kMeans.py
无监督学习:聚类
K-均值聚类算法
from numpy import *def loadDataSet(fileName): #general function to parse tab -delimited floatsdataMat = [] #assume last column is target valuefr = open(fileName)for line in fr.readlines():curLine = line.strip().split('\t')fltLine = list(map(float,curLine)) #map all elements to float()dataMat.append(fltLine)return dataMatdef distEclud(vecA, vecB):return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)def randCent(dataSet, k):n = shape(dataSet)[1]centroids = mat(zeros((k,n)))#create centroid matfor j in range(n):#create random cluster centers, within bounds of each dimensionminJ = min(dataSet[:,j])rangeJ = float(max(dataSet[:,j]) - minJ)centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))return centroids
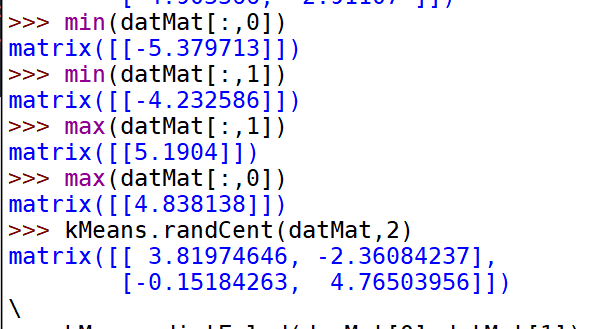

def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):m = shape(dataSet)[0]clusterAssment = mat(zeros((m,2)))#create mat to assign data points#to a centroid, also holds SE of each pointcentroids = createCent(dataSet, k)clusterChanged = Truewhile clusterChanged:clusterChanged = Falsefor i in range(m):#for each data point assign it to the closest centroidminDist = inf; minIndex = -1for j in range(k):distJI = distMeas(centroids[j,:],dataSet[i,:])if distJI < minDist:minDist = distJI; minIndex = jif clusterAssment[i,0] != minIndex: clusterChanged = TrueclusterAssment[i,:] = minIndex,minDist**2print(centroids)for cent in range(k):#recalculate centroidsptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this clustercentroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to meanreturn centroids, clusterAssment
后处理提高聚类性能
二分K-均值算法
def biKmeans(dataSet, k, distMeas=distEclud):m = shape(dataSet)[0]clusterAssment = mat(zeros((m,2)))centroid0 = mean(dataSet, axis=0).tolist()[0]centList =[centroid0] #create a list with one centroidfor j in range(m):#calc initial ErrorclusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2while (len(centList) < k):lowestSSE = inffor i in range(len(centList)):ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#get the data points currently in cluster icentroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)sseSplit = sum(splitClustAss[:,1])#compare the SSE to the currrent minimumsseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])print("sseSplit, and notSplit: ",sseSplit,sseNotSplit)if (sseSplit + sseNotSplit) < lowestSSE:bestCentToSplit = ibestNewCents = centroidMatbestClustAss = splitClustAss.copy()lowestSSE = sseSplit + sseNotSplitbestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whateverbestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplitprint('the bestCentToSplit is: ',bestCentToSplit)print('the len of bestClustAss is: ', len(bestClustAss))centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroidscentList.append(bestNewCents[1,:].tolist()[0])clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSEreturn mat(centList), clusterAssment
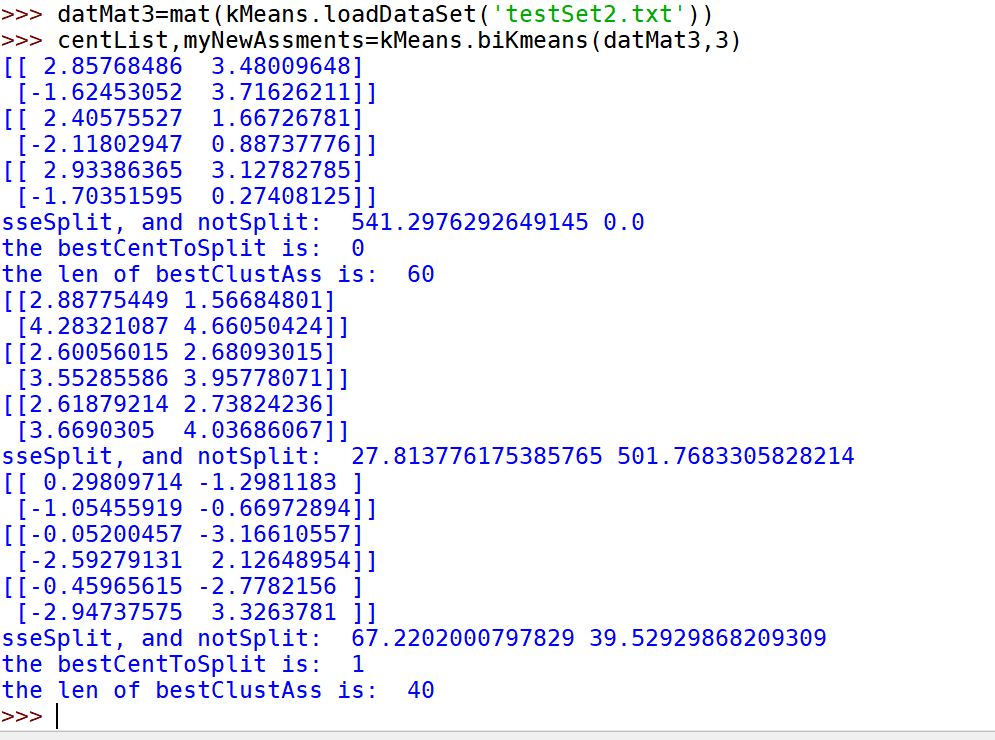
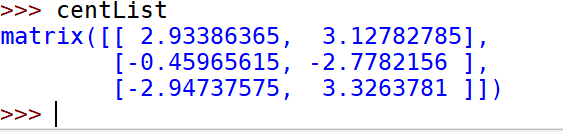
示例:对地图上的点进行聚类

若有收获,就点个赞吧
0 人点赞
