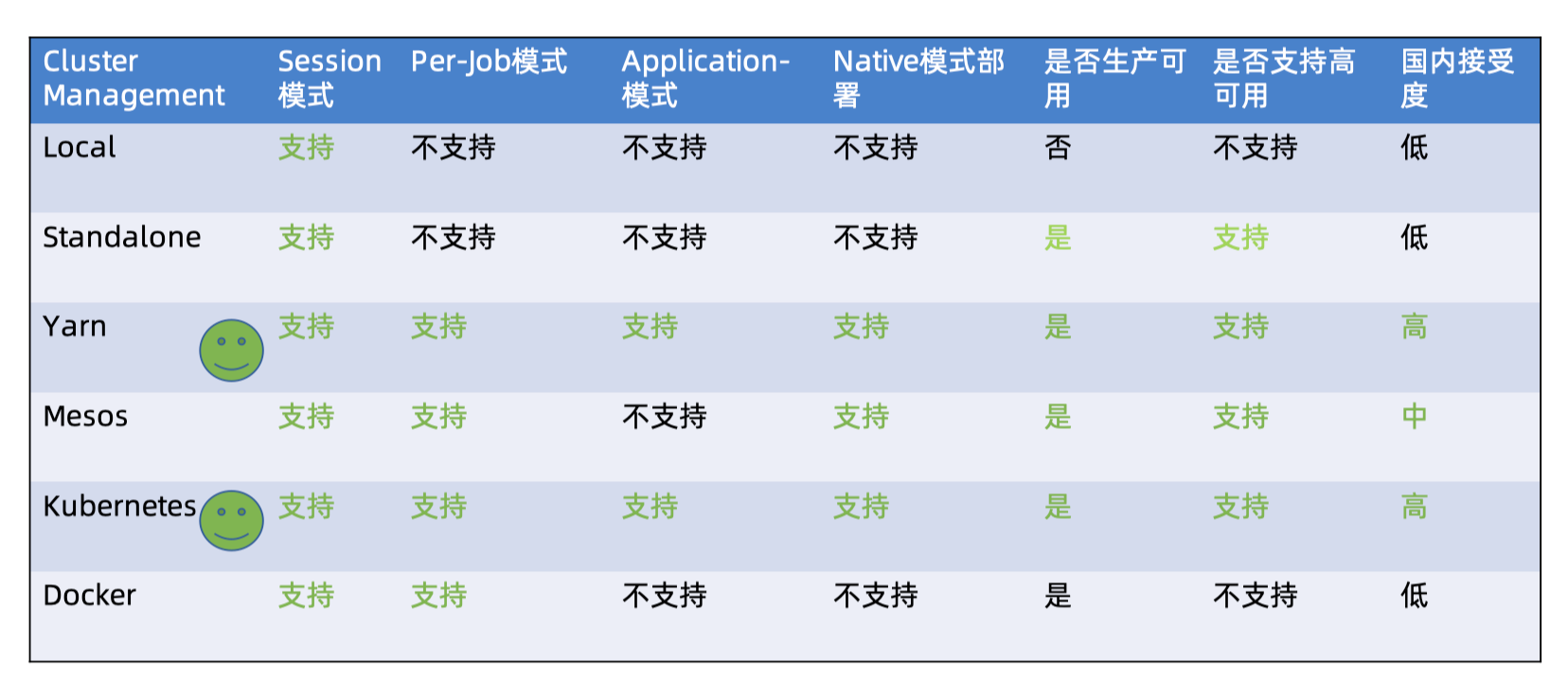
Flink 集群部署模式
集群部署模式根据以下两种条件进行分类
- 集群生命周期和资源隔离
- 应用程序的 main() 方法是在 Client 还是在 JobManager 上执行

集群部署模式可以分为三种类型
- Session 模式
- 集群生命周期独立于运行在集群上的作业的生命周期,并且资源在所有作业之间共享
- 应用程序的 main() 方法在 Client 上执行
- Per-Job 模式
- 为每个提交的 Job 启动一个集群,提供了更好的隔离保证,因为资源不会在 Job 之间共享,集群的生命周期与 Job 的生命周期绑定,Job完成后,集群将被关闭并清理资源
- 应用程序的 main() 方法在 Client 上执行
- Application 模式(Flink 1.11+)
- 为每个 Application 创建一个集群,Application 间实现资源隔离,Application 中实现资源共享(可以含有多个 Job)
- 应用程序的 main() 方法在 JobManager 上执行
Session 模式
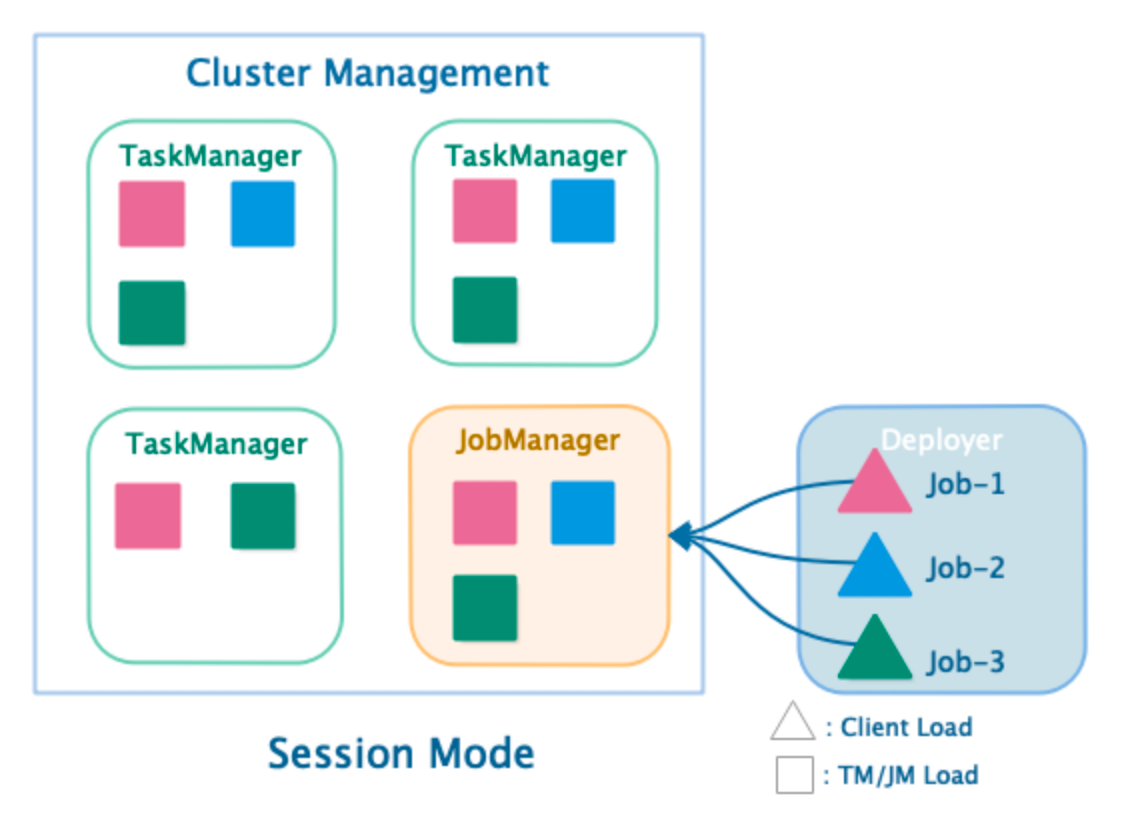
Session 部署模式
- 共享 JobManager 与 TaskManager,因此存在竞争
- 客户端通过 RPC 或 Rest APl 连接集群的管理节点
- Deployer 需要上传依赖的 Dependences Jar
- Deployer 需要生成 jobGraph,并提交到管理节点
- JobManager 的生命周期不受提交的 Job 影响,会长期运行
Session 部署模式优点
- 资源充分共享,提升资源利用率
- Job 在 Flink Session 集群中管理,运维简单
Session 部署模式缺点
- 资源隔离相对较差,Job 之间可能会相互影响
- 如果一个作业异常或关闭了 TaskManager,在该 TaskManager 上运行的所有作业都将受到影响
- 一个 JobManager 管理所有 Job,负载相对较大
- 非 Native 类型部署,TM 不易拓展,Slot 计算资源伸缩性较差
Per-Job 模式(首选模式)
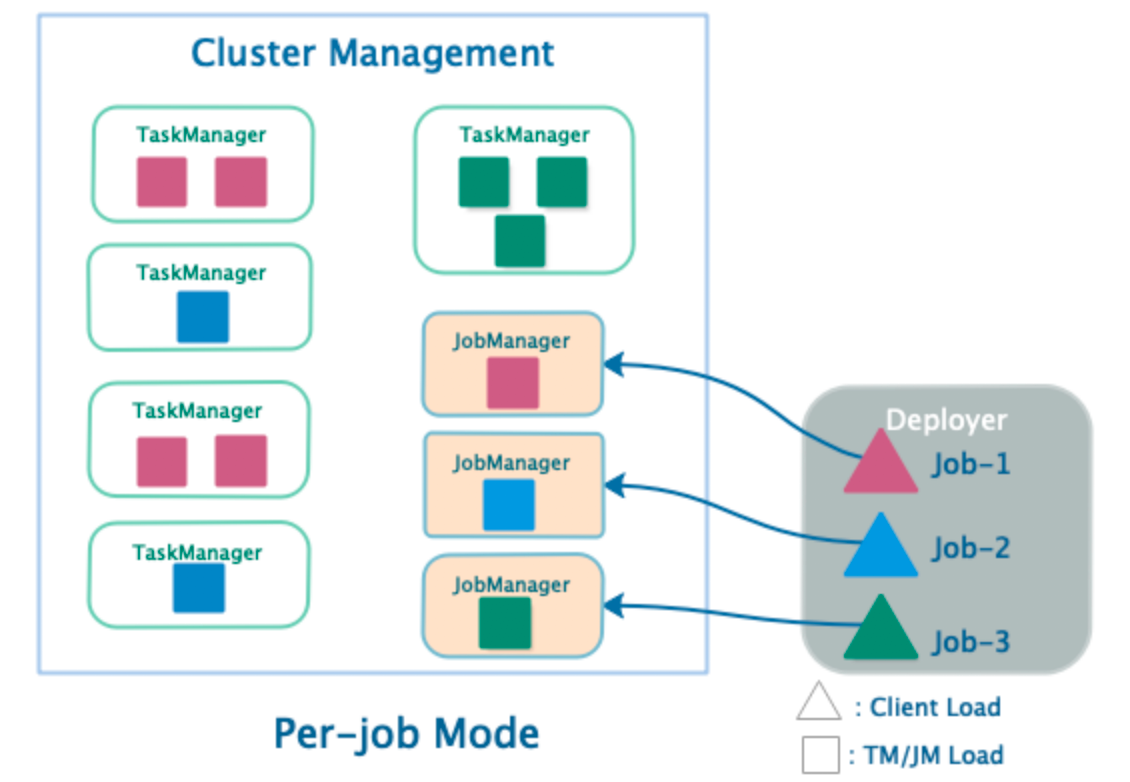
Per-Job 部署模式
- 单个 Job 独享JobManager 与 TaskManager
- TaskManager 中 Slot 资源根据 Job 指定
- Deployer 需要上传依赖的 Dependences Jar
- 客户端生成 JobGraph,并提交到管理节点
- JobManager 的生命周期和 Job 生命周期绑定
Per-Job 部署模式优势
- Job 和 Job 之间资源隔离充分,Job 之间不会相互影响
- 异常的 Job 只会导致自己的 TaskManager 崩溃
- 资源根据 Job 需要进行申请,TM Slots 数量可以不同
- 每个 JobManager 只管理自己的 Job,负载相对较小
Per-Job 部署模式劣势
- 资源相对比较浪费,JobManager 需要消耗资源
- Job 管理完全交给 ClusterManagement,管理复杂
Session 集群和 Per-Job 集群的问题
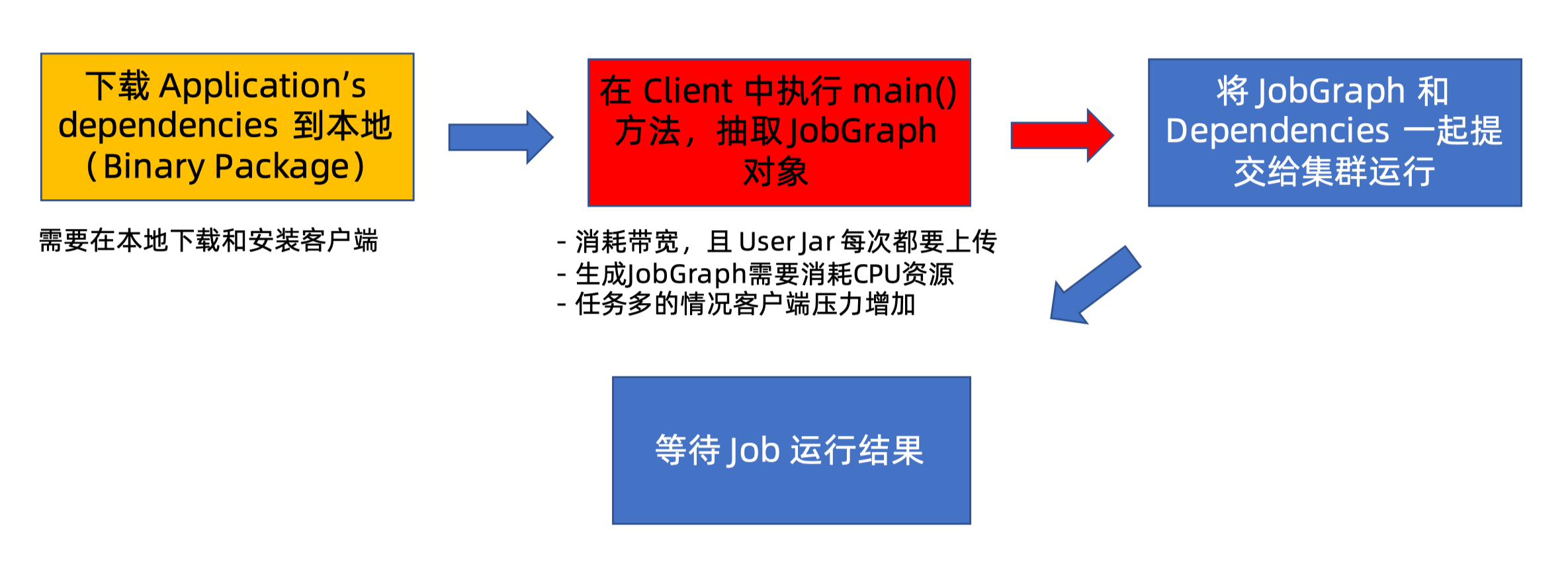
在所有其他模式下,应用程序的 main() 方法在客户端执行
- 在本地下载应用程序的依赖
- 执行 main() 以提取 Flink 运行时可以理解的应用程序表示(即 JobGraph)
- 将依赖和 JobGraph 发送到集群
存在的问题,当客户端在用户之间共享时会更加明显
- 可能需要大量的网络带宽来下载依赖并将二进制文件发送到集群
- 执行 main() 并生成 JobGraph 要消耗 CPU 资源
Application 模式
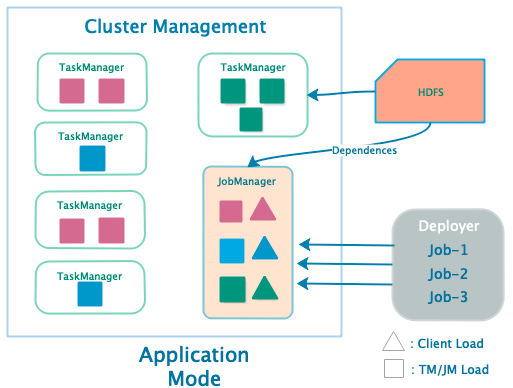
Application 部署模式 (Flink 1.11+)
- 每个 Application 对应一个 JobManager,且可以运行多个 Job
- 客户端无需将 Dependencies 上传到 JobManager ,仅负责管理 Job 的提交与管理
- 应用程序的 main() 方法在 JobManager 上执行,将 JobGraph 的生成放在集群上运行,客户端压力降低
Application 部署模式优点
- 可以通过 JobManager 将网络负载分散到整个集群,有效降低带宽消耗和客户端负载
- Application 间实现资源隔离,Application 中实现资源共享
Application 部署模式缺点
- 功能太新,还未经过生产验证
- 仅支持 Yarn 和 Kubunetes
在应用程序模式中,main() 是在集群上执行的,而不像在其他模式中那样在客户机上执行。 这可能会对你的代码产生影响,例如,你使用 registerCachedFile() 在环境中注册的任何路径都必须可由应用程序的 JobManager 访问
应用程序模式允许 multi-execute() 应用程序,但在这种情况下不支持高可用性。 只有 single-execute() 应用程序支持应用程序模式下的高可用性
此外,当应用程序模式下多个正在运行的作业(例如使用 executeAsync() 提交)中的任何一个被取消时,所有作业都将停止并且 JobManager 将关闭
Flink 集群资源管理器
Flink 支持的资源管理器
- Local
- 本地 minicluster
- Standalone
- Standalone
- Docker
- Non-Native Kubernetes
- Hadoop Yarn
- Native Kubernetes
- Apache Mesos
Flink 集群部署方案对比
Native 集群部署
- 当启动 Session 集群时,只启动 JobManager,不启动 TaskManager
- Session 集群根据实际提交的 Job 动态申资源请,并启动 TaskManager 以满足计算需求
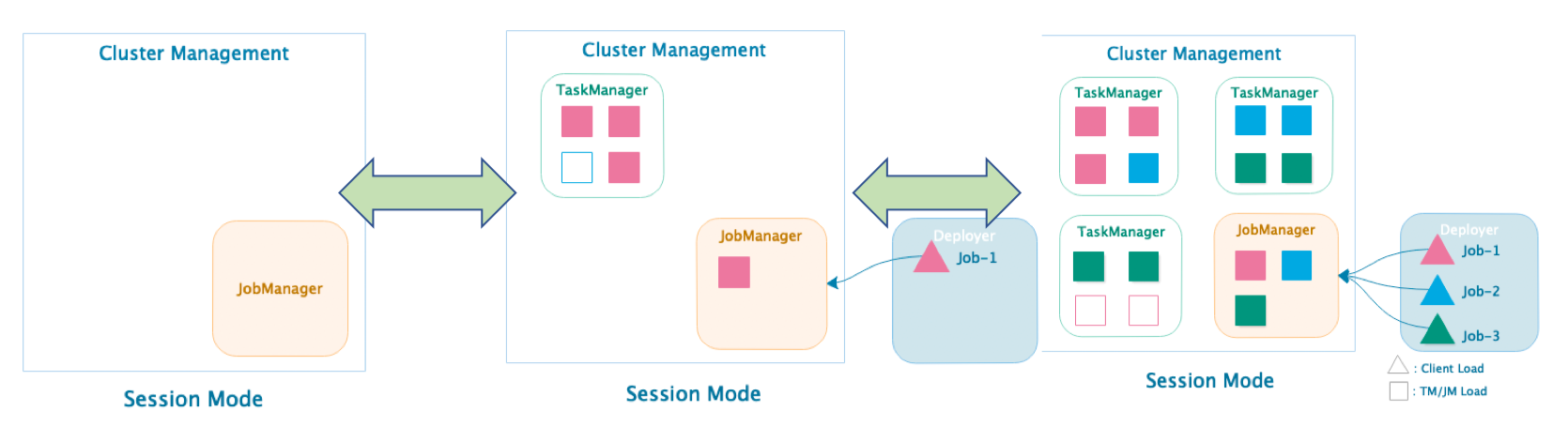
- 提交 Job-1 后根据Job 的资源申请,动态启动 TaskManager 满足计算需求
- 提交 Job-2,Job-3 后,再次向 ClusterManagement 申请 TaskManager 资源
Flink on Yarn 原理及实践
Yarn 架构原理
Yarn 架构原理 - 组件
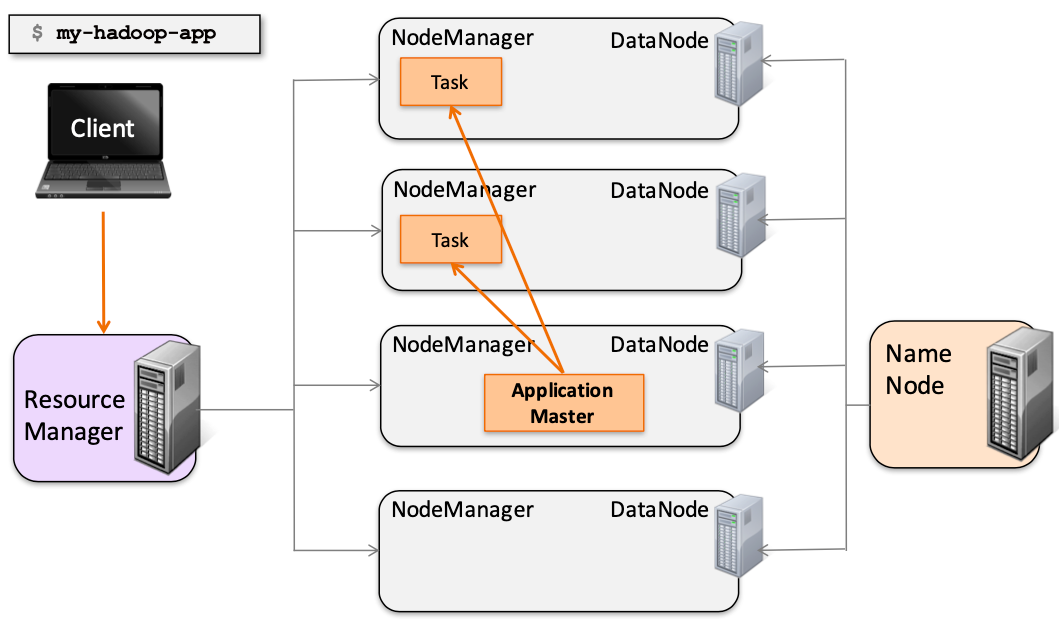
ResourceManager (RM)
- 负责处理客户端请求
- 启动/监控 ApplicationMaster
- 监控 NodeManager
- 资源的分配与调度,包含 Scheduler 和 Applications Manager
NodeManager (NM)
- 运行在 Worker 节点上
- 管理单个 Worker 节点上的资源
- ApplicationMaster/ResourceManager 通信
- 汇报资源状态
ApplicationMaster (AM)
- 运行在 Worker 节点上
- 负责数据的切分
- 为应用申请计算资源,并分配给 Task
- 任务监控和容错
Container
- 负责对资源进行抽象,包括内存、CPU、磁盘,网络等资源
Yarn 架构原理 - 交互
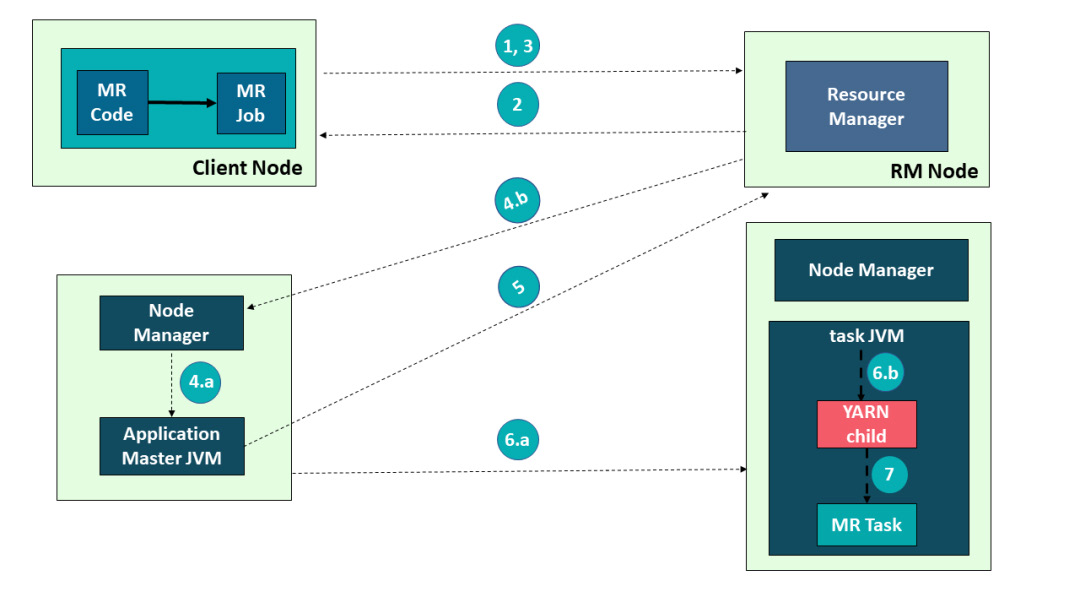
以在 Yarn 上运行 MapReduce 任务为例来讲解下 Yarn 架构的交互原理:
- 用户编写 MapReduce 代码后,通过 Client 端进行任务提交
- ResourceManager 在接收到客户端的请求后, 会分配一个 Container 用来启动 ApplicationMaster,并通知 NodeManager 在这个 Container 下启动 ApplicationMaster
- ApplicationMaster 启动后, 向 ResourceManager 发起注册请求。 接着 ApplicationMaster 向 ResourceManager 申请资源。 根据获取到的资源和相关的 NodeManager 通信,要求其启动程序
- 一个或者多个 NodeManager 启动 Map/Reduce Task
- NodeManager 不断汇报 Map/Reduce Task 状态和进展给 ApplicationMaster
- 当所有 Map/Reduce Task 都完成时,ApplicationMaster 向 ResourceManager 汇报任务完成,并注销自己
Flink on Yarn:Per-Job 模式
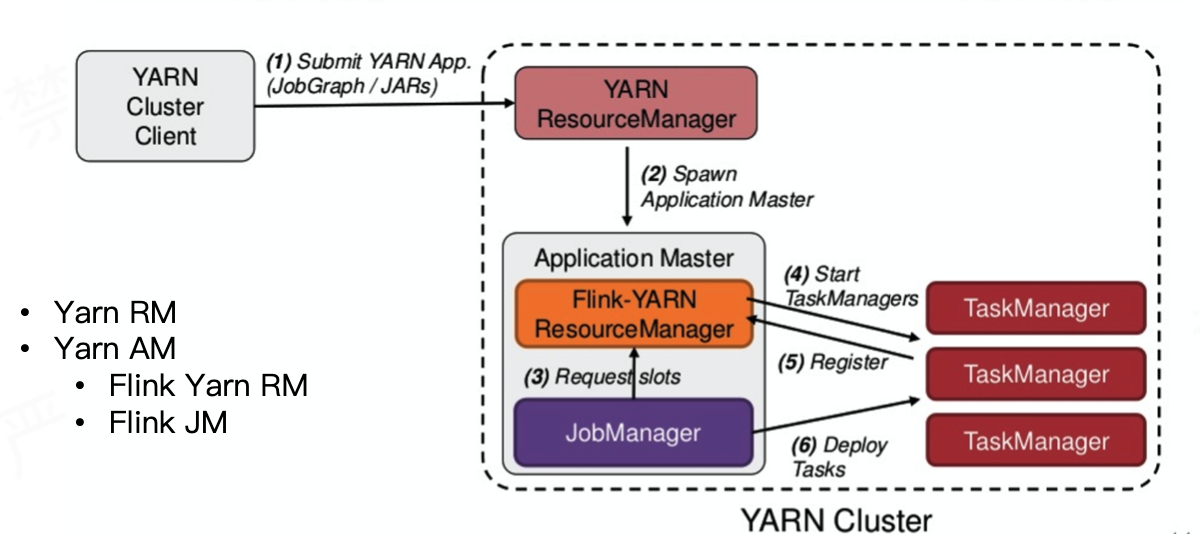
Per-Job 模式的特点
- 单个 JobManager 独享 YarnResourceManager 和 Dispatcher
- Application Master 与 Flink Master 节点处于同一个 Container
Per-Job 模式的流程具体如下
- 首先 Client 提交 Job,比如 JobGraph 或者 JARs
- 接下来 Yarn 的 ResourceManager 会申请第一 个 Container。 这个 Container 通过 Application Master 启动进程,Application Master 里面运行的是 Flink 程序,即 Flink-Yarn ResourceManager 和 JobManager
- 最后 Flink-Yarn ResourceManager 向 Yarn ResourceManager 申请资源。当分配到资源后,启动 TaskManager。TaskManager 启动后向 FlinkYarn ResourceManager 进行注册,注册成功后 JobManager 就会分配具体的任务给 TaskManager 开始执行
Flink on Yarn:Session 模式
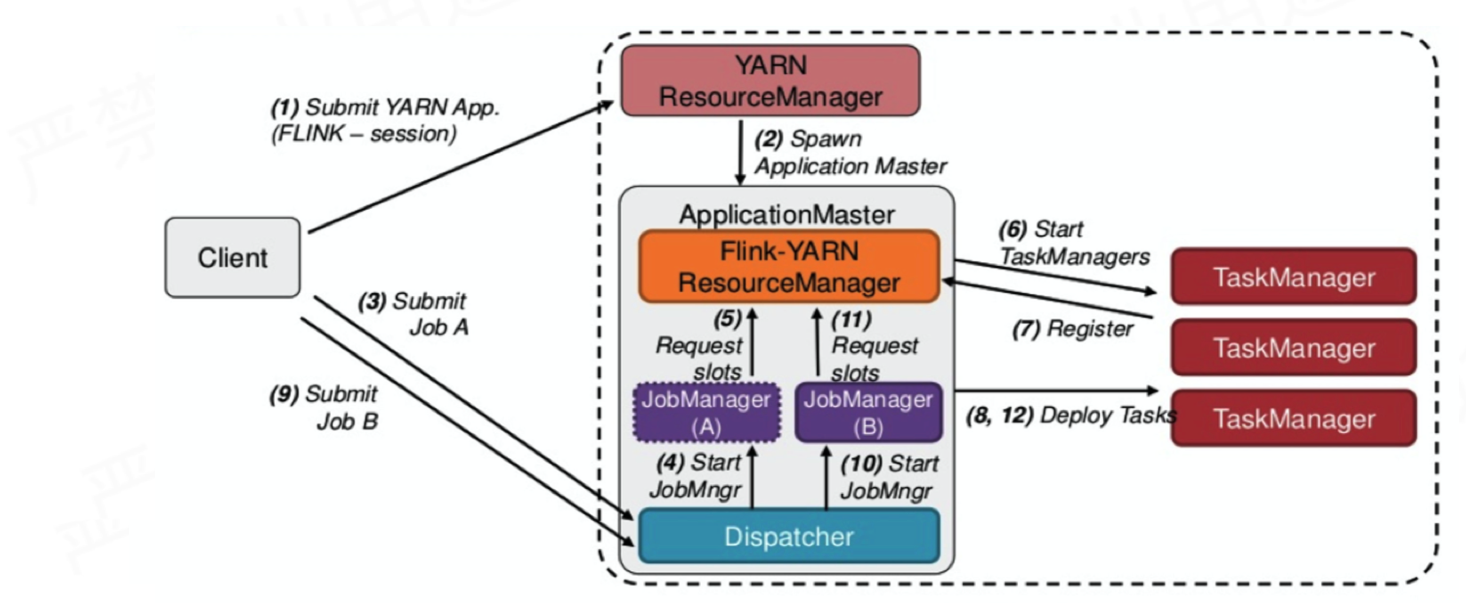
Session 模式的特点
- 多 JobManager 共享 Dispatcher 和 YarnResourceManager,资源会一直存在不会释放
- 支持 Native 模式,TM 动态申请
Session 模式的流程
- 首先 Client 提交 Job A
- 当 Dispatcher 在收到请求之后, 会启动 JobManager
- 接着 JobManager(A) 进程向 Flink-YARN ResourceManager 申请资源来启动 TaskManager
- TaskManager 启动之后,会有一个注册的过程,注册之后 JobManager 再将具体的 Task 任务分发给这个 TaskManager 去执行
- Client 提交 Job B,接着会启动 JobManager(B) 和对应的 TaskManager 的运行
- 当 A、B 任务运行完成后, 资源并不会释放。Session 模式也称为多线程模式
Session 模式和 Per-Job 模式的应用场景
- Per-Job 模式比较适合那种对启动时间不敏感,运行时间较长的任务
- Seesion 模式适合短时间运行的任务,一 般是批处理任务
若用 Per-Job 模式去运行短时间的任务,那就需要频繁的申请资源,运行结束后,还需要资源释放,下次还需再重新申请资源才能运行。显然,这种任务会频繁启停的情况不适用于 Per-Job 模式,更适合用 Session 模式
Flink On Yarn 优势与劣势
主要优势
- 与现有大数据平台无缝对接 (Hadoop2.4+)
- 基于 Native方式,TaskManager 资源按需申请和启动,防止资源浪费
- 资源的统一管理和调度,提高集群资源利用率
- Yarn 集群中所有节点的资源(内存、CPU、磁 盘、网络等)被抽象为 Container
- 计算框架需要资源进行运算任务时需要向 Resource Manager 申请 Container,Yarn 按照特定的策略对资源进行调度和进行 Container 的分配
- Yarn 模式能通过多种任务调度策略来利用提高集群资源利用率。 例如 FIFO Scheduler、Capacity Scheduler、Fair Scheduler,并能设置任务优先级
- 借助于 Hadoop Yarn 提供的自动 failover 机制,能保证 JobManager,TaskManager 节点异常恢复
- 例如 Yarn NodeManager 监控、Yarn ApplicationManager 异常恢复
- 资源隔离
- Yarn 使用了轻量级资源隔离机制 Cgroups 进行资源隔离以避免相互干扰,一旦 Container 使用的资源量超过事先定义的上限值,就将其杀死
主要劣势
- 资源隔离问题,尤其是网络资源的隔离,Yarn 做的还不够完善
- 离线和实时作业同时运行相互干扰等问题需要重视
- Kerberos 认证超期问题导致 Checkpoint无法持久化
- 运维部署成本较高,灵活性不够

若有收获,就点个赞吧
0 人点赞
