- org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
- replication slot 名字重复">replication slot 名字重复
- standby 连接数超过 max_wal_senders 配置的数量
- 连接器使用 CREATE PUBLICATION
FOR ALL TABLES; 创建发布,但由于缺少权限而失败 - Flink CDC 查询的时候报 read-only transaction 错误
- 查表的时候没有权限
- FATAL: remaining connection slots are reserved for non-replication superuser connections
- ERROR: replication slot “users” is active for PID 20795
- ERROR: all replication slots are in use
- 在扫描表的快照期间无法执行 checkpoint
- PostgreSQL 主节点 wal_level = replica,从节点 wal_level = logical
- Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded,Heartbeat of TaskManager with id container_xxx(hostname:43237) timed out.
- java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=37735267 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
- flink on yarn 模式下提示 yarn 资源不足问题分析">flink on yarn 模式下提示 yarn 资源不足问题分析
- org.postgresql.util.PSQLException: FATAL: must be superuser or replication role to start walsender
org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
- 报错:
org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
- 解决方法:
-- Flink SQLFlink SQL> SET execution.checkpointing.interval = 3s;
replication slot 名字重复
- 报错:
Causedby: org.postgresql.util.PSQLException: ERROR: replication slot "flink" already exists
- 解决方法:
查看 replication slot
postgres=# select * from pg_replication_slots;slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn-----------+----------+-----------+----------+----------+-----------+--------+------------+------+--------------+-------------+---------------------flink | pgoutput | logical | 15590180 | mydb | f | f | | | 30228717 | B7/6FFD7BE8 | B7/6FFD7C20users | pgoutput | logical | 3554061 | account | f | t | 20795 | | 30402293 | B7/9E0296E0 | B7/9E029718(2 rows)
通过 Connector 的 slot.name 参数配置 slot 名称,如果不设置默认名字为 flink
'slot.name' = 'test'
或者将名字为 flink 的 slot 删除即可
postgres=# select pg_drop_replication_slot('flink');pg_drop_replication_slot--------------------------(1 row)postgres=# select * from pg_replication_slots;slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn-----------+----------+-----------+----------+----------+-----------+--------+------------+------+--------------+-------------+---------------------users | pgoutput | logical | 3554061 | account | f | t | 20795 | | 30402293 | B7/9E0296E0 | B7/9E029718(1 rows)
standby 连接数超过 max_wal_senders 配置的数量
- 报错:
number of requested standby connections exceeds max_wal_senders (currently 8)
- 解决方法:
将 postgresql.conf 中的 max_wal_senders 改大
vim /pitrix/postgresql-10.4/data/postgresql.confmax_wal_senders = 16
然后重启 postgresql
systemctl restart postgresql
连接器使用 CREATE PUBLICATION FOR ALL TABLES; 创建发布,但由于缺少权限而失败
- 报错:
must be superuser to create FOR ALL TABLES publication
在使用 pgoutput 插件时,建议将过滤 publication.autocreate.mode 配置为 filtered。 如果使用 all_tables(publication.autocreate.mode 的默认值)并且未找到该发布,则连接器会尝试使用 CREATE PUBLICATION
- 解决方法:
将 Connector 的 debezium.publication.autocreate.mode 参数配置为 filtered
'debezium.publication.autocreate.mode' = 'filtered'
Flink CDC 查询的时候报 read-only transaction 错误
- 报错:
cannot execute CREATE PUBLICATION in a read-only transaction
- 解决方法:
关闭 read-only transaction
# 关闭系统级别的只读模式,数据库不需要重启也永久生效。postgres=# alter system set default_transaction_read_only=off;# 关闭 Session 级别的只读模式,退出 SQL 交互窗口后失效。postgres=# set session default_transaction_read_only=off;# 关闭指定登陆数据库的用户的只读模式,数据库不需要重启也永久生效。postgres=# alter user debezium set default_transaction_read_only=off;# 关闭指定数据库的只读模式postgres=# alter database account set default_transaction_read_only = off;
然后重载配置
postgres=# select pg_reload_conf();pg_reload_conf----------------t(1 row)postgres=# show default_transaction_read_only;default_transaction_read_only-------------------------------on(1 row)
:::color4 注意⚠️
必须连接主库,否则一样会报错
cannot execute CREATE PUBLICATION in a read-only transaction:::
参考文档
查表的时候没有权限
- 报错:
Permission denied for relation
- 解决方法:
给用户授予对应表的权限
GRANT ALL PRIVILEGES ON TABLE public.users TO debezium;
参考文档
FATAL: remaining connection slots are reserved for non-replication superuser connections
- 报错:
FATAL: remaining connection slots are reserved for non-replication superuser connections
- 解决方法:
通过这个命令终止所有的空闲连接
# 显示系统最大连接数show max_connections;# 当前总共正在使用的连接数select count(1) from pg_stat_activity;# 显示系统保留的用户数show superuser_reserved_connections;# 终止所有的空闲连接select pg_terminate_backend(pid) from pg_stat_activity;
或者将 postgresql.conf 中的 max_connections 改大一点,shared_buffers 的值也可能需要增加
vim /pitrix/postgresql-10.4/data/postgresql.confmax_connections = 2048
参考文档
ERROR: replication slot “users” is active for PID 20795
- 报错:
ERROR: replication slot "users" is active for PID 20795
- 解决方法
查看 replication slot
postgres=# select * from pg_replication_slots;slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn-----------+----------+-----------+----------+----------+-----------+--------+------------+------+--------------+-------------+---------------------flink | pgoutput | logical | 15590180 | mydb | f | f | | | 30228717 | B7/6FFD7BE8 | B7/6FFD7C20users | pgoutput | logical | 3554061 | account | f | t | 20795 | | 30402293 | B7/9E0296E0 | B7/9E029718test | pgoutput | logical | 20147811 | test | f | f | | | 30248941 | B7/755BCFB0 | B7/755BCFE8(3 rows)
将在使用名字为 users 的 slot 的程序停掉即可
ERROR: all replication slots are in use
Hint: Free one or increase max_replication_slots.
- 报错:
ERROR: all replication slots are in useHint: Free one or increase max_replication_slots.
- 解决方法:
释放 slot
postgres=# select * from pg_replication_slots;slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn-----------+----------+-----------+----------+----------+-----------+--------+------------+------+--------------+-------------+---------------------users | pgoutput | logical | 3554061 | account | f | t | 20795 | | 30402293 | B7/9E0296E0 | B7/9E029718(1 rows)postgres=# select pg_drop_replication_slot('flink');pg_drop_replication_slot--------------------------(1 row)
或者将 postgresql.conf 中的 max_replication_slots 改大一点
vim /pitrix/postgresql-10.4/data/postgresql.confmax_replication_slots = 2048
在扫描表的快照期间无法执行 checkpoint
- 报错:
Exceeded checkpoint tolerable failure threshold
- 解决方法:
Postgres CDC 在扫描全表数据时,是一次性读取完,没有可用于恢复的位点,所以无法在全表扫描阶段去执行 Checkpoint。
如果不执行 Checkpoint,则 Postgres CDC 的源表会让执行中的 Checkpoint 一直等待,甚至到 Checkpoint 超时(如果表超级大,扫描耗时非常长)。超时的 Checkpoint 会被认为是失败的 Checkpoint。而在 Flink 默认配置下,失败的 Checkpoint 会引发 Flink 作业 Failover。
因此,建议在表超大时,为了避免因为 Checkpoint 超时而导致作业失败,需要配置如下作业参数
SET execution.checkpointing.interval = 10min;SET execution.checkpointing.tolerable-failed-checkpoints = 100;SET restart-strategy = fixed-delay;SET restart-strategy.fixed-delay.attempts = 2147483647;
| 参数 | 说明 |
|---|---|
| execution.checkpointing.interval | Checkpoint 的时间间隔。 单位是 Duration 类型,例如 10min 或 30s。 |
| execution.checkpointing.tolerable-failed-checkpoints | 容忍 Checkpoint 失败的次数。 该参数的取值与 Checkpoint 调度间隔时间的乘积就是允许的快照读取时间。如果表特别大,这个可以配置大一些。 |
| restart-strategy | 重启策略,参数取值如下: + fixed-delay:固定延迟重启策略。 + failure-rate:故障率重启策略。 + exponential-delay:指数延迟重启策略。 详情请参见 Restart Strategies。 |
| restart-strategy.fixed-delay.attempts | 固定延迟重启策略下,尝试重启的最大次数。 |
PostgreSQL 主节点 wal_level = replica,从节点 wal_level = logical
- 报错:
- Flink CDC 连接主节点报错
org.postgresql.util.PSQLException: ERROR: logical decoding requires wal_level >= logical
- Flink CDC 连接从节点报错
org.postgresql.util.PSQLException: ERROR: logical decoding cannot be used while in recovery
主节点查看从节点情况,此时从节点正在异步同步
select * from pg_stat_replication ;pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state-------+----------+----------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+-----------+-----------+-----------+-----------+------------+-----------+-----------+------------+---------------+------------16342 | 10 | postgres | walreceiver | 172.31.60.108 | | 54272 | 2022-07-13 14:22:59.320299+08 | | streaming | B9/AF8C88 | B9/AF8C88 | B9/AF8C88 | B9/AF8C88 || | | 0 | async(1 row)
解决方案:
- 主节点修改为 wal_level = logical
vim /pitrix/postgresql-10.4/data/postgresql.confwal_level = logical
- Flink CDC 连接从节点报错
org.postgresql.util.PSQLException: ERROR: logical decoding cannot be used while in recovery
- 结论
PostgreSQL 连接器必须配置为逻辑复制并且只支持连接主库
:::color4 详细信息可以查看 debezium 官方文档
Debezium connector for PostgreSQL :: Debezium Documentation

PostgreSQL 连接器 限制
- 连接器依赖 PostgreSQL 逻辑解码特性,该特性有以下限制:
- 逻辑解码不支持 DDL 更改。 这意味着连接器无法将 DDL 更改事件报告回消费者。
- 只有主服务器支持逻辑解码复制槽。 当存在 PostgreSQL 服务器集群时,连接器只能在活动的主服务器上运行。 它不能在热备份或热备份副本上运行。 如果主服务器出现故障或降级,连接器将停止。 主服务器恢复后,你可以重新启动连接器。 如果已将其他 PostgreSQL 服务器提升为主服务器,请在重新启动连接器之前调整连接器配置。
- Debezium 目前仅支持使用 UTF-8 字符编码的数据库。 使用单字节字符编码,无法正确处理包含扩展 ASCII 代码字符的字符串。
:::
Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded,Heartbeat of TaskManager with id container_xxx(hostname:43237) timed out.
- 报错:
Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded,Heartbeat of TaskManager with id container_xxx(hostname:43237) timed out.
- 解决方法:
可能是内存不足导致,增加 JobManager 和 TaskManager 的内存
jobmanager.heap.size: 2048mtaskmanager.heap.size: 2048m
java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=37735267 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
- 报错:
java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=37735267 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
- 解决方法:
通过日志 Checkpoint storage is set to ‘jobmanager’ 可以发现此时存储后端使用的是 jobmanager(内存),使用文件系统存储后端即可
state.backend: rocksdbstate.checkpoints.dir: hdfs:///flink/checkpointsstate.savepoints.dir: hdfs:///flink/savepointsstate.backend.incremental: truejobmanager.execution.failover-strategy: region
flink on yarn 模式下提示 yarn 资源不足问题分析
- 报错:
(YarnClusterDescriptor.java:1036)- Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
点击对应的 Application 可以查看诊断信息

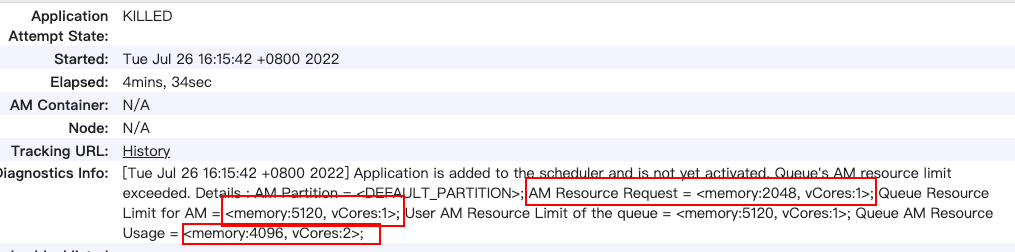
可以看到队列资源限制 Application Maste 的内存为 5120M,已经使用的内存为 4096M,申请的内存为 2048M(Jobmanager 的堆内存, jobmanager.heap.size: 2g),此时已经超了。
- 解决方法:
动态更新 capacity-scheduler.xml 配置的修改(除了动态减少队列数目外):
<property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.5</value></property>
yarn rmadmin -refreshQueues
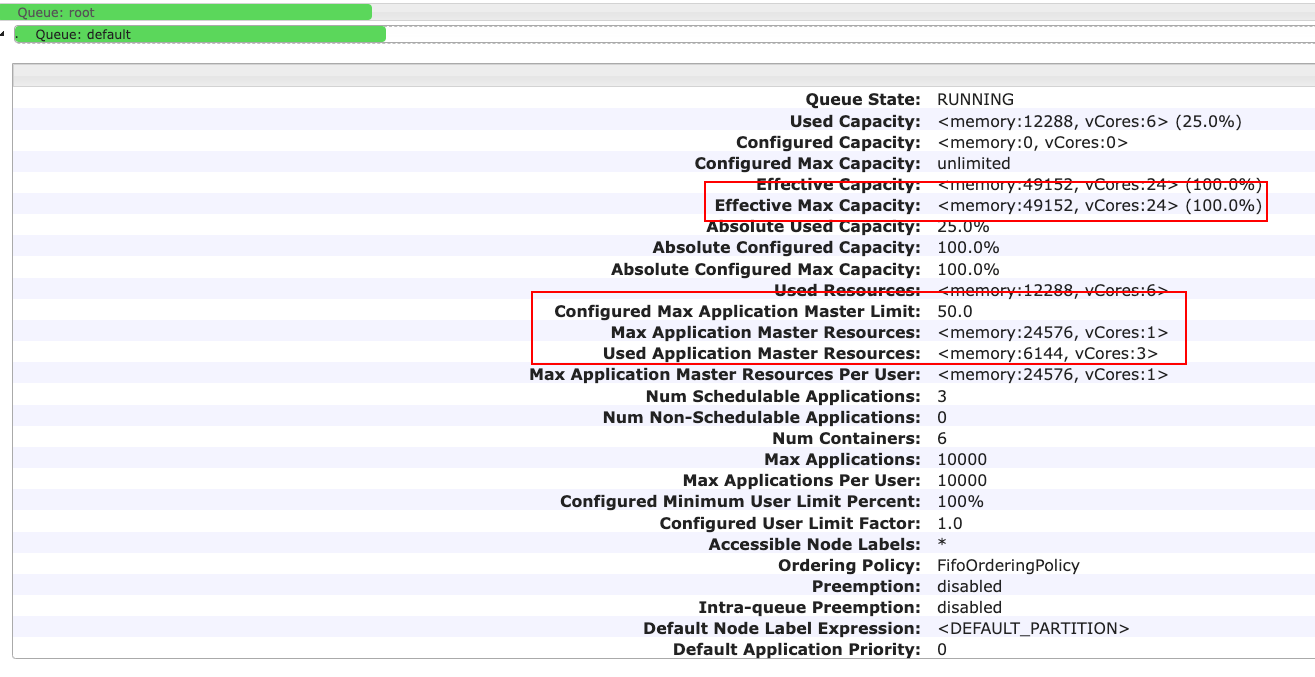
此时 Configured Max Application Master Limit: 50.0,即 maximum-am-resource-percent 配置为 0.5 生效了。队列资源限制 Application Maste 的内存为 24576M(49152M*0.5),已经使用的内存为 6144M。
也可以减少 Jobmanager 的堆内存大小,修改 conf/flink-conf.yaml
jobmanager.heap.size: 1g
参考文档
org.postgresql.util.PSQLException: FATAL: must be superuser or replication role to start walsender
报错:
org.postgresql.util.PSQLException: FATAL: must be superuser or replication role to start walsender
解决方法:
从日志上也可以看出,用户没有配置 replication 权限,添加 replication 权限即可
ALTER ROLE yunify WITH REPLICATION;

若有收获,就点个赞吧
0 人点赞
