Flink 社区中最常被问到的问题之一是如何在从开发阶段转向生产阶段时确定群集的规模。 这个问题的最终答案当然是“视情况而定”,但这并不是一个有用的答案。 这篇文章概述了一系列问题,帮助你获取一些可以用作指导的数字。
做计算并建立基线
第一步是仔细考虑应用程序的算子指标,以获得所需资源的基线。 要考虑的关键指标是:- 每秒记录数和每条记录的大小
- 你拥有的不同 key 的数量以及每个 key 的状态大小
- 状态更新的数量和状态后端的访问模式
最后,一个更实际的问题是你与客户之间关于停机时间、延迟和最大吞吐量的服务水平协议 (SLA),因为这些直接影响你的容量规划。
接下来,根据你的预算查看你可用的资源。例如:- 网络容量,需要考虑使用网络的其他外部服务,如 Kafka,HDFS 等。
- 磁盘带宽,如果你依赖 RocksDB 等基于磁盘的状态后端(并考虑使用其他磁盘,如 Kafka 或 HDFS)
- 机器的数量以及它们可用的 CPU 和内存
示例:让我们举一些例子
我现在将计划在假设的集群上部署作业,以可视化建立资源使用基准的过程。 这些数字是粗略的值,并且它们并不全面 - 在文章的最后,我还将指出一些我在计算时忽略的方面。 ## 示例 Flink 流式传输作业和硬件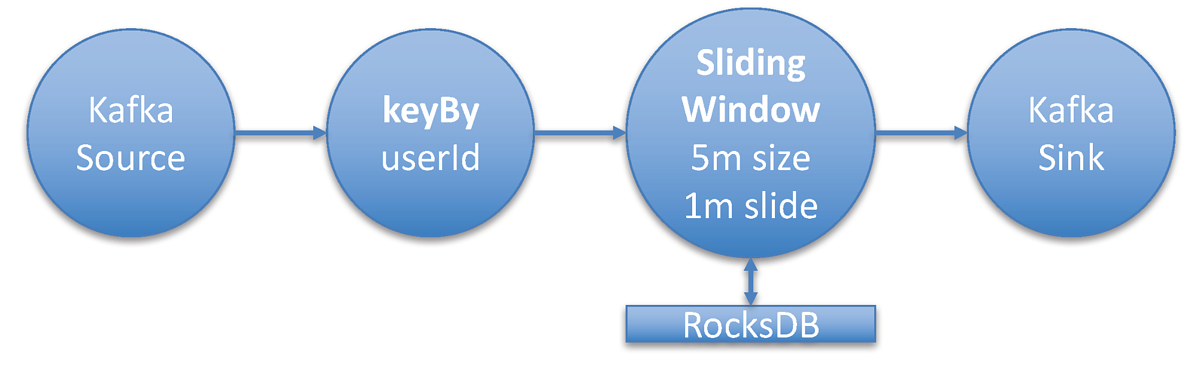 示例 Flink Streaming 作业拓扑
示例 Flink Streaming 作业拓扑
对于这个例子,我将部署一个典型的 Flink 流式作业,它使用 Flink 的 Kafka Consumer 从 Kafka 主题中读取数据。 然后使用 Key,聚合窗口算子转换流。 窗口算子在 5 分钟的时间窗口上执行聚合。 由于总是有新数据,我将窗口配置为滑动窗口,滑动时间为 1 分钟。
这意味着我将每分钟更新过去 5 分钟的聚合数据。 流式作业为每个 userId 创建一个聚合。 从 Kafka 主题消费的消息的大小(平均)为 2 KB。
吞吐量为每秒 100 万条消息。 要了解窗口算子的状态大小,你需要知道不同 Key 的数量。 在本例中,它是 userId 的数量,即 500,000,000 个唯一用户。 对于每个用户,你正在计算 4 个 long(8 个字节) 类型的整数 。
让我们总结一下这项工作的关键指标:
- Message size: 2 KB
- Throughput: 1,000,000 msg/sec
- Distinct keys: 500,000,000 (aggregation in window: 4 longs per key)
- Checkpointing: Once every minute.
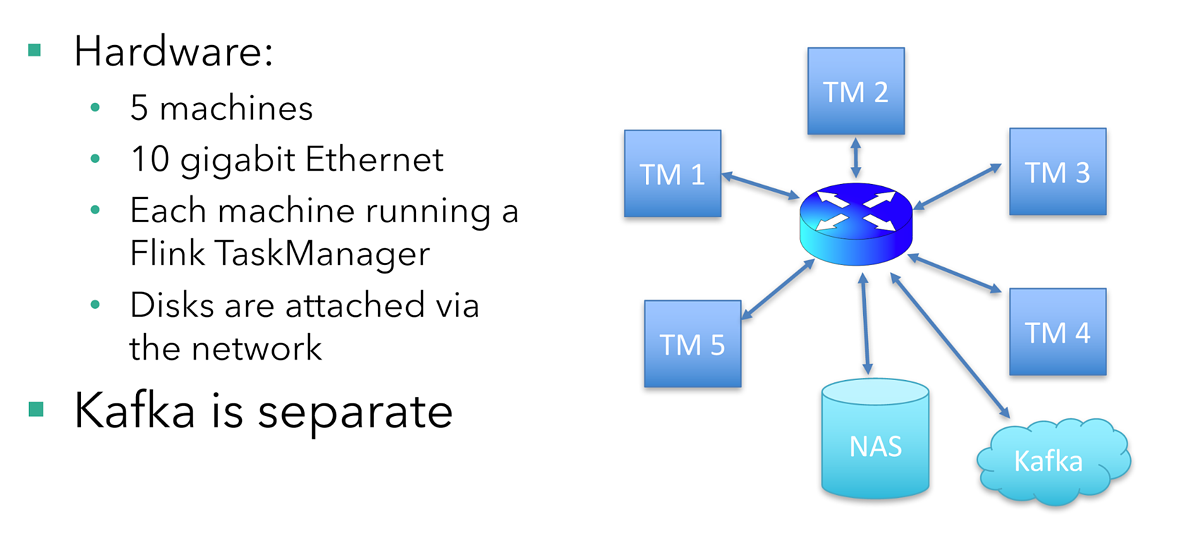
假设的硬件设置
有五台机器运行该作业,每台机器运行一个 Flink TaskManager(Flink 的工作节点)。 磁盘是网络连接的(在云设置中很常见),从主交换机到每台运行 TaskManager 的机器都有一个 10 Gigabit 以太网连接。 Kafka broker 运行在不同的机器上。
每台机器有 16 个 CPU 内核。 为简单起见,我不会考虑 CPU 和内存要求。 在现实世界中,根据你的应用程序逻辑和使用的状态后端,你需要注意内存。 此示例使用基于 RocksDB 的状态后端,该后端功能强大且内存要求低。
单机的视角
要了解整个作业部署的资源需求,最简单的方法是首先关注单台机器上单个 TaskManager 中的操作。 然后,你可以使用从一台机器得出的数字来计算总体资源需求。
默认情况下(如果所有算子都具有相同的并行度并且没有特殊的调度限制)流式作业的所有算子都可以在每台机器上运行。
在这种情况下,Kafka source(或 consumer )、窗口算子和 Kafka sink(或 producer)都在五台机器上运行。
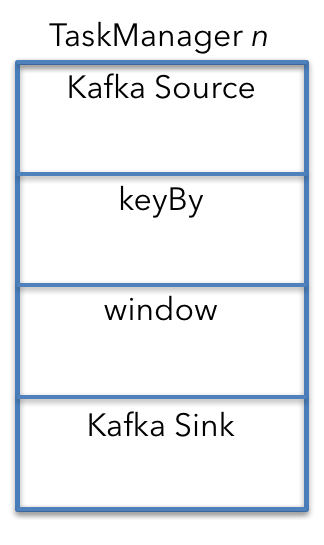
从机器的角度来看,TaskManager n 的 keyBy 在上图中是一个单独的算子,因此计算资源需求就更容易了。 实际上,keyBy 是一个 API,并转换为 Kafka source 和窗口算子之间连接的配置属性。
我现在将从上到下遍历这些算子,以了解他们的网络资源需求。
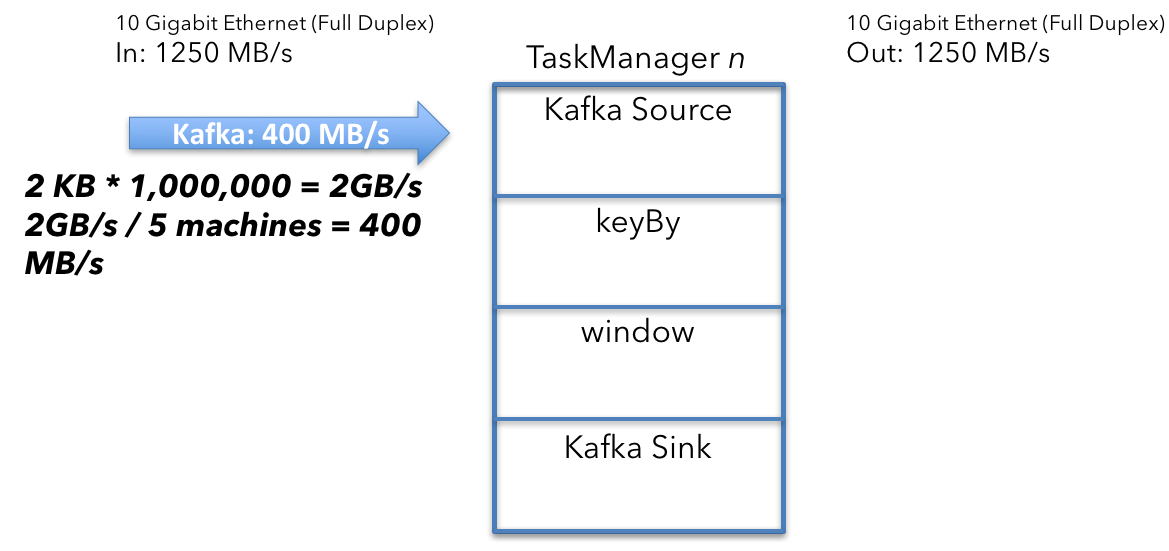
Kafka source
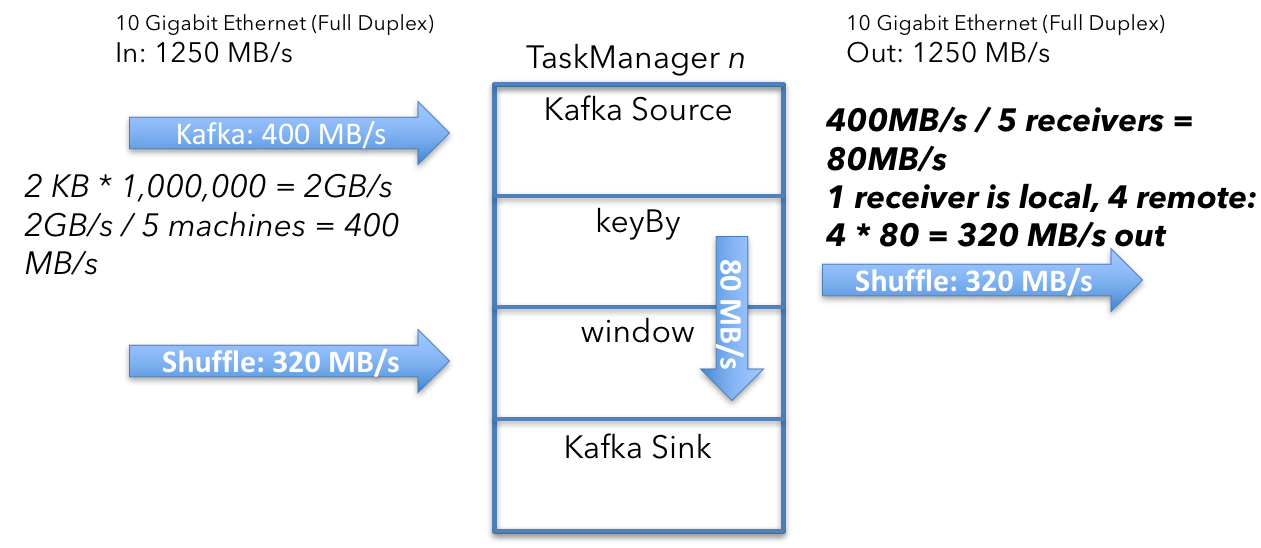
要计算单个 Kafka source 接收的数据量,首先,计算聚合 Kafka 输入。 source 每秒接收 1,000,000 条消息,每个消息大小为 2 KB。
2KB x 1,000,000/s = 2GB/s
将 2GB/s 除以机器数 (5) 得出以下结果:
2 GB/s ÷ 5 machines = 400 MB/s
集群中运行的 5 个 Kafka source 中的每一个都以 400 MB/s 的平均吞吐量接收数据。
Shuffle / keyBy
接下来,你需要确保具有相同 key(在本例中为 userId)的所有事件最终都在同一台机器上。 你正在读取的 Kafka 主题中的数据可能会根据不同的分区方案进行分区。
Shuffle 过程将具有相同 key 的所有数据发送到一台机器,因此你将来自 Kafka 的 400MB/s 数据流拆分为一个 userId 分区流:
400 MB/s ÷ 5 machines = 80 MB/s
平均而言,你必须向每台机器发送 80 MB/s 的数据。 这个分析是从单机角度分析的,也就是说部分数据已经在指定的目标机器上,所以减去 80MB/s 来解释:
400 MB/s - 80 MB = 320 MB/s
每台机器以 320MB/s 的速率接收和发送用户数据。
Shuffle 计算
Window Emit 和 Kafka Sink
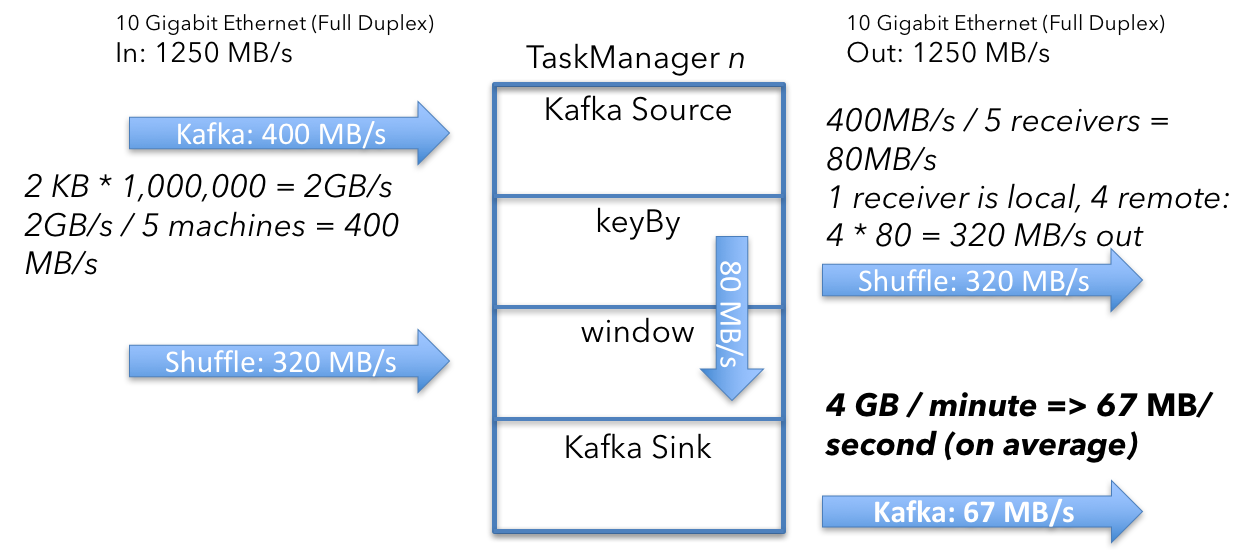
下一个要问的问题是窗口算子发出并发送到 Kafka 接收器的数据量。 它是 67 MB/s,让我们解释一下我们是如何得出这个数字的。
窗口算子为每个 key 保留 4 个 long 类型的整数的聚合。 每分钟一次,算子发出当前的聚合值。 每个 key 从聚合中发出 2 个 int(4 个字节)( user_id、window_ts )和 4 个 long (8 个字节)类型的整数:
(2 x 4 bytes) + (4 x 8 bytes) = 40 bytes per key
然后考虑每台机器上的 key(500,000,000 除以机器数量):
100,000,000 keys x 40 bytes = 4GB
然后计算每秒大小:
4 GB/min ÷ 60 = 67 MB/s
这意味着每个 TaskManager 平均从窗口算子发出 67 MB/s 的用户数据。 由于每个 TaskManager(在窗口算子旁边)上运行着一个 Kafka 接收器,并且没有进一步的重新分区,这就是从 Flink 发送到 Kafka 的数据量。
用户数据:从 Kafka,Shuffle 到窗口算子并返回到 Kafka
来自窗口算子的数据发送预计是“突发的”,因为它们每分钟发送一次数据。 在实践中,算子不会以 67 MB/s 的恒定速率发送数据,而是每分钟将可用带宽最大化几秒钟。
总计为:
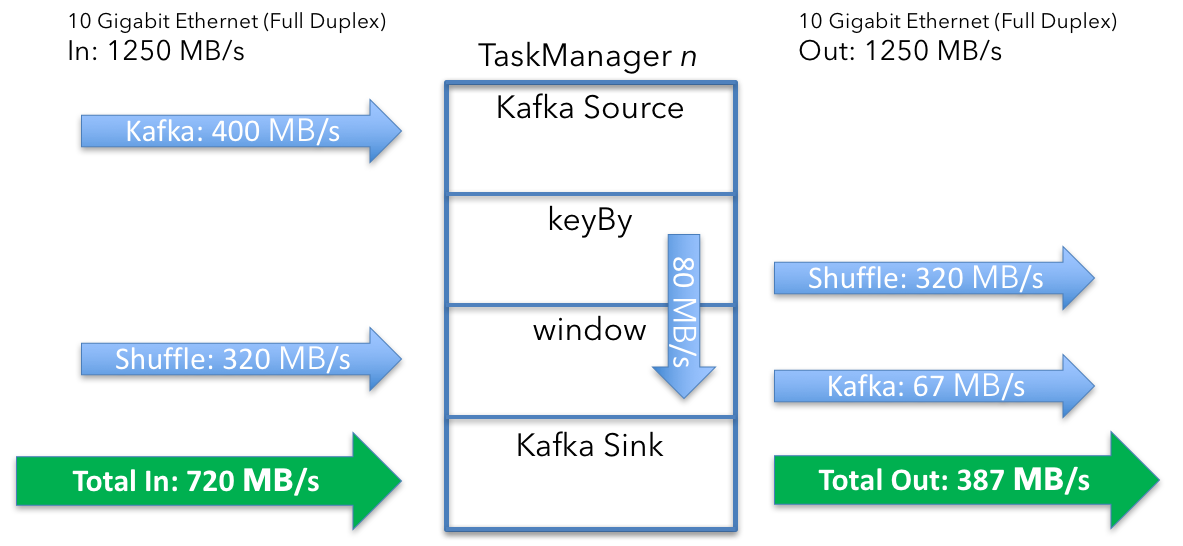
数据输入:每台机器 720 MB/s (400 + 320)数据输出:每台机器 387 MB/s (320 + 67)
状态访问和 Checkpoint
这还不是全部。 到目前为止,我只查看了 Flink 正在处理的用户数据。 你需要将 RocksDB 的磁盘访问开销包括在内(存储状态和 Checkpoint)。 要了解磁盘访问成本,请查看窗口算子如何访问状态。 Kafka source 也保留了一些状态,但与窗口算子相比可以忽略不计。
要了解窗口算子的状态大小,请从不同的角度来看。 Flink 正在用 1 分钟的滑动窗口,计算 5 分钟的窗口。 Flink 通过维护五个窗口来实现滑动窗口,每个滑动窗口一个。 如前所述,当使用执行急切聚合的窗口实现时,你为每个窗口和聚合的每个 key 维护 40 byte 的状态。 对于每个传入事件,你首先需要从磁盘检索当前聚合值(读取 40 byte),更新聚合,然后将新值写回(写入 40 byte)。
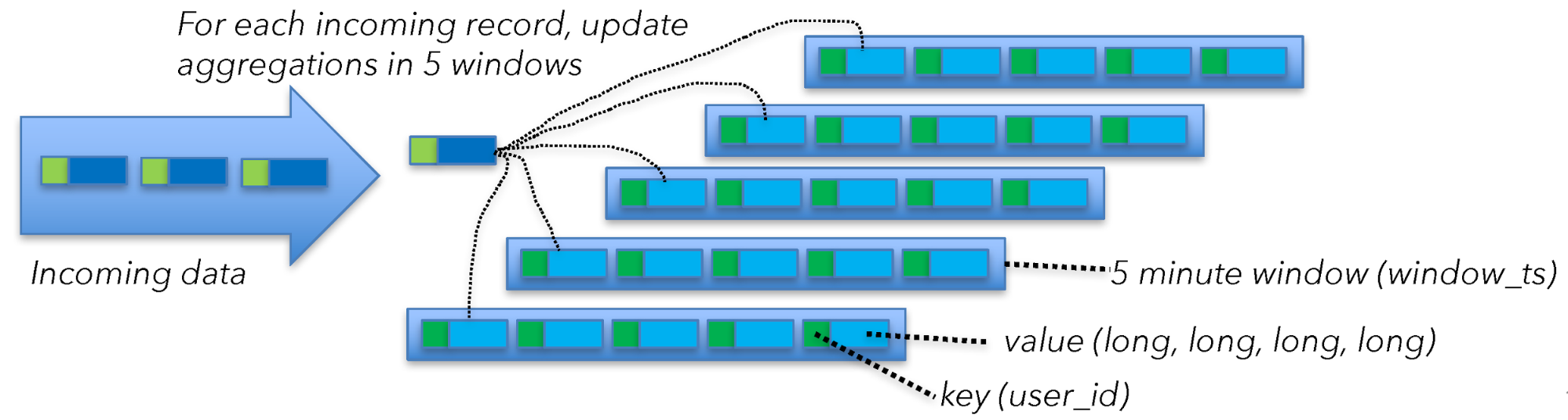
这意味着:
40 bytes of state x 5 windows x 200,000 msg/s per machine = 40 MB/s
…每台机器的读或写磁盘访问。 正如开头所说,磁盘是网络连接的,所以我需要将这些数字添加到整体吞吐量计算中。
现在的总数是:
- 数据输入:760 MB/s(400 MB/s 数据输入 + 320 MB/s shuffle + 40 MB/s 状态)
- 数据输出:427 MB/s(320 MB/s shuffle + 67 MB/s 数据输出 + 40 MB/s 状态)

上述注意事项是针对状态访问的,当新事件到达窗口算子时,会一直出现状态访问。 你还可以为容错启用 Checkpoint。 如果机器或其他任何地方出现故障,你需要恢复窗口内容并继续处理。
Checkpoint 设置为每分钟一个 Checkpoint 的间隔,每个 Checkpoint 将作业的整个状态复制到网络附加文件系统中。
让我们快速看看每台机器上的整个状态有多大:
40 bytes of state x 5 windows x 100,000,000 keys = 20 GB/min
并且,要获得每秒值:
20 GB/min ÷ 60 = 333 MB/s
与窗口操算子类似,Checkpoint 具有突发模式,并且每分钟一次,它尝试将其数据全速发送到外部存储。 Checkpoint 会导致对 RocksDB 的额外状态访问(在此示例中位于网络连接的磁盘上)。 从 Flink 1.3 开始,RocksDB 状态后端支持增量检查点,从概念上讲,仅发送自上一个 Checkpoint 以来的“差异”来减少每个 Checkpoint 所需的网络传输,但此示例未使用此功能。
这会将总计更新为:- 数据输入:760 MB/s (400 + 320 + 40)
- 数据输出:760 MB/s (320 + 67 + 40 + 333)

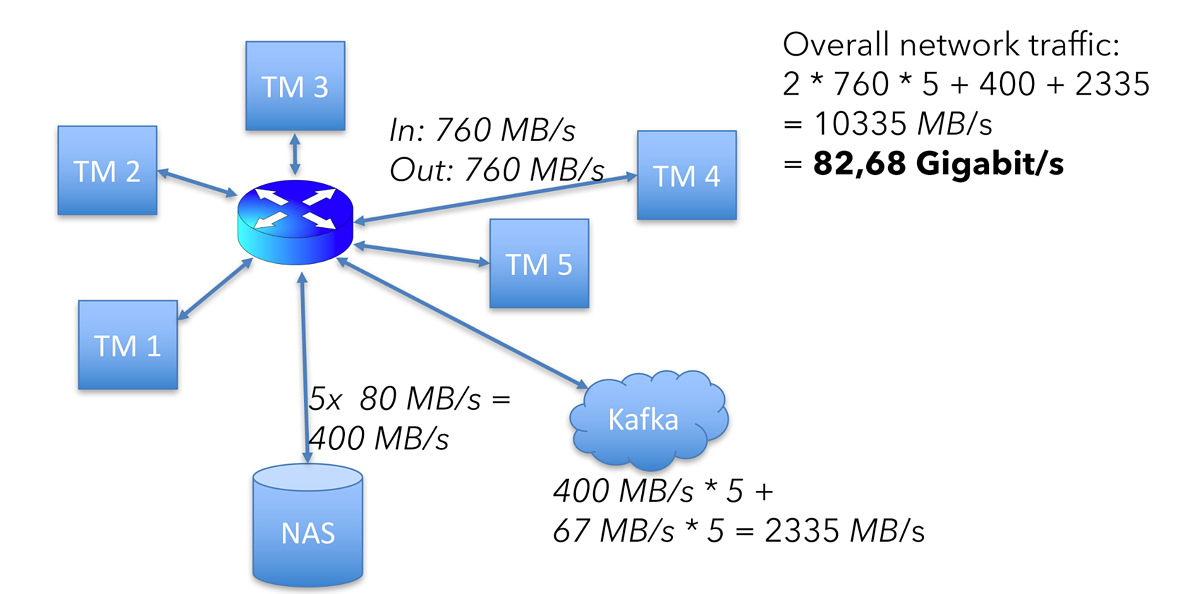
这意味着整体网络流量为:
(760 + 760 + 40 + 40 + 400 + 67) x 5 = 10335 MB/s
400 是跨 5 台机器的 80 MB 状态访问(读取和写入)进程的总数,2335 是整个集群的 Kafka 进出进程的总数。
译者注:
- 数据输入:760 MB/s
- 数据输出:760 MB/s
- 状态写入:40 MB/s
- 读取写入:40 MB/s
- Kafka 输入:400 MB/s
- Kafka 输出:67 MB/s
或者只是上述硬件设置中可用网络容量的一半以上。
我想添加一个免责声明。 这些计算都不包括协议开销,例如来自 Flink、Kafka 或文件系统的 TCP、以太网和 RPC 调用。 这仍然是了解你需要什么样的硬件来完成工作并了解性能的良好起点。
Scale 的方法
根据我的分析,此示例具有 5 节点集群,在典型操作中,每台机器需要处理 760 MB/s 的数据,包括输入和输出,总容量为 1250 MB/s。 这为我所掩盖的复杂性保留了大约 40% 的网络容量,例如网络协议开销、从 Checkpoint 恢复时事件重放期间的重负载以及由数据倾斜导致的集群间负载不均衡。
对于 40% 是否是适当的动态余量,没有一个通用的答案,但这个算法应该给你一个很好的起点。 尝试上面的计算,更换机器数量、key 数量或每秒消息数,以便选择要考虑的值,然后将其与你的预算和算子因素进行平衡。 快乐缩放!
翻译How To Size Your Apache Flink® Cluster: A Back-of-the-Envelope Calculation

若有收获,就点个赞吧
0 人点赞
