kNN.py
改进约会网站配对效果:
k-近邻算法
def classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]diffMat = np.tile(inX, (dataSetSize, 1)) - dataSetsqDiffMat = diffMat**2sqDistances = sqDiffMat.sum(axis=1)distances = sqDistances**0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)return sortedClassCount[0][0]
Tile函数:
tile函数位于python模块 numpy.lib.shape_base中,他的功能是重复某个数组。比如tile(A,n),功能是将数组A重复n次,构成一个新的数组
>>> import numpy>>> numpy.tile([0,0],5)#在列方向上重复[0,0]5次,默认行1次array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])>>> numpy.tile([0,0],(1,1))#在列方向上重复[0,0]1次,行1次array([[0, 0]])>>> numpy.tile([0,0],(2,1))#在列方向上重复[0,0]1次,行2次array([[0, 0],[0, 0]])>>> numpy.tile([0,0],(3,1))array([[0, 0],[0, 0],[0, 0]])>>> numpy.tile([0,0],(1,3))#在列方向上重复[0,0]3次,行1次array([[0, 0, 0, 0, 0, 0]])>>> numpy.tile([0,0],(2,3))<span style="font-family: Arial, Helvetica, sans-serif;">#在列方向上重复[0,0]3次,行2次</span>array([[0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0]])
python中的sum函数.sum(axis=1)
浅述python中argsort()函数的用法
operator模块提供的itemgetter函数主要用于获取某一对象 特定维度的数据,其中的参数为特定维度的序号,看下面的例子吧:
>>> a=[1,2,3,4]>>> b=operator.itemgetter(1) #获取下标为1的元素>>> b(a)2>>> b=operator.itemgetter(1,0) #获取下标为1和0的元素>>> b(a)(2,1)
python更改当前工作路径
将文本记录转为Numpy的解析程序:
def file2matrix(filename):love_dictionary = {'largeDoses':3, 'smallDoses':2, 'didntLike':1}fr = open(filename)arrayOLines = fr.readlines()numberOfLines = len(arrayOLines) #get the number of lines in the filereturnMat = np.zeros((numberOfLines, 3)) #prepare matrix to returnclassLabelVector = [] #prepare labels returnindex = 0for line in arrayOLines:line = line.strip()listFromLine = line.split('\t')returnMat[index, :] = listFromLine[0:3]if(listFromLine[-1].isdigit()):classLabelVector.append(int(listFromLine[-1]))else:classLabelVector.append(love_dictionary.get(listFromLine[-1]))index += 1return returnMat, classLabelVector
python numpy.zeros()函数的用法
在 Python 中字符串处理函数里有三个去空格(包括 ‘\n’, ‘\r’, ‘\t’, ’ ‘) 的函数:
- strip 同时去掉左右两边的空格
- lstrip 去掉左边的空格
- rstrip 去掉右边的空格
matplotlib.pyplot中add_subplot方法参数111的含义
归一化特征值:
newValue = (oldValue - min)/(max - min)
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = np.zeros(np.shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - np.tile(minVals, (m, 1))normDataSet = normDataSet/np.tile(ranges, (m, 1)) #element wise dividereturn normDataSet, ranges, minVals
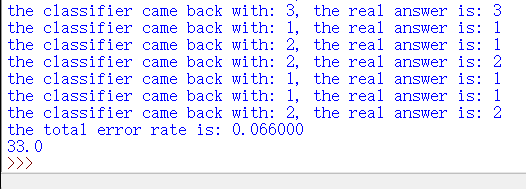
分类器针对约会网站的测试代码:
def datingClassTest():hoRatio = 0.50 #hold out 10%datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom filenormMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(m*hoRatio)errorCount = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))if (classifierResult != datingLabels[i]): errorCount += 1.0print("the total error rate is: %f" % (errorCount / float(numTestVecs)))print(errorCount)
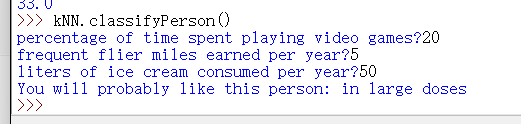
约会网站预测函数:
def classifyPerson():resultList = ['not at all', 'in small doses', 'in large doses']percentTats = float(input(\"percentage of time spent playing video games?"))ffMiles = float(input("frequent flier miles earned per year?"))iceCream = float(input("liters of ice cream consumed per year?"))datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')normMat, ranges, minVals = autoNorm(datingDataMat)inArr = np.array([ffMiles, percentTats, iceCream, ])classifierResult = classify0((inArr - \minVals)/ranges, normMat, datingLabels, 3)print("You will probably like this person: %s" % resultList[classifierResult - 1])
手写识别系统:
def img2vector(filename):returnVect = np.zeros((1, 1024))fr = open(filename)for i in range(32):lineStr = fr.readline()for j in range(32):returnVect[0, 32*i+j] = int(lineStr[j])return returnVect
自包含函数?
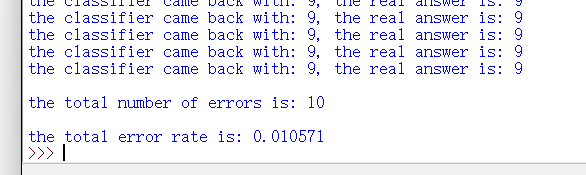
手写数字识别系统的测试代码:
def handwritingClassTest():hwLabels = []trainingFileList = listdir('trainingDigits') #load the training setm = len(trainingFileList)trainingMat = np.zeros((m, 1024))for i in range(m):fileNameStr = trainingFileList[i]fileStr = fileNameStr.split('.')[0] #take off .txtclassNumStr = int(fileStr.split('_')[0])hwLabels.append(classNumStr)trainingMat[i, :] = img2vector('trainingDigits/%s' % fileNameStr)testFileList = listdir('testDigits') #iterate through the test seterrorCount = 0.0mTest = len(testFileList)for i in range(mTest):fileNameStr = testFileList[i]fileStr = fileNameStr.split('.')[0] #take off .txtclassNumStr = int(fileStr.split('_')[0])vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))if (classifierResult != classNumStr): errorCount += 1.0print("\nthe total number of errors is: %d" % errorCount)print("\nthe total error rate is: %f" % (errorCount/float(mTest)))

若有收获,就点个赞吧
0 人点赞
