环境概览
操作系统
Ubuntu Server 20.04.3 LTS 64 bit 操作系统部署的版本
| 软件 | 版本 | 获取方法 |
|---|---|---|
| OpenJDK | 1.8.0_312 | sudo apt update sudo apt install openjdk-8-jdk |
| ZooKeeper | 3.4.6 | 在ZooKeeper官网下载所需版本的软件包。 下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz |
| Hadoop | 3.1.3 | 在Hadoop官网下载所需版本的软件包。 下载地址:https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz |
| Flink | 1.14.4 | 在Flink官网下载所需版本的软件包。 下载地址:https://archive.apache.org/dist/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.12.tgz |
集群环境规划
| 机器名称 | IP地址 | 硬盘数 |
|---|---|---|
| node01 | IPaddress1 | 系统盘:1 * 1000 GB 性能型本地盘 |
| node02 | IPaddress2 | |
| node03 | IPaddress3 | |
| node04 | IPaddress4 | |
| node05 | IPaddress5 |
软件规划
| 机器名称 | 服务名称 |
|---|---|
| node01 | + NameNode + SecondaryNameNode + ResourceManager + JournalNode + NodeManager + QuorumPeerMain + DataNode |
| node02 | + JournalNode + NodeManager + QuorumPeerMain + DataNode |
| node03 | + JournalNode + NodeManager + QuorumPeerMain + DataNode |
| node04 | + JournalNode + NodeManager + QuorumPeerMain + DataNode |
| node05 | + JournalNode + NodeManager + QuorumPeerMain + DataNode |
配置部署环境
依次登录节点 1-5,将节点的主机名分别修改为 node01、node02、node03、node04、node05
hostnamectl set-hostname 主机名 --static
登录所有节点,修改“/etc/hosts”文件
在 hosts 文件中添加集群所有节点的“地址-主机名”映射关系。
vi /etc/hosts
IPaddress1 node01IPaddress2 node02IPaddress3 node03IPaddress4 node04IPaddress5 node05
登录所有节点,关闭防火墙
- 关闭防火墙
sudo ufw disable
- 查看防火墙状态
sudo ufw status
登录所有节点,配置 SSH 免密登录
- 生成密钥,遇到提示时,按回车
ssh-keygen -t rsa
- 在每台机器上配置 SSH 免密登录(包括配置自身节点的免密)
ssh-copy-id -i ~/.ssh/id_rsa.pub root@节点IP
- 或者将所有节点的 ~/.ssh/id_rsa.pub 的密钥拷贝到 ~/.ssh/authorized_keys 文件中
cat ~/.ssh/id_rsa.pubvim ~/.ssh/authorized_keys
登录所有节点,安装 OpenJDK
- 安装 OpenJDK
sudo apt updatesudo apt install openjdk-8-jdk
- 查看 Java 安装位置
sudo which java/usr/lib/jvm/java-8-openjdk-amd64/bin/java
- 打开配置文件
vi /etc/profile
- 添加环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64export PATH=$JAVA_HOME/bin:$PATH
- 使环境变量生效
source /etc/profile
- 查看已安装 Java 版本
java -versionopenjdk version "1.8.0_312"OpenJDK Runtime Environment (build 1.8.0_312-8u312-b07-0ubuntu1~20.04-b07)OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
部署 ZooKeeper
下载并安装 ZooKeeper
- 下载并解压 ZooKeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gzmv zookeeper-3.4.6.tar.gz /usr/localcd /usr/localtar -zxvf zookeeper-3.4.6.tar.gz
- 建立软链接,便于后期版本更换
ln -s zookeeper-3.4.6 zookeeper
添加 ZooKeeper 到环境变量
- 打开配置文件
vi /etc/profile
- 添加 Hadoop 到环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeperexport PATH=$ZOOKEEPER_HOME/bin:$PATH
- 使环境变量生效
source /etc/profile
修改 ZooKeeper 配置文件
- 修改配置文件
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfgvi /usr/local/zookeeper/conf/zoo.cfg
- <font style="color:rgb(37, 43, 58);">修改数据目录。dataDir=</font>/usr/local/zookeeper/tmp- 配置 zookeeper 服务<font style="color:rgb(37, 43, 58);">,其中 server.1-5是部署 ZooKeeper 的节点</font>
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
server.4=node04:2888:3888
server.5=node05:2888:3888
# the directory where the snapshot is stored.dataDir=/usr/local/zookeeper/tmp# Place the dataLogDir to a separate physical disc for better performance# dataLogDir=/disk2/zookeeper# the port at which the clients will connectclientPort=2181# specify all zookeeper servers# The fist port is used by followers to connect to the leader# The second one is used for leader electionserver.1=node01:2888:3888server.2=node02:2888:3888server.3=node03:2888:3888server.4=node04:2888:3888server.5=node05:2888:3888
- 创建 zookeeper 数据目录
mkdir /usr/local/zookeeper/tmp
- 在数据目录中创建一个空文件,并根据上面的配置向该文件写入 ID,node01 写入 1,node02 写入 2,node03 写入 3,node04 写入 4,node05 写入 5
server.1=node01:2888:3888server.2=node02:2888:3888server.3=node03:2888:3888server.4=node04:2888:3888server.5=node05:2888:3888
如果未创建 myid 会报错:
./zkServer.sh start-foreground
ZooKeeper JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Invalid config, exiting abnormally
node01
touch /usr/local/zookeeper/tmp/myidecho 1 > /usr/local/zookeeper/tmp/myid
node02
touch /usr/local/zookeeper/tmp/myidecho 2 > /usr/local/zookeeper/tmp/myid
node03
touch /usr/local/zookeeper/tmp/myidecho 3 > /usr/local/zookeeper/tmp/myid
node04
touch /usr/local/zookeeper/tmp/myidecho 4 > /usr/local/zookeeper/tmp/myid
node05
touch /usr/local/zookeeper/tmp/myidecho 5 > /usr/local/zookeeper/tmp/myid
验证 ZooKeeper
- 分别在 node01,node02,node03,node04,node05 上启动 ZooKeeper
cd /usr/local/zookeeper/bin./zkServer.sh start
- 分别在 node01,node02,node03,node04,node05 上查看 ZooKeeper 状态
./zkServer.sh status
- 分别在 node01,node02,node03,node04,node05 上停止 ZooKeeper
./zkServer.sh stop
部署 Hadoop
下载并安装 Hadoop
- 下载并解压 Hadoop
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gzmv hadoop-3.1.3.tar.gz /usr/localcd /usr/localtar -zxvf hadoop-3.1.3.tar.gz
- 建立软链接,便于后期版本更换
ln -s hadoop-3.1.3 hadoop
添加 Hadoop 到环境变量
- 打开配置文件
vi /etc/profile
- 添加 Hadoop 到环境变量
export HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
- 使环境变量生效
source /etc/profile
修改 Hadoop 配置文件
切换到 Hadoop 配置文件目录
cd $HADOOP_HOME/etc/hadoop
修改 hadoop-env.sh
修改环境变量 JAVA_HOME 为绝对路径,并将用户指定为 root
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> hadoop-env.shecho "export HDFS_NAMENODE_USER=root" >> hadoop-env.shecho "export HDFS_SECONDARYNAMENODE_USER=root" >> hadoop-env.shecho "export HDFS_DATANODE_USER=root" >> hadoop-env.sh
修改 yarn-env.sh
修改用户为 root
echo "export YARN_REGISTRYDNS_SECURE_USER=root" >> yarn-env.shecho "export YARN_RESOURCEMANAGER_USER=root" >> yarn-env.shecho "export YARN_NODEMANAGER_USER=root" >> yarn-env.sh
修改 core-site.xml
- 编辑 core-site.xml 文件
echo "<?xml version=\"1.0\" encoding=\"UTF-8\"?><?xml-stylesheet type=\"text/xsl\" href=\"configuration.xsl\"?><configuration><property><name>fs.defaultFS</name><value>hdfs://node01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop/tmp</value></property><property><name>ipc.client.connect.max.retries</name><value>100</value></property><property><name>ipc.client.connect.retry.interval</name><value>10000</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property></configuration>" > core-site.xml
:::info
- fs.defaultFS:默认文件系统的名称
- hadoop.tmp.dir:本地数据存储目录
:::
- 在节点 node01 上创建目录
mkdir -p /data/hadoop/tmp
修改 hdfs-site.xml
- 编辑 hdfs-site.xml 文件
echo "<?xml version=\"1.0\" encoding=\"UTF-8\"?><?xml-stylesheet type=\"text/xsl\" href=\"configuration.xsl\"?><configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:///data/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///data/hadoop/dfs/data</value></property><property><name>dfs.http.address</name><value>node01:50070</value></property><property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property><property><name>dfs.datanode.handler.count</name><value>600</value></property><property><name>dfs.namenode.handler.count</name><value>600</value></property><property><name>dfs.namenode.service.handler.count</name><value>600</value></property><property><name>ipc.server.handler.queue.size</name><value>300</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property></configuration>" > hdfs-site.xml
:::info
- dfs.replication:hdfs 分片数
- dfs.namenode.name.dir:name 文件的存储位置
- dfs.datanode.data.dir:data 文件的存储位置
- dfs.blocksize:块大小
- dfs.namenode.secondary.http-address:secondary 的http的地址
:::
- 在所有节点上创建 dfs.datanode.data.dir 对应目录
mkdir -p /data/hadoop/dfs
修改 mapred-site.xml
- 编辑 mapred-site.xml 文件
echo "<?xml version=\"1.0\" encoding=\"UTF-8\"?><?xml-stylesheet type=\"text/xsl\" href=\"configuration.xsl\"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value><final>true</final><description>The runtime framework for executing MapReduce jobs</description></property><property><name>mapreduce.job.reduce.slowstart.completedmaps</name><value>0.88</value></property><property><name>mapreduce.application.classpath</name><value>/usr/local/hadoop/etc/hadoop,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,/usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*</value></property><property><name>mapreduce.map.memory.mb</name><value>6144</value></property><property><name>mapreduce.reduce.memory.mb</name><value>6144</value></property><property><name>mapreduce.map.java.opts</name><value>-Xmx5530m</value></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx2765m</value></property><property><name>mapred.child.java.opts</name><value>-Xmx2048m -Xms2048m</value></property><property><name>mapred.reduce.parallel.copies</name><value>20</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property></configuration>" > mapred-site.xml
修改 yarn-site.xml
- 编辑 yarn-site.xml 文件
echo "<?xml version=\"1.0\" encoding=\"UTF-8\"?><?xml-stylesheet type=\"text/xsl\" href=\"configuration.xsl\"?><configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><final>true</final></property><property><name>yarn.resourcemanager.hostname</name><value>node01</value></property><property><name>yarn.resourcemanager.bind-host</name><value>0.0.0.0</value></property><property><name>yarn.resourcemanager.am.max-attempts</name><value>10</value><description>The maximum number of application master execution attempts.</description></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>65536</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>102400</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>48</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.client.nodemanager-connect.max-wait-ms</name><value>300000</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>7.1</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>3072</value></property><property><name>yarn.app.mapreduce.am.resource.mb</name><value>3072</value></property><property><name>yarn.scheduler.maximum-allocation-vcores</name><value>48</value></property><property><name>yarn.application.classpath</name><value>/usr/local/hadoop/etc/hadoop,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,/usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/hadoop/yarn/local</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/hadoop/yarn/log</value></property></configuration>" > yarn-site.xml
- 在所有节点上创建 yarn.nodemanager.local-dirs 对应目录
mkdir -p /data/hadoop/yarn
修改 workers
- 修改 workers 文件,只保存所有主机名,其余内容均删除
echo "node01node02node03node04node05" > workers
- 在所有节点上创建 journaldata 目录
mkdir -p /usr/local/hadoop/journaldata
启动 Hadoop 集群
- 在所有节点上启动 ZooKeeper
cd /usr/local/zookeeper/bin./zkServer.sh start
:::color4
只在第一次进行格式化操作时,需要执行 2-4,完成格式化后,下次启动集群,只需要执行1、5、6:::
- 启动 JournalNode
观察进程是否都正常启动
cd /usr/local/hadoop/sbin./hadoop-daemon.sh start journalnode
root@node01:~# jps2270886 Jps23529 QuorumPeerMain26494 JournalNode
- 格式化 NameNode
bash
hdfs namenode -format
格式化后集群会根据 core-site.xml 配置的 hadoop.tmp.dir 参数生成目录,配置目录为“/data/hadoop/tmp”
:::info 解决 Apache Hadoop 启动时 DataNode 没有启动的问题(注意这会删除 HDFS 中原有的所有数据)-云社区-华为云
Hadoop namenode重新格式化需注意问题_火玄子的博客-CSDN博客
Hadoop重新格式化HDFS的方法 - 猎手家园 - 博客园
:::
- 格式化 ZooKeeper
hdfs zkfc -formatZK
:::info HDFS ZKFC实现NameNode自动切换原理 - 腾讯云开发者社区-腾讯云
:::
- 启动 HDFS,在 node01 节点上启动 HDFS
cd /usr/local/hadoop/sbin./start-dfs.sh
- 启动 Yarn,在 node01 节点上启动 Yarn
观察进程是否都正常启动
cd /usr/local/hadoop/sbin./start-yarn.sh
root@node01:~# jps27043 NameNode2270886 Jps28965 ResourceManager29174 NodeManager23529 QuorumPeerMain28715 SecondaryNameNode27260 DataNode26494 JournalNode
root@node02:~# jps26896 NodeManager25746 JournalNode26099 DataNode2153387 Jps22878 QuorumPeerMain
验证 Hadoop
在浏览器中输入URL地址,访问 Hadoop Web 页面,URL格式为“http://node01:50070”。 通过观察 Live Nodes 是否为 5、Dead Nodes是否为 0,判断集群是否正常启动。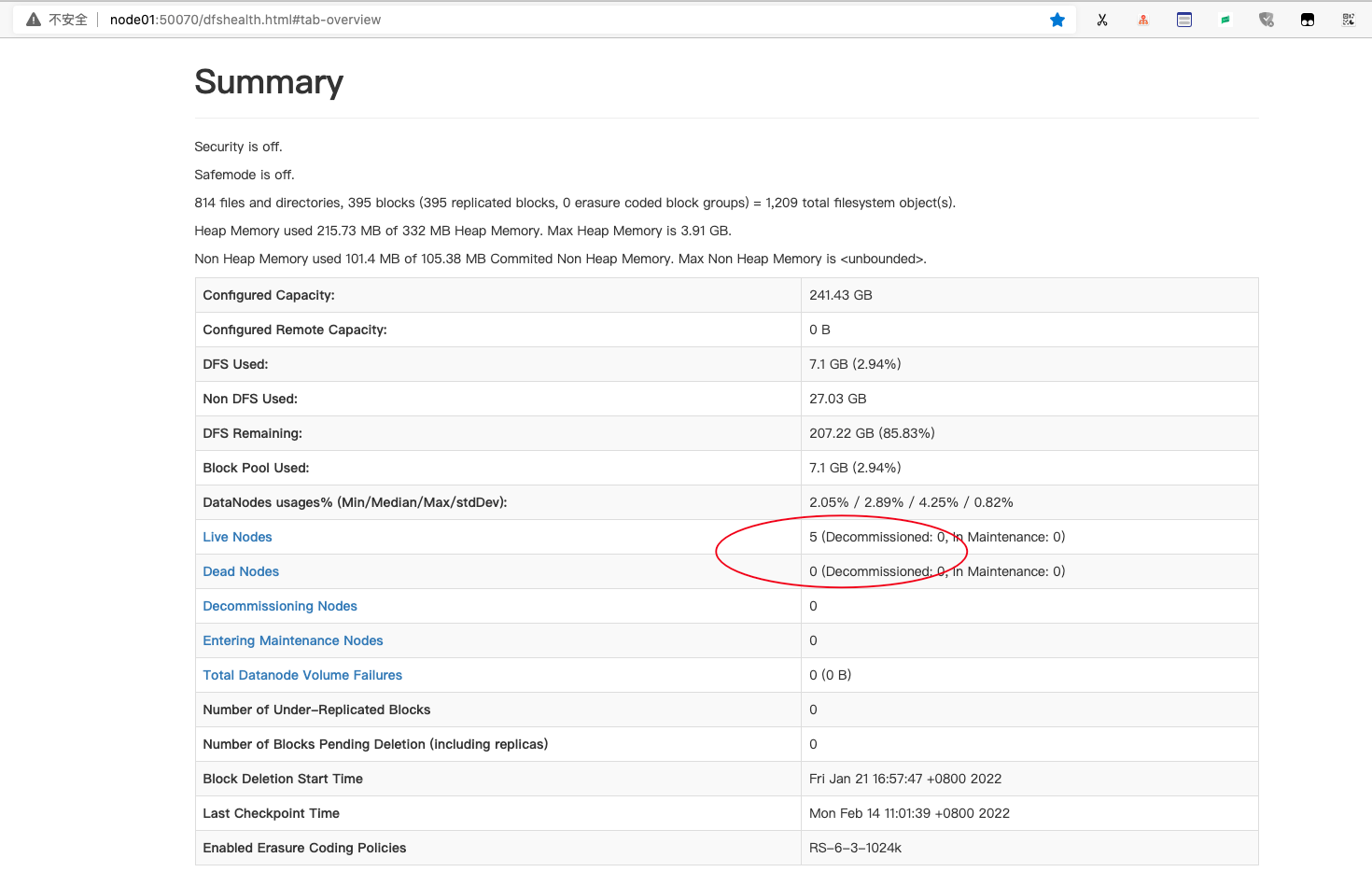
部署 Flink
下载并安装 Flink
- 下载并解压 Flink
wget https://archive.apache.org/dist/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.12.tgzmv flink-1.14.4-bin-scala_2.12.tgz /usr/localcd /usr/localtar -zxvf flink-1.14.4-bin-scala_2.12.tgz
- 建立软链接,便于后期版本更换
ln -s flink-1.14.4 flink
添加 Flink 到环境变量
- 打开配置文件
vi /etc/profile
- 添加 Flink 到环境变量
export FLINK_HOME=/usr/local/flinkexport PATH=$FLINK_HOME/bin:$PATHexport HADOOP_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
- 使环境变量生效
source /etc/profile
验证 Flink
- 依次启动 ZooKeeper 和 Hadoop
- 切换到 flink 安装路径
cd $FLINK_HOME
- 在 node01 上启动 Flink 集群
./bin/yarn-session.sh --detached
此时会返回一个 application-id,同时也会返回 JobManager Web Interface: http://node04:38677
- 在浏览器中输入 URL 地址,访问 Flink Web 页面,URL 格式如下所示
- 提交 job(在启动 flink 集群的节点上提交)
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
- 取消运行的 job
./bin/flink cancel $JOB_ID
- 停止 Flink 集群
echo "stop" | ./bin/yarn-session.sh -id application_XXXXX_XXX
参考文档
Flink 部署指南(CentOS 7.6&openEuler 20.03)鲲鹏BoostKit大数据使能套件部署指南(Apache)_华为云

若有收获,就点个赞吧
0 人点赞
